3 属性データ操作
必須パッケージ
- この章では、以下のパッケージがインストールされ、ロードされている必要がある。
library(sf) # Chapter 2 で紹介したベクタデータパッケージ
#> Warning: package 'sf' was built under R version 4.3.3
library(terra) # Chapter 2 で紹介したラスタデータパッケージ
#> Warning: package 'terra' was built under R version 4.3.3
library(dplyr) # データフレーム操作用 tidyverseパッケージ- この章は spData に依存している。コード例で使用されるデータセットをロードする。
library(spData) # Chapter 2 で紹介した空間データパッケージ
#> Warning: package 'spData' was built under R version 4.3.3- また、Section 3.2.5 でデータの「整頓 (tidy)」操作を実行したい場合は、tidyr パッケージ、またはその一部である tidyverse がインストールされていることを確認しておこう。
3.1 イントロダクション
属性データとは、地理 (ジオメトリ) データに関連する空間以外の情報である。
バス停を例にとると、その位置は通常、名称に加えて緯度・経度の座標 (ジオメトリデータ) で表現される。
例えば、London の Elephant & Castle / New Kent Road の停留所の座標は、経度 \(-0.098\) 度、緯度 51.495 度で、Chapter 2 で説明した sfc の表現では POINT (-0.098 51.495) と表すことができる。
この章のトピックは、POINT フィーチャの属性のうち、name のような名称の属性 (シンプルフィーチャの用語を使用する) である。
また、ラスタデータにおける特定のグリッドセルの標高値 (属性) もその一例である。 ラスタデータモデルは、ベクタデータモデルと異なり、グリッドセルの座標を間接的に格納するため、属性情報と空間情報の区別が明確ではない。 ラスタ行列の 3 行 4 列目の画素を考えてみよう。 その空間的な位置は、行列内のインデックスで定義される。原点から x 方向に 4 セル (地図上では通常東と右)、y 方向に 3 セル (通常南と下) 移動させる。 ラスタの解像度は、ヘッダで指定された各 x ステップと y ステップの距離を定義する。 ヘッダはラスタデータセットの重要な構成要素で、ピクセルと空間座標の関係を指定する (Chapter 4 も参照)。
本章は、ベクタデータセットではバス停の名前、ラスタデータセットではピクセルの標高といった属性に基づいて地理的なオブジェクトを操作する方法を解説する。
ベクタデータの場合は、部分集合 (subset) や属性集計 (aggregate) といった手法になる (Section 3.2.1 から Section 3.2.3 を参照)。
また、Section 3.2.4 では、共有 ID を用いてデータをシンプルフィーチャに結合する方法、Section 3.2.5 では、新しい変数の作成方法を説明している。
これらの操作には、それぞれ空間的な等価性がある。
例えば、R の [ 演算子は、属性に基づくオブジェクトの部分集合と空間オブジェクトの部分集合に同じように機能する。また、空間結合を使用して 2 つの地理データセットの属性を結合することもできる。
この章で学ぶスキルは他にも応用可能である。
次のセクションでは、さまざまなベクタ属性操作を深く掘り下げた後、ラスタ属性データ操作を Section 3.3 でカバーする。 ラスタについては、連続およびカテゴリ属性を含むラスタレイヤの作成方法と、1 つまたは複数のレイヤからセル値を抽出する (ラスタ部分集合化) 方法を示す (Section 3.3.1)。 Section 3.3.2 は、ラスタデータセット全体を要約するために使用できる「グローバル」ラスタ操作の概要を提供する。 Chapter 4 は、ここで紹介した方法を空間的な世界に拡張するものである。
3.2 ベクタ属性操作
地理ベクタデータセットは、R の基本クラスの data.frame を拡張した sf クラスにより対応されている。
sf オブジェクトはデータフレームのように、属性変数 (’name’など) ごとに 1 列、観察または フィーチャ (たとえば、バス停ごと) ごとに 1 行を持つ。
sf オブジェクトは基本的なデータフレームとは異なり、sfc クラス の geometry 列を持ち、1 行にさまざまな地理的実体 (「複合でない」および「複合」点、線、ポリゴン) を含むことができる。
Chapter 2 では、plot() や summary() などのジェネリック関数が sf オブジェクトでどのように動作するかを示した。
sf はまた、sf オブジェクトが通常のデータフレームのように動作することを可能にするジェネリック関数を提供する。sf に対応するジェネリック関数は、以下で確認できる。
methods(class = "sf") # sf オブジェクトのメソッド、最初の 12
#> [1] [ [[<- $<- aggregate
#> [5] as.data.frame cbind coerce filter
#> [9] identify initialize merge plot これらの多く (aggregate()、cbind()、merge()、rbind()、[) は、データフレームを操作するためのものである。
例えば、rbind() は、2 つのデータフレームの行を「上下に」結合する。
$<- は、新しい列を作成する。
sf オブジェクトの大きな特徴は、空間データと非空間データを同じように、data.frame の列として格納することである。
