16 結論
イントロダクション
第 1 章と同様、結論にはコードチャンクはほとんどない。 ここでの目的は、繰り返されるテーマ/概念に言及しながら、本書の内容を総括し、今後の応用や開発の方向性を鼓舞することにある。 この章には前提条件はない。 しかし、第I部 (基礎編) の練習問題を読んで挑戦し、第II部 (拡張機能) のより高度な問題に挑戦し、第III部 (応用編) の章を参考に、ジオコンピュテーションが仕事、研究、その他の問題の解決にどのように役立つかを考えていたならば、より多くのものを得ることができるであろう。
本章は、以下のように構成されている。 Section 16.1 は、R で地理データを扱うための幅広いオプションについて説明する。 選択は、オープンソースソフトウェアの重要な特徴である。このセクションでは、様々なオプションの中から選択するためのガイダンスを提供する。 Section 16.2 では、本書の内容とのギャップを説明し、意図的に省略された研究分野、強調された分野の理由を説明している。 Section 16.3 では、問題に直面した時にどのように質問し、オンラインで解決を探すためのアドバイスを行う。 Section 16.4は、この本を読んだあとで、次はどこへ行くのかという問いに答える。 Section 16.5 は、Chapter 1 で提起されたより広範な問題に戻る。 その中で、ジオコンピュテーションを、手法が一般にアクセス可能で、再現性があり、協力的なコミュニティによってサポートされていることを保証する、より広い「オープンソースアプローチ」の一部として考えている。 この最終章では、参加するためのポイントも紹介している。
16.1 パッケージの選択
オープンソース全般に言えることだが、R の特徴として、同じ結果を得るために複数の方法が存在することが多い。 下記のコードでは、Chapter 3 と Chapter 5 にある 3 つの関数を使って、New Zealand の 16 の地域を 1 つの幾何学的形状にまとめている。
library(spData)
#> Warning: package 'spData' was built under R version 4.3.3
nz_u1 = sf::st_union(nz)
nz_u2 = aggregate(nz["Population"], list(rep(1, nrow(nz))), sum)
nz_u3 = dplyr::summarise(nz, t = sum(Population))
identical(nz_u1, nz_u2$geometry)
#> [1] TRUE
identical(nz_u1, nz_u3$geom)
#> [1] TRUE作成されたクラス、属性、列の名称は nz_u1 から nz_u3 まで異なるが、その幾何学的な形状は同一であることを Base R 関数 identical() を使って検証している。103
どの方法を使うべきかは、ケースバイケースである。
1番目の方法は nz に含まれるジオメトリデータのみを処理するので高速であるが、2・3番目の方法は属性操作を行うので、この後の処理に役立つ可能性がある。
Base R の aggregate() 関数を使うか、dplyr の summarise() を使うかは好みの問題であるが、後者の方が読みやすいだろう。
つまり、R で地理データを扱う場合、たとえ 1 つのパッケージであっても、複数の選択肢から選ぶことができる場合が多いということである。 R のパッケージが増えれば、さらに選択肢は広がる。例えば、古いパッケージの sp を使っても同じ結果を得ることができる。 しかしながら、良いアドバイスをしたいという本書のゴールに従うと、パフォーマンスもよく将来性のある sf パッケージを推奨する。 このことは、本書のすべてのパッケージに当てはまるが、他の手段の存在を知って自分の選択について正当化できることは、(邪魔にならない程度に) 役に立つことがある。
ジオコンピュテーションをする際の選択で困ることの代表として、 tidyverse と Base R のどちらを使うかという簡単に答えられない問題がある。
例えば、次のコードチャンクは、Chapter 3 で説明したした nz オブジェクトから Name 列を抽出する操作を、tidyverse と Base R の 2 つの方法を示している。
