4 空間データ操作
必須パッケージ
- この章では、Chapter 3 で使用したものと同じパッケージが必要である。
4.1 イントロダクション
ジオコンピュテーションにおいて、ベクタデータセット間の空間結合やラスタデータセットのローカルおよびフォーカル演算などの空間演算は重要な要素である。 この章では、空間オブジェクトがその位置と形状に基づいて、さまざまな方法で変更できることを紹介する。 空間的な操作の多くは、非空間的 (属性的) な操作に相当するため、前の章で示したデータセットの部分集合や結合といった概念がここでも適用できる。 これは特にベクタ操作に当てはまる。ベクタ属性の操作に関する Section 3.2 は、空間的な対応である空間部分集合 (Section 4.2.1 で取り上げている) を理解するための基礎となるものである。 空間結合 (Section 4.2.5、4.2.6、4.2.8) と属性集計 (Section 4.2.7) には、前の章で説明した非空間的な対応関係がある。
しかし、空間演算は非空間演算と異なる点がいくつもある。 例えば空間結合は、ターゲットデータセットと交差する、または一定の距離内にあるモノのマッチングなど、結合方法は多数ある。一方、前章の Section 3.2.4 で説明した属性結合は、1 つの方法でしかできない (ただし fuzzyjoin パッケージのドキュメントで説明した、ファジー結合を使う場合は別)。 オブジェクト間の空間的関係のさまざまなタイプ (intersect と disjoint を含む) については、Section 4.2.2 で説明する。 空間オブジェクトのもう一つのユニークな側面は距離である。すべての空間オブジェクトは空間を通じて関連しており、距離計算を行うことでこの関係の強さを調べることができる。これは、Section 4.2.3 と Section 4.2.4 のベクタデータで説明する。
ラスタの空間演算として、部分集合は Section 4.3.1 で説明する。 マップ代数は、ラスタのセルの値を、周囲のセル値を参照して、あるいは参照せずに変更する操作を対象とする。 多くのアプリケーションに不可欠なマップ代数の概念は、Section 4.3.2 で紹介している。ローカル、フォーカル、ゾーンのマップ代数演算については、それぞれ Section 4.3.3、Section 4.3.4、Section 4.3.5 のセクションで解説している。 ラスタデータセット全体を表す要約統計量を生成するグローバルマップ代数操作と、ラスタの距離計算については、Section 4.3.6 で説明する。 次に、地図代数とベクタ操作を Section 4.3.7 で議論する。 Section 4.3.8,1 では、2 つのラスタデータセットを合成する方法について説明し、再現可能な例を挙げて実演している。
4.2 ベクタデータに対する空間演算