sf オブジェクトのジオメトリ列は、通常 geometry または geom と呼ばれるが、任意の名前を使用することができる。
例えば、次のコマンドは g という名前のジオメトリ列を作成する。
st_sf(data.frame(n = world$name_long), g = world$geom)
wkb_geometry や the_geom などのさまざまな名前を付けることができるようになる。
sf オブジェクトは、データフレーム用の tidyverse クラスである tbl_df と tbl を拡張することもできる。
このように sf は、データ解析に基本的な R や tidyverse 関数を使用するなど、R のデータ解析能力の全力を地理データに対して発揮することを可能にする。
高性能データ処理パッケージ data.table も sf オブジェクトを処理できるが、issue Rdatatable/data.table#2273 で説明されているように、完全に互換ではない。
これらの機能を使用する前に、ベクタデータオブジェクトの基本的なプロパティを発見する方法をもう一度おさらいしておくとよいだろう。
まずは R の基本関数を使って、spData パッケージの world データセットについて学習してみよう。
class(world) # sf オブジェクトであり、(tidy) データフレームである
#> [1] "sf" "tbl_df" "tbl" "data.frame"
dim(world) # 2次元オブジェクトで、 177 行 11 列
#> [1] 177 11
world は、10 個の地理とは関係ない列 (および 1 個のジオメトリリスト列) と、世界の国々を表す約 200 個の行を含んでいる。
関数 st_drop_geometry() は、sf オブジェクトの属性データのみを保持し、ジオメトリを削除する。
world_df = st_drop_geometry(world)
class(world_df)
#> [1] "tbl_df" "tbl" "data.frame"
ncol(world_df)
#> [1] 10属性データを扱う前にジオメトリ列を削除すると便利である。属性データのみを扱いジオメトリ列は必ずしも必要ではない場合、データ操作のプロセスが速く実行できるからである。
しかし、ほとんどの場合、ジオメトリ列を残すことは理にかなっている。ジオメトリ列が「スティッキー」 (意図的に削除しない限り、ほとんどの属性操作後も残っている) である理由となる。
sf オブジェクトに対する非空間データ操作は、適切な場合にのみオブジェクトのジオメトリを変更する (例: 集計後に隣接するポリゴン間の境界をディゾルブする)。
地理的属性データの操作に習熟するということは、データフレームの操作に習熟するということである。
多くのアプリケーションにおいて、tidyverse のパッケージ dplyr (Wickham et al. 2023) は、データフレームを扱うための効果的なアプローチを提供する。
tidyverse との互換性は、前身の sp になかった sf の利点であるが、落とし穴もあるのでハマることもある (詳しくは geocompx.org の補足 tidyverse-pitfalls vignetteを参照)。
3.2.1 ベクタ属性の部分集合
R の基本的な部分集合 (subset) の作成方法には、演算子 [ と関数 subset() がある。
dplyr の関数では、行の部分集合作成には filter() と slice() があり、列の部分集合作成には select() がある。
どちらのアプローチも sf オブジェクトの属性データの空間成分を保持する。一方、演算子 $ や dplyr 関数 pull() を使って単一の属性列をベクトルとして返すと、これから説明するようにジオメトリデータが失われる。
このセクションでは、sf データフレームの部分集合作成に焦点を当てている。ベクトルや非地理データフレームの部分集合に関する詳細については、An Introduction to R (R Core Team 2021) の Section 2.7 と Advanced R Programming (Wickham 2019) の Chapter 4 を勧める。
[ 演算子は、行と列の両方から部分集合を作成 (抽出) することができる。
データフレームオブジェクト名の直後の角括弧内に置かれたインデックスは、保持する要素を指定する。
コマンド object[i, j] は、「i で表される行と、j で表される列を返す」という意味である。i と j は通常、整数か TRUE と FALSE を含む (インデックスは、行や列名を示す文字列でもかまいない)。
例えば、object[5, 1:3] は、「5 行目と 1 列目から 3 列目を含むデータを返す: 結果は 1 行目と 3 列目だけのデータフレームで、sf オブジェクトの場合は 4 番目のジオメトリ列も含めなさい」という意味である。
i または j を空白にすると、すべての行または列が返される。 world[1:5, ] は最初の 5 行と 11 列すべてを返す。
以下の例は、Base R による部分集合の作成を示している。
各コマンドが返す sf データフレームの行と列の数を推測し、自分のコンピュータで結果を確認してみよう (他の演習課題はこの章の最後を参照)。
world[1:6, ] # 位置で行を抽出
world[, 1:3] # 位置で列を抽出
world[1:6, 1:3] # 位置で行と列を抽出
world[, c("name_long", "pop")] # 名称で列を抽出
world[, c(T, T, F, F, F, F, F, T, T, F, F)] # 論理値で抽出
world[, 888] # 存在しない列番号以下のコードチャンクでは、部分集合に logical ベクトルを使用することの有用性を示す。
これにより、表面積が 10,000 km2 より小さい国を含む新しいオブジェクト small_countries が作成される。