library(dplyr) # TidyVerse パッケージをアタッチ
nz_name1 = nz["Name"] # Base R による方法
nz_name2 = nz |> # TidyVerse による方法
select(Name)
identical(nz_name1$Name, nz_name2$Name) # 結果の確認
#> [1] TRUEここで、「どちらを使うべきか?」という問題が出てくる。 答えは、「人それぞれ」である。 それぞれのアプローチには利点がある。Base R は、安定でよく知られており、依存関係が最小である傾向があるため、ソフトウェア (パッケージ) 開発に好まれることが多い。 一方、Tidyverse アプローチは、対話型プログラミングに好まれている。 したがって、2つのアプローチのどちらを選ぶかは、好みと用途の問題である。
本書では、Rの基本演算子である [ サブセット演算子や、上のコードで示した dplyr 関数 select() など、一般的に必要とされる関数を取り上げているが、地理データを扱うための、他のパッケージの関数には触れていないものが多くある。
Chapter 1 では、地理データを扱うための 20 以上の有力なパッケージが紹介したが、この本ではそのうちのほんの一握りしか紹介されていない。
R で地理データを扱うためのパッケージは他にも何百とあり、毎年多くのパッケージが開発されている。
2024年現在、Spatial Task Viewで紹介されているパッケージは 160 以上あり、地理データ解析のための無数の関数が毎年開発されている。
R の空間生態系の進化のスピードは速いが、幅広い選択肢に対応するための戦略がある。 アドバイスは、まず 1 つのアプローチを深く学び、利用可能なオプションの広さを知っておく。 このアドバイスは、R で地理的な問題を解決する際にも他の分野の知識や応用と同様に適用される。 他の言語での開発については、Section 16.4 で説明する。
もちろん、同じタスクでもパッケージによっては他のパッケージより性能が良いものもあり、その場合はどのパッケージを使うべきかを知ることが重要です。 この本では、将来性があり (将来も使える)、(他の R パッケージと比較して) 高性能で、(ユーザーや開発者のコミュニティがあり) よくメンテナンスされており、補完的なパッケージに焦点を当てることを目的としている。 また、本書で取り上げたパッケージの中には、重複しているものもあり、例えば、「地図作成用パッケージの多様性」については、本章の「地図作成用パッケージの多様性」で紹介している。
機能が重複することは良いことである。
既存のパッケージと同様の (しかし同一ではない) 機能を持つ新しいパッケージは、オープンソースソフトウェアでジオコンピュテーションを行う重要な利点である回復力、パフォーマンス (開発者間の切磋琢磨と相互学習による部分もある)、選択肢を増やすことができる。
この文脈では、sf、tidyverse、terra や他のパッケージのどの組み合わせを使用するかを決めることは、代替案を知った上で行うべきである。
例えば、sf が取って代わるように設計されている sp エコシステムは、本書で取り上げたことの多くを行うことができ、その古さゆえに他の多くのパッケージが構築されている。
2024年の執筆時点で、463 のパッケージが sp を Depend または Importしており、2018年10月の 452 からわずかに増加しており、そのデータ構造が広く使われ、多くの方向に拡張されていることを示している。
sf の方はというと、2018年に 69、2023年に 431 であり、このパッケージが将来性を持ち、ユーザーベースと開発者コミュニティが拡大していることを強調している (Bivand 2021)。
点パターン解析でよく知られている spatstat パッケージは、ラスタやその他のベクトルジオメトリもサポートし、空間統計などのための強力な機能を提供する (Baddeley and Turner 2005)。
また、既存のパッケージでは満たされないニーズがある場合は、開発中の新しい選択肢を研究する価値があるかもしれない。
16.2 ギャップとオーバーラップ