ここでは、sf パッケージのシンプルフィーチャとして表現されたベクタ地理データに対する空間演算の概要を説明する。 Section 4.3 は、terra パッケージのクラスと関数を使用したラスタデータセットの空間演算を紹介する。
4.2.1 空間部分集合
空間部分集合とは、空間オブジェクトを取り出し、別のオブジェクトと空間的に関連するフィーチャだけを含む新しいオブジェクトを返す処理である。
属性部分集合 (Section 3.2.1 で説明) と同様に、sf データフレームの部分集合は、角括弧を使用して作成できる ([) を使い、x[y, , op = st_intersects] という文法を使う。ここで x は行の部分集合が返される sf オブジェクト、y は「部分集合・オブジェクト」、op = st_intersects は部分集合を行うために使われる位相関係 (二項述語 binary predicate としても知られている) を指定するオプションの引数である。
op 引数がないときに使用されるデフォルトの位相関係は、st_intersects()である。つまり、コマンド x[y, ] は x[y, , op = st_intersects] と同じであり x[y, , op = st_disjoint] とは異なる (これらのトポロジカル関係の意味と他のトポロジカル関係は次のセクションで説明する)。
tidyverse の filter() 関数も使用できるが、この方法は、以下の例で見るように、より冗長である。
空間部分集合を示すために、spData パッケージの nz と nz_height データセットを使用する。これは、New Zealand の 16 の主要地域と 101 の最高地点に関する地理データをそれぞれ含み (Figure 4.1)、投影座標参照系で表示されるものである。
次のコードでは、Canterbury を表すオブジェクトを作成し、空間部分集合を使用して、対象地域のすべての高点を返す。
canterbury = nz |> filter(Name == "Canterbury")
canterbury_height = nz_height[canterbury, ]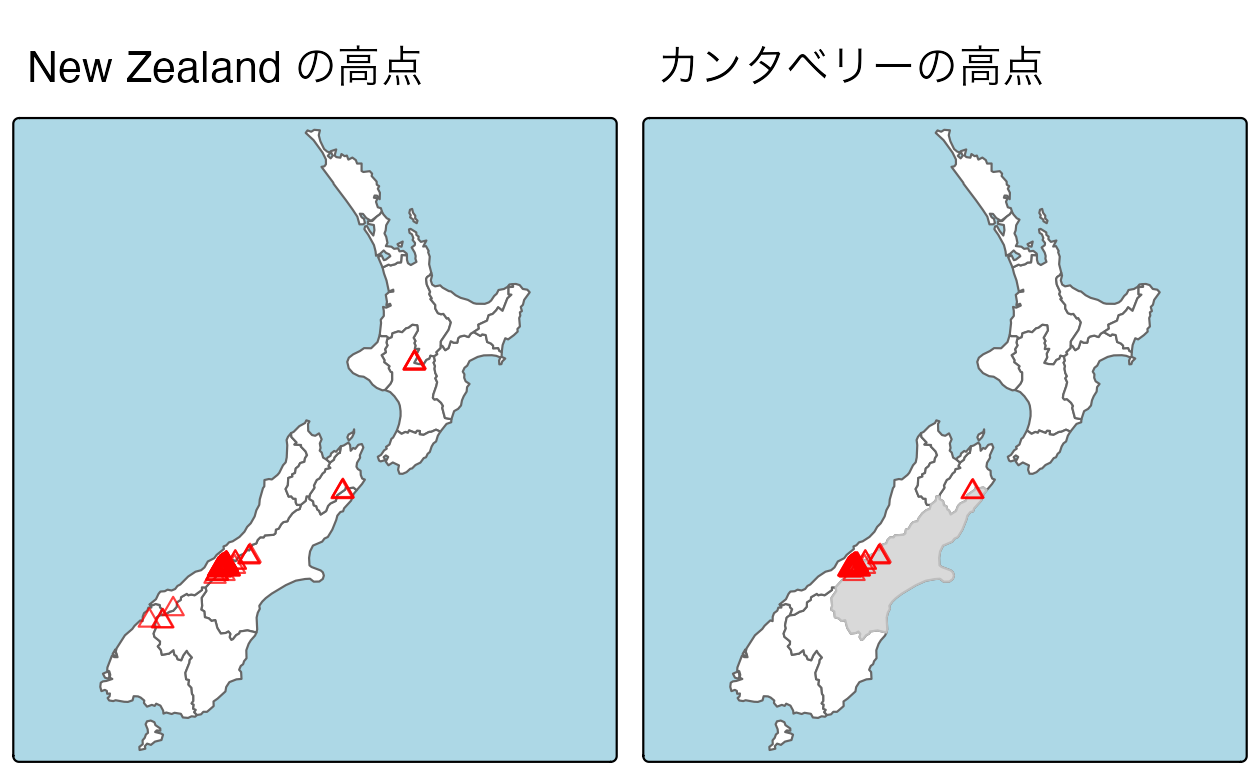
FIGURE 4.1: 赤い三角形はNew Zealand の 101 の High Point を表し、中央のカンタベリー地域付近に集まっている (左)。カンタベリーのポイントは、[ 部分集合演算子で作成された (グレーでハイライト、右)。
属性による部分集合と同様に、コマンド x[y, ] (nz_height[canterbury, ] と同等) は、ソース オブジェクトの内容を使用して、ターゲットのフィーチャの部分集合を返す。
しかし、y がクラス logical または integer のベクトルである代わりに、空間部分集合では x と y の両方が地理オブジェクトでなければならない。