i_small = world$area_km2 < 10000
summary(i_small) # 論理ベクトル
#> Mode FALSE TRUE
#> logical 170 7
small_countries = world[i_small, ]中間値 i_small (小国を表すインデックスの略) は、world の面積の小さい 7 カ国の部分集合を作成するのに使う論理ベクトルである。
中間オブジェクトを省略したより簡潔なコマンドでも、同じ結果が得られる。
small_countries = world[world$area_km2 < 10000, ]Base R 関数 subset() でも、同じ結果を得ることができる。
small_countries = subset(world, area_km2 < 10000)
Base R 関数は成熟し安定しており、また広く使用されているため、特に再現性と信頼性が重要視される文脈では確実な選択肢となる。
一方、dplyr の関数は、特に RStudio のような列名の自動補完 を可能にするコードエディタと組み合わせたとき「tidy な」ワークフローを可能にする。一部の人々 (本書の著者も含む) は、こちらの方が対話式データ分析であり、直観的で生産的だと感じる。
データフレームの部分集合化する主要な関数 (sf データフレームを含む) を dplyr 関数で以下に示す。
select() は、名前または位置によって列を選択する。
例えば、次のコマンドで、name_long と pop の 2 つの列だけを選択することができる。
注: Base R 関数での同等のコマンド (world [, c("name_long", "pop")]) と同様に、スティッキーな geom 列が残る。
select() は、: 演算子の助けを借りて、列の範囲を選択することもできる。
# name_long から pop までの全ての列
world2 = select(world, name_long:pop)- 演算子で特定の列を削除することができる。
# subregion と area_km2 以外全ての列
world3 = select(world, -subregion, -area_km2)new_name = old_name 構文で、列の部分集合と名前の変更を同時に行うことができる。
world4 = select(world, name_long, population = pop)上記のコマンドは、2 行のコードを必要とする Base R 関数のコードよりも簡潔であることは注目に値する。
world5 = world[, c("name_long", "pop")] # 名称で列を抽出
names(world5)[names(world5) == "pop"] = "population" # 列めいを変更select() は、contains()、starts_with()、num_range() など、より高度な部分集合操作のための「ヘルパー関数」とも連動する (詳しくは ?select のヘルプページを参照)。
ほとんどの dplyr 動詞はデータフレームを返すが、pull() で単一の列をベクトルとして抽出することができる。
Base R でリスト部分集合演算子 $ と [[ を使っても同じ結果が得られる。以下の 3 つのコマンドは、同じ数値ベクトルを返す。
pull(world, pop)
world$pop
world[["pop"]]slice() は、行に対して select() と同様のことを行う。
例えば、次のコードチャンクは、1 行目から 6 行目までを選択する。
slice(world, 1:6)filter() は、Base R の subset() 関数に相当する dplyr の関数である。
例えば、面積がある閾値以下の国、平均寿命が高い国など、与えられた基準に合致する行のみを保持する。
Table 3.1 に示すように、標準的な比較演算子のセットは、filter() 関数で使用することができる。
| Symbol | Name |
|---|---|
== |
等号 |
!= |
不等号 |
>, <
|
より大きい・小さい |
>=, <=
|
以上・以下 |
&, |, !
|
論理学のかつ、または、ではない |
3.2.2 パイプを使ったコマンドの連鎖
dplyr 関数を使用するワークフローの鍵は、パイプ 演算子 %>% (R 4.1.0 以降では ネイティブパイプ |>) で、これは Unix パイプ | (Grolemund and Wickham 2016) から名前を取ったものである。
パイプは、直前の関数の出力が次の関数の第 1 引数になるため、表現力豊かなコードを実現する。
これは、world データセットからアジアの国だけがフィルタされ、次にオブジェクトが列 (name_long と continent) と最初の 5 行の部分集合にされる様子を示している (結果は示していない)。
上のチャンクは、パイプ演算子によって、コマンドを明確な順序で記述できることを示している。 上記を上から下へ (一行ずつ)、左から右へ実行する。 パイプによる操作の代わりに、ネストされた関数呼び出しがあるが、これは読みにくい。
別の方法として、操作を複数の行に分割する方法もある。この方法は、中間結果を明確な名前で保存し、後でデバッグのために検査することができるという利点がある (この方法は、冗長になり、対話型解析を行う際にグローバル環境が煩雑になるという欠点もある)。
world9_filtered = filter(world, continent == "Asia")
world9_selected = select(world9_filtered, continent)