ジオコンピュテーションは巨大な分野であり、多くのギャップがあることは避けられない。 特定にトピックやテクニック、パッケージを意図的に強調し、あるいは省略するなど、選択的に行っている。 地理データの操作、座標参照系の基本、データの読み書き、可視化技術など、実際のアプリケーションで最もよく必要とされるトピックを重視するよう努めた。 また、本書は、ジオコンピュテーションに必要なスキルを身につけ、さらに高度なトピックや特定のアプリケーションに進む方法を紹介することを目的としており、いくつかのトピックやテーマは何度も登場する。
また、他で深く取り上げられているトピックをあえて省略した。 例えば、点パターン解析、空間補間 (例えばクリギング)、空間回帰といった空間データの統計的モデリングは、機械学習の文脈で Chapter 12 で触れているが、詳細には触れていない。 これらの手法については、Pebesma and Bivand (2023c) の統計学的指向の章や、ポイントパターン分析に関する書籍 (Baddeley, Rubak, and Turner 2015)、空間データに適用するベイズ手法 (Gómez-Rubio 2020; Moraga 2023)、健康 (Moraga 2019) や山火事深刻度分析 など特定のアプリケーションに焦点を当てた書籍といった優れた資料がすでに存在している (Wimberly 2023)。 その他の話題としては、リモートセンシングや、GIS 専用ソフトと並行しての R の利用 (ブリッジとしてではなく) などが挙げられるが、これらは限定的である。 これらの話題については、R におけるリモートセンシングについての議論、Wegmann, Leutner, and Dech (2016) や Marburg University から入手できる GIS 関連教材など、多くの資料がある。
Chapter 12 と Chapter 15 で空間統計推論よりも機械学習に焦点を当てたのは、このトピックに関する質の高いリソースが豊富にあるためである。 これらのリソースには、生態系のユースケースに焦点を当てた A. Zuur et al. (2009)、A. F. Zuur et al. (2017)、そして css.cornell.edu/faculty/dgr2 でホストされている Geostatistics & Open-source Statistical Computing の自由に利用できる教材とコードがある。 R for Geographic Data Science では、地理データサイエンスとモデリングのための R の紹介をしている。
また、「ビッグデータ」(ハイスペックなラップトップに収まらないデータセットという意味) に対するジオコンピュテーションはほとんど省略している。 この決定は、一般的な研究や政策アプリケーションに必要な地理的データセットの大部分は、個人用ハードウェアに収まるという事実によって正当化される (Section 10.8 参照)。 コンピュータの RAM を増やしたり、GitHub Codespaces: 本書のコードを実行可能 のようなプラットフォームで利用できる計算能力を一時的に「借りる」ことは可能である。 さらに、小さなデータセットで問題を解くことを学ぶことは、巨大なデータセットで問題を解くための前提条件であり、本書で強調しているのは「始めること」であり、ここで学んだスキルは大きなデータセットに移行したときに役立つものである。 「ビッグデータ」の解析には、特定の統計解析のためデータベースからデータを抽出することもある。 Chapter 10 で紹介した空間データベースは、メモリで処理しきれないデータセットの解析に有用である。 ‘Earth observation cloud back-ends’ は、openeo パッケージを使うことで R でアクセスすることができる。 大きな地理データを扱う必要がある場合は、Apache Sedona などのプロジェクトや、GeoParquet などの新しいファイル形式について調べることも勧める。
16.3 ヘルプを求める