具体的には、この方法で空間部分集合に使用されるオブジェクトは、クラス sf または sfc を持つ必要がある。nz と nz_height は共に地理ベクタデータフレームで、クラス sf を持つ。操作の結果、ターゲット nz_height オブジェクトの中で canterbury 地域と交差する (この場合はその中にある点) フィーチャを表す別の sf オブジェクトが返される。
空間部分集合には、ターゲットオブジェクトのフィーチャが選択される部分集合オブジェクトとどのような空間的関係を持たなければならないかを決める、様々な位相関係を用いることができる。
これには、Section 4.2.2 で見るように、touches、crosses、within が含まれる。
デフォルトの設定 st_intersects は、ソース「部分集合」オブジェクトに touches、crosses、within するターゲット内のフィーチャを返す「全て」の位相関係である。
op = 引数で別の空間演算子を指定することもできる。次のコマンドでは、st_intersects() の逆で、カンタベリーと交差しない点を返す (Section 4.2.2 を参照)。
nz_height[canterbury, , op = st_disjoint], , で示される) は、[ が、sf オブジェクトの3番目の引数である op を強調するために含まれていることに注意。
これを使うと、部分集合操作をいろいろな方法で変更することができる。
例えば、nz_height[canterbury, 2, op = st_disjoint] は同じ行を返すが、2 番目の属性列のみを含む (詳細は sf::`[.sf` and the ?sf)。
ベクタデータの空間部分集合についてこれだけ知っておけば多くの応用例を使うことができる。
st_intersects() や st_disjoint() 以外の位相関係をすぐに学びたいのであれば、残りを飛ばして次の章 (Section 4.2.2) に飛んでも構わない。
ここからは、その他の部分集合化の方法などの詳細について説明する。
空間部分集合を行うもう一つの方法は、位相演算子によって返されるオブジェクトを使用することである。 これらのオブジェクトは、それ自体、例えば、連続する領域間の関係のグラフネットワークを探索する際に有用であるが、以下のコードチャンクで示されるように、部分集合にも使用できる。
sel_sgbp = st_intersects(x = nz_height, y = canterbury)
class(sel_sgbp)
#> [1] "sgbp" "list"
sel_sgbp
#> Sparse geometry binary predicate list of length 101, where the
#> predicate was `intersects'
#> first 10 elements:
#> 1: (empty)
#> 2: (empty)
#> 3: (empty)
#> 4: (empty)
#> 5: 1
#> 6: 1