world9 = slice(world9_selected, 1:5)それぞれのアプローチには利点と欠点があり、プログラミングスタイルやアプリケーションによってその重要性は異なる。 本章の焦点である対話的なデータ解析では、特にRStudio/VSCodeのパイプを作成するためのショートカットや変数名自動補完と組み合わせた場合に、パイプによる操作が高速で直感的であることがわかる。
3.2.3 ベクタ属性集計
集計では、1 つ以上の「グループ化変数」、通常は集計対象のデータフレームの列からデータを要約する (地理的集計は次の章で扱う)。
属性集約の例として、国レベルのデータから大陸ごとの人口を計算する (1 国につき 1 行)。
world データセットには、必要な要素が含まれている: pop 列と continent 列、それぞれ人口とグループ化変数である。
目的は、各大陸の国別人口の sum() を見つけ、より小さなデータフレームにすることである (集約はデータ削減の一形態であり、大規模データセットを扱う際の初期段階として有効)。
これは、R の基本関数 aggregate()で、次のように行うことができる。
world_agg1 = aggregate(pop ~ continent, FUN = sum, data = world,
na.rm = TRUE)
class(world_agg1)
#> [1] "data.frame"結果は、各大陸につき 1 行の計 6 行と、各大陸の名前と人口を示す 2 列の非空間データフレームになる (人口の多い上位 3 大陸の結果は Table 3.2 を参照)。
aggregate() は、ジェネリック関数である。ジェネリック関数とは、入力によって異なる動作をすることを意味している。
sf は、aggregate.sf() というメソッドを提供している。これによって、aggregate() 関数の引数x に sf オブジェクトを与え、さらに by の引数が与えられたとき、自動的に aggregate.sf() が呼ばれる。
world_agg2 = aggregate(world["pop"], by = list(world$continent), FUN = sum,
na.rm = TRUE)
class(world_agg2)
#> [1] "sf" "data.frame"
nrow(world_agg2)
#> [1] 8結果として world_agg2 オブジェクトは、世界の大陸 (および外洋) を表す 8 つのフィーチャを含む空間オブジェクトとなる。
group_by() |> summarize() は aggregate() の dplyr 版である。
グループ化する変数は group_by() 関数で指定し、集約式は summarize() 関数に渡す。コード例は以下の通り。
この方法はより複雑に見えるだろうが、柔軟性、読みやすさ、新しい列名の制御という利点がある。 この柔軟性を示すのが、人口だけでなく、各大陸の面積や国数を計算する以下のコマンドである。
world_agg4 = world |>
group_by(continent) |>
summarize(Pop = sum(pop, na.rm = TRUE), Area = sum(area_km2), N = n())上のコードチャンクで、pop、area_sqkm、n は結果の列名で、sum()、n() は集計関数である。
これらの集約関数は、大陸を表す行と、各大陸と関連する島を表す複数のポリゴンを含むジオメトリを持つ sf オブジェクトを返す (これは、Section 5.2.7 で説明するように、ジオメトリ操作 ‘union’ によって機能する)。
これまで学んだ dplyr 関数を組み合わせて、複数のコマンドを連結し、世界の国々の属性データを大陸別にまとめてみよう。
次のコマンドは、人口密度を計算し (mutate())、大陸を含む国の数で並べ (arrange())、最も人口の多い 3 大陸だけを残し (slice_max())、その結果を Table 3.2 に表示する。
world_agg5 = world |>
st_drop_geometry() |> # 速くするためジオメトリを削除
select(pop, continent, area_km2) |> # 関心ある列のみの部分集合
group_by(Continent = continent) |> # 大陸でグループ化し要約
summarize(Pop = sum(pop, na.rm = TRUE), Area = sum(area_km2), N = n()) |>
mutate(Density = round(Pop / Area)) |> # 人口密度を計算
slice_max(Pop, n = 3) |> # 上位3件のみ
arrange(desc(N)) # 国数で並べ替え| Continent | Pop | Area | N | Density |
|---|---|---|---|---|
| Africa | 1154946633 | 29946198 | 51 | 39 |
| Asia | 4311408059 | 31252459 | 47 | 138 |
| Europe | 669036256 | 23065219 | 39 | 29 |
3.2.4 ベクタ属性の結合
異なるソースからのデータを組み合わせることは、データ作成において一般的な作業である。
結合は、共有された「キー」変数に基づいてテーブルを結合することによって行われる。
dplyr には、left_join() や inner_join() など、複数の結合関数がある。完全なリストは、vignette("two-table")を参照 (訳注: 日本語版)。
これらの関数名は、データベース言語 SQL (Grolemund and Wickham 2016, chap. 13) で使われている慣例に従っている。これらを使って、非空間データセットと sf オブジェクトを結合することが、このセクションの焦点である。
dplyr の join 関数は、データフレームと sf オブジェクトで同じように動作する。唯一の重要な違いは、geometry リスト列である。