ジオコンピュテーションは大規模で困難な分野であるため、問題や一時的な作業中断は避けられない。 多くの場合、データ解析のワークフローの特定の時点で、デバッグが困難な不可解なエラーメッセージに直面し、「立ち往生」することがある。 また、何が起こっているのかほとんどわからないまま、予期せぬ結果が出ることもある。 このセクションでは、そのような問題を克服するために、問題を明確に定義し、解決策に関する既存の知識を検索し、それらのアプローチで問題が解決されない場合は、良い質問をする技術によって、ポイントを提供する。
ある地点で行き詰まったとき、まず一歩下がって、どのようなアプローチが最も解決につながるかを考えてみるのもよいだろう。 以下のステップを順番に試すことで、問題解決のための構造的なアプローチが得られる (すでに試している場合はステップをスキップすることもできる)。
- 第一原理から始めて、何を達成しようとしているのかを正確に定義する (多くの場合、以下のようなスケッチも必要)。
- コードの個々の行や個々のコンポーネントの出力を実行し、調べることによって、コードのどこで予期せぬ結果が発生したかを正確に診断する (例えば、RStudio でカーソルで選択し、Ctrl + Enter を押すことによって、複雑なコマンドの個々の部分を実行することができる)。
- 前のステップで「問題のポイント」と診断された関数のドキュメントを読んでみよう。関数に必要な入力を理解し、ヘルプページの下部によく掲載されている例を実行するだけで、驚くほど大きな割合の問題を解決できる (コマンド
?terra::rastを実行し、その関数を使い始めるときに再現する価値のある例までスクロールダウンする。例) - 前のステップで説明したように R の付属ドキュメントを読んでも問題が解決しない場合は、あなたが見ている問題について他の人が書いていないかどうか、オンラインで広く検索してみるのもよいだろう。検索する場所については、以下のヘルプリストを参照。
- 上記のすべてのステップが失敗し、オンライン検索で解決策が見つからない場合、再現性のある例で質問を作成し、適切な場所に投稿することができる。
上記のステップ 1 から 3 は自明なことであるが、インターネットは広大であり、検索オプションも多数あるため、質問を作成する前に効果的な検索方法を検討する価値がある。
16.3.1 オンラインによる解決方法の検索
多くの問題に対して論理的なスタートを切るのは、検索エンジンである。 「ググる」ことで、あなたが抱えている問題についてのブログ記事、フォーラムメッセージ、その他のオンラインコンテンツを発見することができる場合があるのである。 問題や質問について明確に記述することは有効な方法であるが、具体的に記述することが重要である (例えば、データセット固有の問題であれば、関数やパッケージ名、入力データセットのソースなどを参照すること)。 また、詳細な情報を記載することで、オンライン検索をより効果的にすることができる。
- 引用符を使用すると、返される結果の数を減るため、検索結果が問題に関連する確率を上げる。たとえば、GeoJSON ファイルをすでに存在する場所に保存しようとして失敗した場合、“GDAL Error 6: DeleteLayer() not supported by this dataset” というメッセージを含むエラーが表示される。引用符を使わずに
GDAL Error 6を検索するよりも、"GDAL Error 6" sfのような特定の検索クエリを使用したほうが、解決策が見つかる可能性が高くなる - 期間の制限を設定する。例えば、過去1年以内に作成されたコンテンツのみを返すようにすれば、進化するパッケージのヘルプを検索する際に便利である
- 追加の検索エンジン機能を利用する。例えば、site:r-project.org で CRAN にホストされているコンテンツに検索を限定する
16.3.2 助けを求めるための検索 (依頼) 場所
ネットで検索しても解決しない場合は、助けを求めてもよい。 これを行うには、以下のような多くのフォーラムがある.
- R の Special Interest Group on Geographic データメーリングリスト ( R-SIG-GEO)
- GIS Stackexchange のウェブサイト (gis.stackexchange.com)
- 大型・汎用プログラミングQ&Aサイト stackoverflow.com