....
sel_logical = lengths(sel_sgbp) > 0
canterbury_height2 = nz_height[sel_logical, ]上記のコードチャンクは、クラス sgbp のオブジェクト (疎な幾何学二項述語、空間演算における長さ x のリスト) を作成し、それを論理ベクタ sel_logical (TRUE と FALSE の値のみを含み、dplyr のフィルタ関数でも使用できるもの) に変換している。
関数 lengths() は、nz_height のどのフィーチャが y の 任意の物体と交差しているかを特定する。
この場合、1 が最も大きな値であるが、より複雑な操作を行う場合には、例えば、ソースオブジェクトの 2 つ以上のフィーチャと交差するフィーチャのみを部分集合するような方法を用いることができる。
st_intersects() などの演算子で sparse = FALSE (「疎行列ではなく密行列を返す」という意味) をセットする方法がある。例えば、st_intersects(x = nz_height, y = canterbury, sparse = FALSE)[, 1] というコマンドは、sel_logical と同じ出力を返す。
注意: sgbp オブジェクトを含むソリューションは、多対多のオペレーションに対応し、より低いメモリ要件で動作するため、より一般的な方法である。
sf オブジェクトと dplyr データ操作コードの互換性を高めるために作成された sf 関数 st_filter() でも同じ結果を得ることができる。
canterbury_height3 = nz_height |>
st_filter(y = canterbury, .predicate = st_intersects)この時点で、(行名以外は) 同じバージョンの canterbury_height が 3 つある。1 つは [ 演算子を用いて作成し、もう 1 つは中間選択オブジェクトを介して作成し、最後は sf の便利な関数 st_filter() を用いて作成した。
次のセクションでは、二つのフィーチャが空間的に関連しているかどうかを識別するために使用できる、二項述語としても知られている、さまざまなタイプの空間的関係性を探る。
4.2.2 位相関係
位相関係は、オブジェクト間の空間的な関係を表す。
「二項位相関係」 (binary topological relationships) とは、2 次元以上の点 (一般的には点、線、ポリゴン) の順序集合で定義される 2 つの物体間の空間関係について論理的に記述したもの (答えは TRUE か FALSE しかない) である (Egenhofer and Herring 1990)。
このように言うと、かなり抽象的に聞こえるだろうが、実際、位相関係の定義と分類は、1966年に初めて書籍として出版された数学的基礎に基づいている (Spanier 1995)。 代数的位相幾何学の分野は2000年以降も続いている (Dieck 2008)。