データ結合の結果は、sf または data.frame オブジェクトのいずれかになる。
空間データに対する最も一般的な属性結合は、第1引数として sf オブジェクトを取り、第 2 引数として指定された data.frame から列を追加するものである。
結合を実証するために、コーヒー生産に関するデータを world のデータセットと結合する。
コーヒーのデータは spData パッケージの coffee_data というデータフレームに入っている (詳しくは ?coffee_data を参照)。
以下のように、3 列になっている。
name_long は主要なコーヒー生産国の名前、coffee_production_2016 と coffee_production_2017 は各年の 60 kg 袋単位のコーヒー生産量の推定値である。
最初のデータセットを保持する「左結合」で、world と coffee_data を結合する。
world_coffee = left_join(world, coffee_data)
#> Joining with `by = join_by(name_long)`
class(world_coffee)
#> [1] "sf" "tbl_df" "tbl" "data.frame"入力データセットが「キー変数」(name_long) を共有しているため、by 引数を使わなくても結合ができた (詳細は ?left_join を参照)。
その結果、sf オブジェクトは、元の world オブジェクトと同じであるが、コーヒー生産に関する 2 つの新しい変数 (列インデックス 11 と 12 を持つ) が追加される。
これは、以下の plot() 関数で生成される Figure 3.1 のように、地図としてプロットすることができる。
names(world_coffee)
#> [1] "iso_a2" "name_long" "continent"
#> [4] "region_un" "subregion" "type"
#> [7] "area_km2" "pop" "lifeExp"
#> [10] "gdpPercap" "geom" "coffee_production_2016"
#> [13] "coffee_production_2017"
plot(world_coffee["coffee_production_2017"])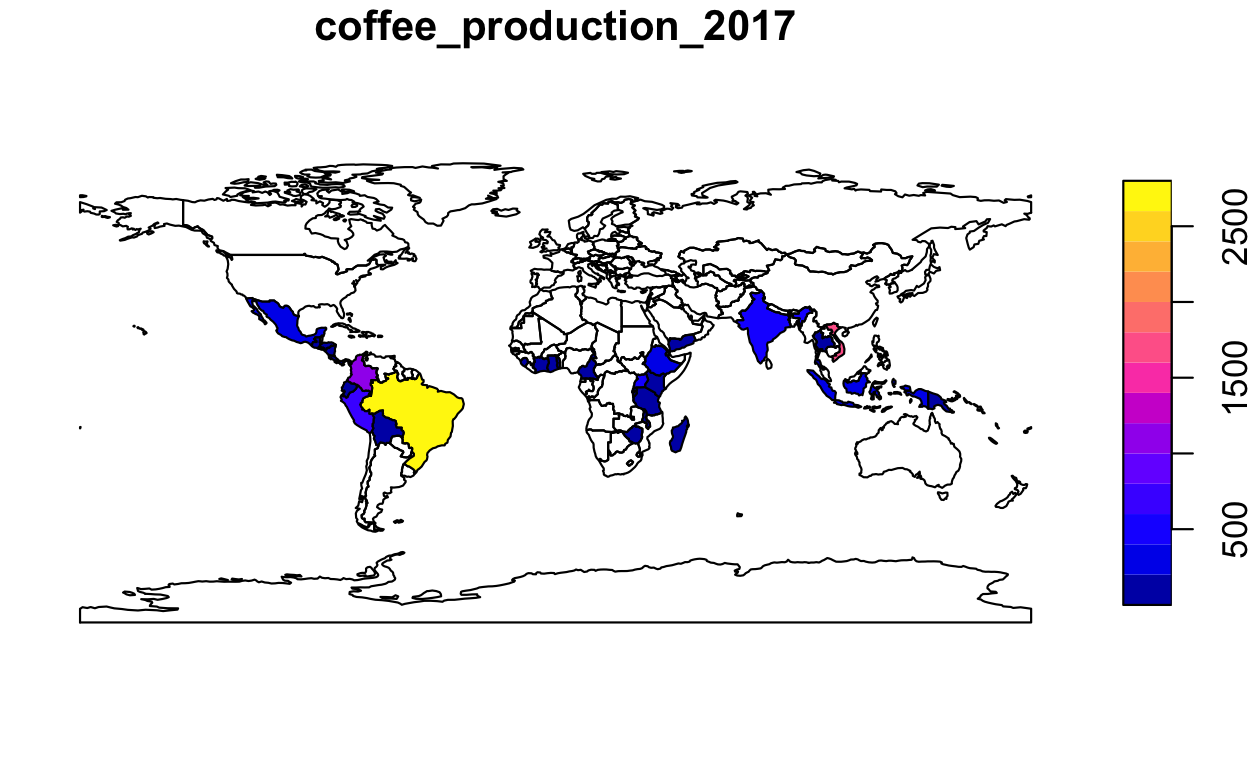
FIGURE 3.1: 世界の国別コーヒー生産量 (60 kg 袋千個)、2017年。出典: 国際コーヒー機関 国際コーヒー機関。
結合を行うには、両方のデータセットで「キー変数」が供給される必要がある。
デフォルトでは、dplyr は一致する名前のすべての変数を使用する。
この場合、coffee_data と world の両方のオブジェクトに name_long という変数が含まれており、Joining with 'by = join_by(name_long)' というメッセージを説明している。
変数名が同じでない場合、おおむね 2 つのオプションがある。
- どちらかのオブジェクトのキー変数の名前を変更し、一致するようにする。
-
by引数で結合変数を指定する。
後者の方法は、coffee_data の名前を変更したバージョンで以下に示す。
coffee_renamed = rename(coffee_data, nm = name_long)
world_coffee2 = left_join(world, coffee_renamed, by = join_by(name_long == nm))なお、元のオブジェクトの名前は保持され、world_coffee と新しいオブジェクト world_coffee2 は同一であることを意味する。
結果について、元のデータセットと同じ行数となる。
coffee_data には 47 行のデータしかないが、world_coffee と world_coffee2 には 177 の国別レコードがすべてそのまま保存されている。
これは、行が一致しない場合、新たなコーヒー生産量変数として NA の値を割り当てるためである。
キー変数が一致する国だけを残したい場合はどうすればいいのだろうか?
その場合、内部結合を使用することができる。
world_coffee_inner = inner_join(world, coffee_data)
#> Joining with `by = join_by(name_long)`
nrow(world_coffee_inner)
#> [1] 45coffee_data の結果が 47 行であるのに対し、inner_join() の結果は 45 行しかないことに注意しておこう。
残りの列はどうなったのだろうか?
一致しなかった行は、setdiff() 関数を用いて、以下のように特定することができる。
setdiff(coffee_data$name_long, world$name_long)
#> [1] "Congo, Dem. Rep. of" "Others"その結果、Others が world のデータセットに存在しない 1 行を占め、Democratic Republic of the Congo の名前がもう 1 行を占めることがわかった。
が省略され、結合が見落とされている。
次のコマンドは、stringr パッケージの文字列照合 (regex) 関数を使用して、Congo, Dem. Rep. of がどうあるべきかを確認するものである。
drc = stringr::str_subset(world$name_long, "Dem*.+Congo")
drc
#> [1] "Democratic Republic of the Congo"この問題を解決するために、coffee_data の新バージョンを作成し、名前を更新する。
inner_join() を更新すると、コーヒー生産国全 46 カ国を含む結果が返される。