- Posit Community、rOpenSci Discuss ウェブフォーラム、 Stan フォーラムなど、特定のソフトウェアツールに関連するフォーラムなど、特定のエンティティに関連するオンラインフォーラム。
- GitHub などのソフトウェア開発プラットフォームは、R-spatial パッケージの大半の課題トラッカーや、最近では sfnetworks パッケージに関する議論 (バグ報告だけでなく) を促すために作られた議論ページなどをホストしている (luukvdmeer/sfnetworks/discussionsを参照)。
- チャットルームやフォーラム rOpenSci や geocompx コミュニティ (これには質問をすることができる Discord server もある)。本書もここに関係している。
- OSGeoJapan のメーリングリスト (日本語)
- r-wakalang Slack (日本語)
16.3.3 reprex による再現性の例
良い質問とは、明確に述べられた質問で、さらにアクセスしやすい完全に再現可能な例があるとよい (https://r4ds.hadley.nz/workflow-help.html も参照)。
また、ユーザーの視点から「うまくいかなかった」コードを示した後、何を見たいかを説明することも有効である。
再現可能な例を作成するための非常に便利なツールが、reprex パッケージである。
予期せぬ動作を強調するために、問題を示す完全に再現可能なコードを書き、reprex()関数を使って、フォーラムや他のオンラインスペースに貼り付けられるようなコードのコピーを作成することができる。
青い海と緑の陸地がある世界地図を作ろうとしているとしよう。 前項で説明したような場所で、その方法を尋ねることもできできる。 しかし、あなたがこれまでに試したことの再現可能な例を示すことで、より良い回答が得られる可能性がある。 次のコードは、青い海と緑の陸地がある世界地図を作成するが、陸地は塗りつぶされない。
このコードをフォーラムに投稿すれば、より具体的で有用な回答が得られる可能性がある。 例えば、Figure 16.1 のように、問題を解決する以下のようなコードを投稿してくれる人がいるかもしれない。
library(sf)
library(spData)
# 塗りつぶすために引数を使用
plot(st_geometry(world), col = "green", bg = "lightblue")
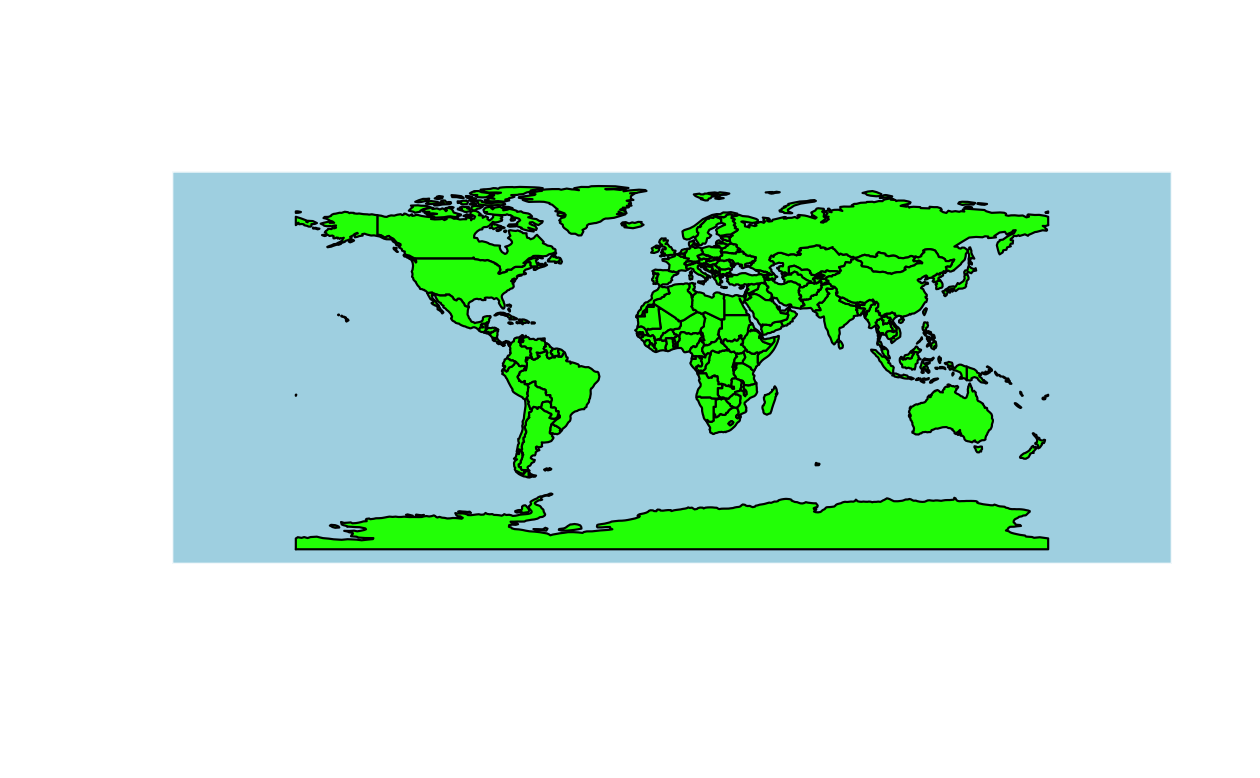
FIGURE 16.1: 世界地図の土地を緑色で示した再現可能な例題 (左) と解 (右) の地図。
読者のための練習: 上記のコードをコピーし、コマンド reprex::reprex() を実行し (またはコマンドを reprex() の関数呼び出しにペーストし)、その出力をフォーラムや他のオンラインスペースにペーストしなさい。
ジオコンピュテーションが、オープンソースとコラボレーションすることで、膨大で進化し続ける知識体系を生み出すことは強みとなり、本書もその一部である。 問題を解決するための自分自身の努力を示し、問題の再現可能な例を提供することは、この知識体系に貢献する方法である。
16.3.4 問題の定義とスケッチ
場合によっては、ネット上で問題解決策を見つけることができなかったり、検索エンジンで答えられるような質問を立てることができないこともある。 新しいジオコンピュテーションの方法論やアプローチを開発するときの最良の出発点は、ペンと紙 (または共同スケッチやアイデアの迅速な共有を可能にする Excalidraw や tldraw などの同等のデジタルスケッチツール) である。方法論開発の作業の最も創造的な初期段階においては、どのようなソフトウェアも思考の速度を落とし、重要な抽象概念から思考を遠ざけることになる。 方法論開発の最も創造的な初期段階において、ソフトウェア (あらゆる種類のもの) は、思考を鈍らせ、重要な抽象的思考から思考を遠ざけることができる。 また、数値的に「前と後」をスケッチできる最小限の例を参照しながら、数学で質問を組み立てることも強く推奨される。 もし、あなたにスキルがあり、問題がそれを必要とするならば、代数的にアプローチを記述することは、場合によっては効果的な実装を開発するのに役立つ。
16.4 次はどこへ行く?