位相関係は数学的な起源を持つが、一般的な空間的関係をテストするためによく使われる関数を視覚化することで、直感的に理解することが可能である。
Figure 4.2 は、様々なジオメトリペアとその関連性を示している。
Figure 4.2 の 3 番目と 4 番目のペア (左から右、そして下) は、ある関係では順序が重要であることを示している。
関係 equals、intersects、crosses、touches、overlaps は対称であり、function(x, y) が真なら function(y, x) も真となる。一方、contains と within など幾何学の順序が重要である関係は、そうではない。
各ジオメトリペアには、次節で説明する FF2F11212 のような「DE-9IM」文字列があることを確認しておこう。
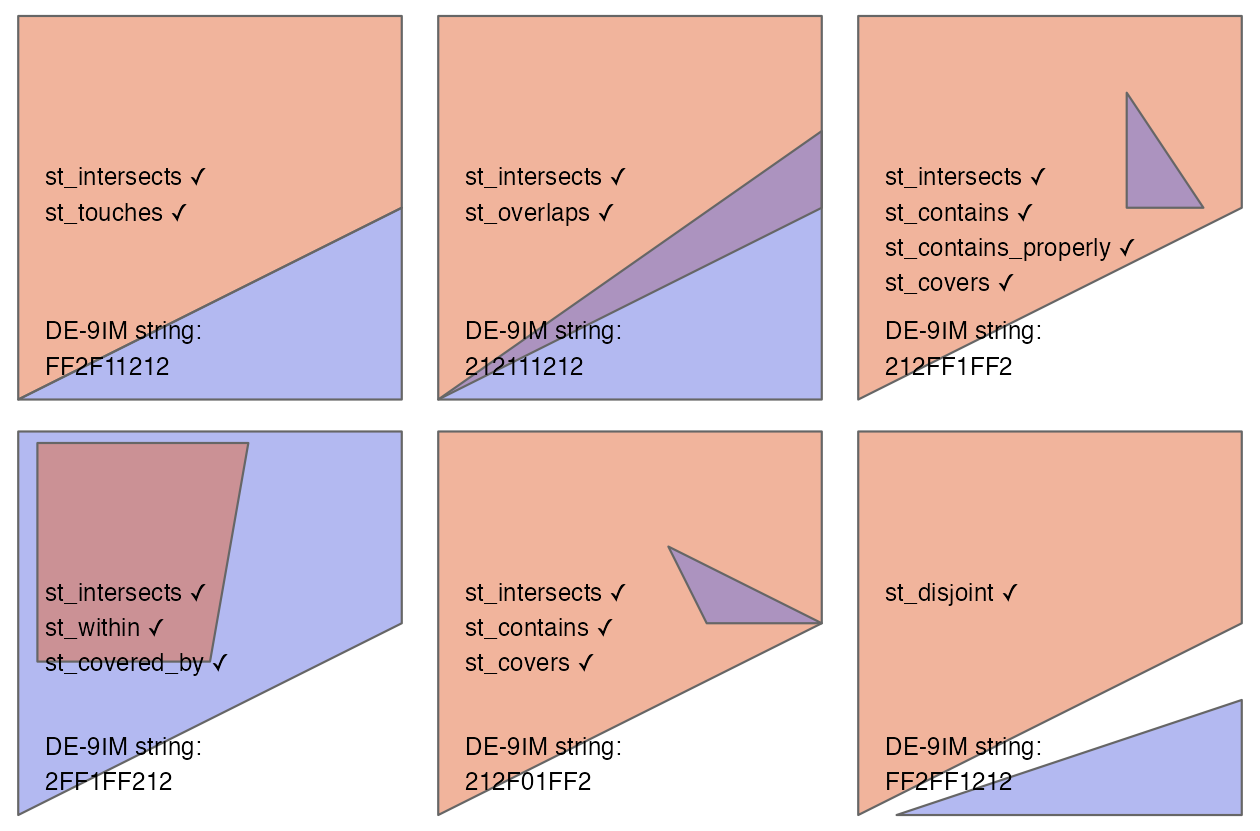
FIGURE 4.2: Egenhofer and Herring (1990)の Figure 1 と Figure 2 を参考にした、ベクトル幾何学間のトポロジー関係。関数(x, y)が真となる関係が、各ジオメトリのペアについて印刷されており、xはピンク、yは青で表されている。各ペアの空間的関係の性質は、Dimensionally Extended 9-Intersection Model 文字列で記述されている。
sf では、異なる種類の位相関係をテストする関数を「二項述語」と呼ぶ。これは、コマンド vignette("sf3") (訳注: 日本語版)、およびヘルプページ ?geos_binary_pred で見ることができる。
位相関係が実際にどのように機能するかを見るために、Figure 4.2 で説明した関係を基に、前の章 (Section 2.2.4) で学んだベクタのジオメトリの表現方法の知識を統合して、簡単な再現性のある例を作ってみよう。
なお、ポリゴンの頂点の座標 (x、y) を表す表形式のデータを作成するために、R の基本関数 cbind() を使って、座標点を表す行列、POLYGON、そして最後に sfc オブジェクトを作成する (Chapter 2 で説明)。
polygon_matrix = cbind(
x = c(0, 0, 1, 1, 0),
y = c(0, 1, 1, 0.5, 0)
)
polygon_sfc = st_sfc(st_polygon(list(polygon_matrix)))次のコマンドで、空間的な関係を示す追加の形状を作成する。これらの形状は、上で作成したポリゴンの上にプロットすると、Figure 4.3 に示すように、互いに空間的に関連するようになる。
関数 st_as_sf() と引数 coords を使って、座標を表す列を含むデータフレームから、点を含む sf オブジェクトに効率的に変換していることに注目してみよう。
point_df = data.frame(