coffee_data$name_long[grepl("Congo,", coffee_data$name_long)] = drc
world_coffee_match = inner_join(world, coffee_data)
#> Joining with `by = join_by(name_long)`
nrow(world_coffee_match)
#> [1] 46また、非空間データセットから始めて、シンプルフィーチャオブジェクトから変数を追加するという、逆方向の結合も可能である。
これは、coffee_data オブジェクトから始まり、オリジナルの world データセットから変数を追加するもので、以下のように示される。
前の結合とは対照的に、結果はシンプルフィーチャオブジェクトではなく、tidyverse の tibble という形のデータフレームになる。
join の出力はその最初の引数に一致する傾向がある。
coffee_world = left_join(coffee_data, world)
#> Joining with `by = join_by(name_long)`
class(coffee_world)
#> [1] "tbl_df" "tbl" "data.frame"sf オブジェクトにのみ有効である。
ジオメトリ列は、R が空間オブジェクトであることを認識し、 sf などの空間パッケージで定義されている場合にのみ、マップや空間処理を作成するために使用することができる。
幸いなことに、ジオメトリ列を持つ非空間データフレーム (coffee_world など) は、以下のように sf オブジェクトに強制的に格納することができる。st_as_sf(coffee_world)
ここでは、属性結合のほとんどのケースをカバーした。 より詳しくは、Grolemund and Wickham (2016) の Relational data の章、本書に付属する geocompkg パッケージの join vignette 、および data.table などのパッケージによる結合を説明したドキュメントを読むことを勧める。 さらに、空間結合については次の章で説明する (Section 4.2.5)。
3.2.5 属性の作成と空間情報の削除
既にある列を元に新しい列を作りたい場合はよくある。
例えば、各国の人口密度を計算したい。
そのためには、人口列 (ここでは pop) を面積列 (ここでは area_km2) (単位面積は平方キロメートル) で割る必要がある。
Base R を使って、以下のように書いてみよう。
world_new = world # 元データを上書きしない
world_new$pop_dens = world_new$pop / world_new$area_km2
あるいは、dplyr の関数である mutate() または transmute() を使うこともできる。
mutate() は、sf オブジェクトの最後から 2 番目の位置に新しい列を追加する (最後の列はジオメトリ用に予約されている)。
world_new2 = world |>
mutate(pop_dens = pop / area_km2)mutate() と transmute() の違いは、後者が他の既存の列をすべて削除することである (スティッキーなジオメトリ列を除く)。
tidyr パッケージ (pivot_longer() を始め、データセットを再形成するための多くの便利な関数を提供する) の unite() は、既存の列を貼り合わせる。
例えば、continent と region_un の列を結合して、con_reg という新しい列を作成したい。
さらに、入力列の値をどのように結合するかを定義するセパレータ (ここでは、コロン :)、および元の列を削除するかどうか (ここでは、TRUE) を定義することができる。
world_unite = world |>
tidyr::unite("con_reg", continent:region_un, sep = ":", remove = TRUE)ここでできた sf オブジェクトは、各国の大陸と地域を表す con_reg という新しい列を持ち、例えば、アルゼンチンやその他の南米諸国は South America:Americas となる。
tidyr の separate() 関数は unite() の逆を行う: 正規表現か文字位置のどちらかを使って 1 つの列を複数の列に分割する。
列の名前を変更するには、dplyr 関数 rename() と基本関数 setNames() が便利である。
1 つ目は、古い名前を新しい名前に置き換えるものである。
例えば、次のコマンドは、長い name_long 列の名前を、単に name に変更する。
world |>
rename(name = name_long)
setNames() はすべての列の名前を一度に変更し、各列にマッチする名前を持つ文字ベクタを必要とする。
これは下図に示すように、同じ world オブジェクトを出力しているが、非常に短い名前になっている。
new_names = c("i", "n", "c", "r", "s", "t", "a", "p", "l", "gP", "geom")
world_new_names = world |>
setNames(new_names)
これらの属性データ操作は、いずれもシンプルフィーチャの形状を保持するものである。
集計を高速化するためなど、ジオメトリを削除することが理にかなっている場合もある。
select(world, -geom) などのコマンドで手動で行うのではなく、st_drop_geometry() で行ってみよう。
20
world_data = world |> st_drop_geometry()
class(world_data)
#> [1] "tbl_df" "tbl" "data.frame"3.3 ラスタオブジェクトを操作