Section 16.2 にあるように、この本は R の地理的なエコシステムのほんの一部しかカバーしておらず、まだまだ発見があるはずである。 Chapter 2 の地理データモデルから、Chapter 15 の高度なアプリケーションまで、急速に進展している。 学習した技術の統合、地理データを扱うための新しいパッケージやアプローチの発見、新しいデータセットやドメインへの手法の適用が今後の方向性として提案されている。 このセクションでは、この一般的なアドバイスに加え、具体的な「次のステップ」を提案し、以下の太字で強調している。
R を使って、例えば前節で引用した研究を参考に、さらなる地理的手法や応用について学ぶことに加え、R そのものの理解を深めることが、論理的な次のステップとなる。
R の基本クラスである data.frame や matrix は、sf や terra クラスの基礎となるものなので、これらを勉強することで地理データの理解が深まるだろう。
これは、R の一部であり、help.start() コマンドで見つけることができるドキュメントや、Wickham (2019) や Chambers (2016) などによるこのテーマに関する追加リソースを参照することで行うことができる。
また、ソフトウェア関連の今後の学習方向としては、他の言語によるジオコンピュテーションの発見が挙げられる。 Chapter 1 で紹介されているように、ジオコンピュテーションのための言語として R を学習することには理由があるが、R が唯一の選択肢というわけではない。104 Python、C++、JavaScript、Scala、Rust を使っても、同じ深さでジオコンピュテーションを勉強することができる。 それぞれが進化した地理空間能力を有している。 例えば、Pythonのパッケージ rasterio は、この本で使われている terra パッケージを補足/置換できるものである。 Python のジオコンピュテーションについては、Geocomputation with Python を参照。
C++ では、GDAL や GEOS などのよく知られたライブラリから、リモートセンシング (ラスタ) データを処理する Orfeo Toolbox などのあまり知られていないライブラリなど、数十の地理空間ライブラリが開発されている。 Turf.js は、JavaScript でジオコンピュテーションを行う可能性を示す一例である。 GeoTrellis は、Java ベースの言語である Scala でラスタおよびベクタデータを扱うための関数を提供する。 また、WhiteBoxTools は、Rust で実装された急速に進化するコマンドライン GIS の例を示している。 これらのパッケージ/ライブラリ/言語はそれぞれジオコンピュテーションに有利であり、オープンソースの地理空間リソースのキュレーションリスト Awesome-Geospatial に記されているように、さらに多くの発見がある。
しかし、ジオコンピュテーションには、ソフトウェア以上のものがある。 学術的・理論的な観点から、新しい研究テーマや手法の探求・習得をお勧めできる。 これまで書かれてきた手法の中には、まだ実装されていないものも多くある。 そのため、コードを書く前に、地理的な手法や潜在的なアプリケーションについて学ぶことは有意義なことである。 R で実装されることが多くなった地理的手法の例として、科学的なアプリケーションのためのサンプル戦略がある。 この場合の次のステップは、 github.com/DickBrus/TutorialSampling4DSM でホストされている再現可能なコードとチュートリアルコンテンツを伴う Brus (2018) などの領域の関連記事を読み解くことである。
16.5 オープンソースのアプローチ
この本は技術書であるから、前節で説明した次のステップも技術的なものであることに意味がある。 しかし、この最後のセクションでは、ジオコンピュテーションの定義に戻り、より広範な問題を検討する価値がある。 Chapter 1 で紹介した用語の要素のひとつに、「ジオグラフィック・メソッドはポジティブな影響を与えるものでなければならない」というものがある。 もちろん、「ポジティブ」をどう定義し、どう測定するかは、本書の範囲を超えた、主観的で哲学的な問題である。 どのような世界観を持っていても、ジオコンピュテーションがもたらす影響について考えることは有益なことである。 また逆に、新しい手法は多くの応用分野を開拓する可能性がある。 これらのことから、ジオコンピュテーションはより広範な「オープンソースアプローチ」の一部であるという結論が導き出される。
Section 1.1 は、地理データ科学 (geographic data science, GDS) や GIScience など、ジオコンピュテーションとほぼ同じ意味を持つ他の用語を提示した。 どちらも地理データを扱うことの本質を捉えているが、ジオコンピュテーションには利点がある。本書で提唱する地理データの「計算」的な扱い方 (コードで実装されているので再現性がある) を簡潔に捉え、初期の定義にあった望ましい要素に基づいて構築されている (Openshaw and Abrahart 2000)。
- 地理データのクリエイティブな活用法
- 実社会の問題への応用
- 「科学的」な道具を作る
- 再現性
再現性は、ジオコンピュテーションの初期の研究ではほとんど言及されていなかったが、最初の 2 つの要素に不可欠な要素であることを強く主張することができる。 再現性は、
- (共有コードで容易に利用できる) 基本から応用へと焦点を移すことで、創造性を促進する。
- 「車輪の再発明」を防ぐ: 他の人がやったことを、他の人が使えるのであれば、やり直す必要はない。
- あらゆる分野の誰もが新しい分野であなたの方法を適用できるようにすることで、研究をより実世界での応用に近づけられるようにする。
もし再現性がジオコンピュテーション (あるいはコマンドライン GIS) の決定的な資産であるならば、何が再現性をもたらすかを考える価値がある。 そこで、「オープンソースアプローチ」に行き着くのだが、これには 3 つの主要な要素がある。
- コマンドラインインターフェース (CLI): 地理的な作業を記録したスクリプトの共有と再現を促進する
- オープンソースソフトウェア: 世界中の誰もが検査し、改良できる可能性がある。
- 活発なユーザーと開発者コミュニティは、補完的でモジュール化されたツールを構築するために協力し、自己組織化している。
ジオコンピュテーションという言葉があるように、オープンソース的アプローチは単なる技術的な存在にとどまらない。 商業的、法的な制約を受けず、誰でも使える高性能なツールを作るという共通の目的を持って日々活動している人たちで構成されるコミュニティである。 地理データを扱うオープンソース的アプローチには、ソフトウェアの動作に関する技術的な問題を超えて、学習、コラボレーション、効率的な分業を促進する利点がある。
特に GitHub のような、コミュニケーションとコラボレーションを促進するコードホスティングサイトの出現により、このコミュニティに参加する方法はたくさんある。
手始めに、興味のある地理的なパッケージのソースコード、issues、commits のいくつかに目を通すとよいだろう。
r-spatial/sf GitHub リポジトリをざっと見ると、sf パッケージの基礎となるコードをホストしており、100 人以上がコードベースとドキュメントに貢献していることがわかる。
さらに何十人もの人が、質問をしたり、sf が使っている「上流」のパッケージに貢献している。
その issue tracker には 1,500 以上の問題がクローズされ、より速く、より安定した、ユーザーフレンドリーな sf を実現するための膨大な作業が行われている。
この例は、数十のパッケージのうちのたった一つの例であるが、R を非常に効果的で継続的に進化するジオコンピュテーションとするために行われている知的作業の規模を表している。
GitHub のような公的な場で絶え間なく起こる開発活動を見るのも勉強になるが、自分が積極的に参加することでより大きな収穫を得ることができる。 これは、オープンソースの最大の特徴で、人々の参加を促すものである。 この本自体もオープンソース化した結果である。 これは、過去 20 年間の R の地理的機能の驚くべき発展によって動機づけられたが、共同作業のためのプラットフォーム上での対話とコード共有によって、現実的に可能になった。 本書が、地理データを扱うための有用な手法を広めるだけでなく、よりオープンソースに近いアプローチをとるきっかけになればと願っている。