シンプルフィーチャであるベクタデータ (点、線、ポリゴンを空間上の離散的な実体として表現する) とは対照的に、ラスタデータは連続的な面を表現する。 このセクションでは、ラスタオブジェクトの動作を、Section ?? を基にゼロから作成することによって説明する。 ラスタデータセットはユニークな構造のため、Section 3.3.1 で示すように、部分集合の作成やその他の操作は異なる。
次のコードは、Section 2.3.4 で使用したラスタデータセットを再作成し、その結果を Figure 3.2 に示している。
これは、elev (標高を表す) という名前のラスタの例を作成するために、rast() 関数がどのように動作するかを示している。
elev = rast(nrows = 6, ncols = 6, resolution = 0.5,
xmin = -1.5, xmax = 1.5, ymin = -1.5, ymax = 1.5,
vals = 1:36)結果は、6 行 6 列 (引数 nrow と ncol で指定)のラスタオブジェクトと、XとY方向の最小と最大の空間範囲 (xmin、xmax、ymin、ymax) となる。
vals 引数は、各セルが含む値を設定する。この場合、1 から 36 までの数値データである。
ラスタオブジェクトは、R のクラス logical または factor 変数のカテゴリ値も含むことができる。
次のコードでは、Figure 3.2 に示すラスタデータセットを作成する。
grain_order = c("clay", "silt", "sand")
grain_char = sample(grain_order, 36, replace = TRUE)
grain_fact = factor(grain_char, levels = grain_order)
grain = rast(nrows = 6, ncols = 6, resolution = 0.5,
xmin = -1.5, xmax = 1.5, ymin = -1.5, ymax = 1.5,
vals = grain_fact)
ラスタオブジェクトは、対応するルックアップテーブルまたは「ラスタ属性テーブル」(Raster Attribute Table, RAT) をデータフレームのリストとして格納し、cats(grain) (詳しくは ?cats()) を使って表示することができる。
このリストの各要素は、ラスタのレイヤである。
また、関数 levels() を使って、新しい因子レベルの取得や追加、既存の因子の置き換えを行うことも可能である。
grain2 = grain # 元データを書き換えない
levels(grain2) = data.frame(value = c(0, 1, 2), wetness = c("wet", "moist", "dry"))
levels(grain2)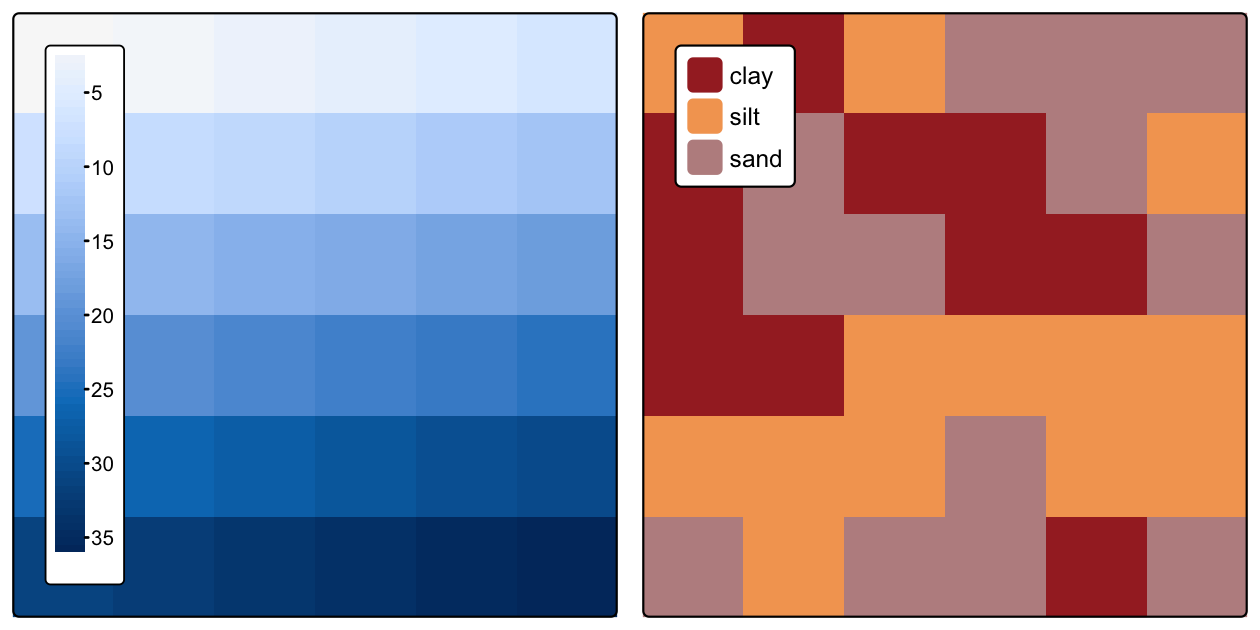
FIGURE 3.2: 数値 (左) とカテゴリ値 (右) を持つラスタデータセット。
coltab() 関数で確認または設定できる (?coltab 参照)。
重要なこととして、色テーブル付きでラスタオブジェクトをファイル (GeoTIFF など) に保存すると、色情報も保存される。
3.3.1 ラスタ部分集合
ラスタの部分集合は、R の基本演算子である [ で行われ、さまざまな入力を受け入れることができる。
- 行・列のインデックス作成
- セル ID
- 座標
- 別の空間オブジェクト
ここでは、非空間的な操作である最初の 2 つのオプションのみを示す。 空間オブジェクトをサブセットする必要がある場合、あるいは出力が空間オブジェクトである場合、これを空間サブセットと呼ぶことにする。 後者の 2 つのオプションについては、次章で紹介する (Section 4.3.1)。
まず、二つの部分集合作成方法を以下のコマンドで示す。
両者は、いずれもラスタオブジェクト elev の左上のピクセルの値を返す (結果は示していない)。
# 行 1, 列 1
elev[1, 1]
# cell ID 1
elev[1]複数レイヤのラスタオブジェクトを部分集合作成すると、各レイヤのセル値が返される。
例えば two_layers = c(grain, elev); two_layers [1] は 1 行 2 列のデータフレームを返す。
すべての値を抽出するには、values() を使用することもできる。
部分集合作成操作と連動して、既存の値を上書きすることでセルの値を変更することができる。
例えば、次のコードチャンクは、elev の左上のセルに 0 を設定する (結果は表示していない)。
elev[1, 1] = 0
elev[]角括弧を空にすると、ラスタのすべての値を取得する values() のショートカット版である。
また、複数のセルをこの方法で修正することも可能である。
elev[1, c(1, 2)] = 0レイヤが複数あるラスタの値の置き換えは、列がレイヤと同じ数、行が置き換え可能なセルと同じ数の行列で行うことができる (結果は示していない)。
3.3.2 ラスタオブジェクトのまとめ
terra は、ラスタ全体の記述統計量を抽出するための関数を含んでいる。
ラスタオブジェクトの名前を入力してコンソールに印刷すると、ラスタの最小値と最大値が返される。
summary() は、一般的な記述統計量を提供する。 すなわち、連続ラスタでは最小値、最大値、四分位値、NA の件数、カテゴリラスタでは各クラスのセルの数である。
標準偏差 (下記参照) やカスタム要約統計などのさらなる要約操作は、global() で計算することができる。
global(elev, sd)summary() と global() にマルチレイヤのラスタオブジェクトを与えると、描くレイヤを個別に要約する。以下を実行して確認できる。summary(c(elev, grain)).
summary() and global()
さらに、freq() 関数を使用すると、カテゴリ値の頻度表を取得することができる。
freq(grain)
#> layer value count
#> 1 1 clay 10
#> 2 1 silt 13
#> 3 1 sand 13ラスタ値の統計は、様々な方法で可視化することができる。
boxplot()、density()、hist()、pairs() などの特定の関数は、以下のコマンドで作成されたヒストグラムで示されるように、ラスタオブジェクトでも動作する (図示していない)。
hist(elev)
目的の可視化機能がラスタオブジェクトで動作しない場合、values() (Section 3.3.1) の助けを借りて、プロットするラスタデータを抽出することができる。
記述的ラスタ統計は、いわゆるグローバルなラスタ演算に属する。 これらの操作やその他の典型的なラスタ処理操作は、マップ代数スキームの一部であり、次の章 (Section 4.3.2) で説明する。
パッケージ間で関数名が衝突することがある(例えば、extract()
という名前の関数が terra と tidyr
の両方のパッケージに存在する場合など)。
パッケージをロードする順番を変えると、予想しない結果が発生することがある。
関数名の衝突を防ぐには、パッケージをロードせずに名前空間を明示する方法
(例: tidyr::extract()) や、detach()
で問題となるパッケージをアンロードする方法がある。
例えば、以下のコマンドは terra
パッケージをアンロードする (これは RStudio
の右下ペインにデフォルトで存在する Packages
タブでも行うことができる):
detach(“package:terra”, unload = TRUE, force = TRUE)。
force
引数は、他のパッケージがそのパッケージに依存している場合でも、そのパッケージを切り離すことを保証する。
しかし、これは切り離されたパッケージに依存しているパッケージの使い勝手を悪くする可能性があるため、推奨されない。
3.4 演習
演習では、spData パッケージの us_states と us_states_df というデータセットを使用する。
このデータと、属性を操作するためのパッケージを読み込むため、 library(spData) などのコマンドを実行しておく必要がある。
us_states は、(sf クラスの) 特別なオブジェクトで、アメリカ合衆国の州のジオメトリと複数の属性 (name、region、area、 population など) がある。
us_states_df は、(data.frame の) データフレームであり、アメリカ合衆国各州の name とその他の変数 (2010年と2015年の年収中央値や貧困度合など) で、Alaska、Hawaii、Puerto Rico も含んでいる。
このデータは、米国国勢調査局のもので、ドキュメントは ?us_states と ?us_states_df とすることで読むことができる。
E1. us_states オブジェクトから NAME 列のみを含む us_states_name という新しいオブジェクトを、Base R ([) または tidyverse (select()) 構文を使用して作成しなさい。
新しいオブジェクトのクラスは何か?
E2. us_statesオブジェクトから、人口データを含む列を選択しなさい。
別のコマンドを使用して同じことをしなさい(ボーナス: 3 つの方法を見つけなさい)。
ヒント: dplyr の contains や matches などのヘルパー関数を使用してみる (?contains を参照)。
E3. 以下の特徴を持つ状態をすべて見つけなさい (ボーナス、見つけた後でプロットしなさい)。
- 中西部 (Midwest) 地域に属する。
- 西 (West) 地域に属し、面積が250,000km2未満でかつ、2015年の人口が 5,000,000 人を超える (ヒント: 関数
units::set_units()またはas.numeric()を使用する必要があるかもしれない)。 - 南 (South) 地域に属し、面積が 150,000 km2 を超え、2015年の総人口が 7,000,000 人を超える。
E4. us_states データセットにおける2015年の総人口は?
2015年の総人口の最小値と最大値は?
E5. 各地域にはいくつの州があるのか?
E6. 2015年の各地域の総人口の最小値と最大値は? 各地域の2015年の総人口は?
E7. us_states_df の変数を us_states に追加し、us_states_stats という新しいオブジェクトを作成しなさい。
どの関数を使用したか?
両方のデータセットでどの変数がキーであったか?
新しいオブジェクトのクラスは何か?
E8. us_states_df は us_states より2行多い。
多い部分をどのように発見するか (ヒント: dplyr::anti_join() 関数を使ってよい。)?
E9. 各州の2015年の人口密度は? 各州の2010年の人口密度は?
E10. 各州の人口密度は2010年から2015年の間にどれだけ変化したか? その変化をパーセンテージで計算し、地図に表しなさい。
E11. us_states の列の名称を小文字にしなさい (ヒント: 関数 tolower() と colnames() を使うと良い)。
E12. us_states と us_states_df を使って us_states_sel という新しいオブジェクトを作成しなさい。
この新しいオブジェクトには、median_income_15 と geometry の 2 つの変数だけにしなさい。
median_income_15 列の名前を Income に変更しなさい。
E13. 各州の2010年から2015年の間の貧困ボーダー以下の住民数の変化を計算しなさい。(ヒント: 貧困レベルの列に関するドキュメントは ?us_states_df を参照)。 ボーナス: 各州の貧困レベル以下で暮らす住民のパーセンテージの変化を計算しなさい。
E14. 2015年、各地域の貧困ボーダー以下で暮らす人々の州の最小数、平均数、最大数は? ボーナス: 貧困ボーダー以下で暮らす人の増加が最も大きかった地域は?
E15. 9 行 9 列、解像度 0.5 度 (WGS84) のラスタをゼロから作成しなさい。 それを乱数で埋めなさい。 4 つのコーナーセルの値を抽出しなさい。
E16. 例にあるラスタ grain の最も一般的なクラスは何か?
E17. spDataLarge パッケージの dem.tif ファイルのヒストグラムと箱ひげ図をプロットしなさい。 (system.file("raster/dem.tif", package = "spDataLarge")).