x = c(0.2, 0.7, 0.4),
y = c(0.1, 0.2, 0.8)
)
point_sf = st_as_sf(point_df, coords = c("x", "y"))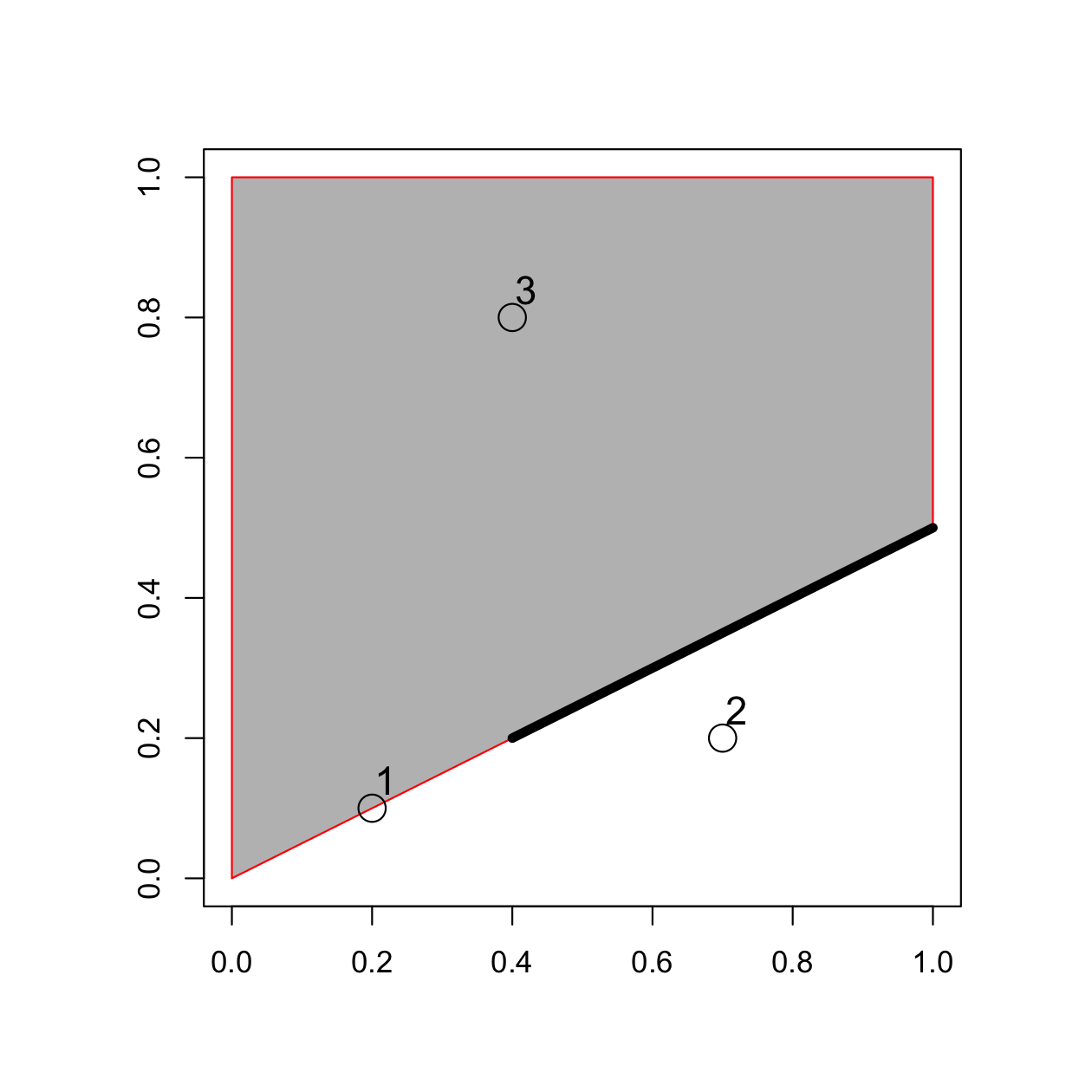
FIGURE 4.3: 点、線、ポリゴンのオブジェクトを配置し、トポロジー関係を表現。
簡単なクエリを作ってみよう。point_sf の点のうち、ポリゴン polygon_sfc と何らかの形で交差しているものはどれか?
この問題は、見れば答えることができる (点 1 は接していて、点 3 は中にある)。
この質問には、空間についての関数 st_intersects() を用いて、次のように答えることができる。
st_intersects(point_sf, polygon_sfc)
#> Sparse geometry binary predicate... `intersects'
#> 1: 1
#> 2: (empty)
#> 3: 1その結果は、直感と一致するはずである。
1 点目と 3 点目は真 (1)であるが、2 点目は偽 (空のベクタで表される) が返されポリゴンの境界の外にある。
予想外なのは、結果がベクトルのリストという形になっていることだろう。
この出力は疎行列 (sparse matrix) であり、関係が存在する場合にのみ登録され、複数フィーチャに対する位相幾何学的操作のメモリ要件を軽減する。
前節で見たように、TRUE または FALSE の値からなる密な行列 (dense matrix) が返されるのは、sparse = FALSE の時である。
st_intersects(point_sf, polygon_sfc, sparse = FALSE)
#> [,1]
#> [1,] TRUE
#> [2,] FALSE
#> [3,] TRUE上記の出力では、各行がターゲット (引数 x) オブジェクトのフィーチャ、各列が選択オブジェクト (y) のフィーチャを表している。
この場合、y オブジェクト polygon_sfc にはフィーチャが 1 つしかないので、Section 4.2.1 で見たように部分集合に使える結果は 1 列だけである。
st_intersects() は、フィーチャが接触しているだけの場合でも TRUE を返す。intersects は、Figure 4.2 に示されているように、多くのタイプの空間的関係を識別する「全て捕まえる」トポロジー操作である。
Figure 4.2 より限定的な質問としては、どの点がポリゴン内にあるか、どのフィーチャが y と共有の境界線上にあるか、またはそれを含んでいるか、などがある。
こうした問いには、次のように答えることができる (結果は示していない)。
st_within(point_sf, polygon_sfc)
st_touches(point_sf, polygon_sfc)点 1 は境界ポリゴンに接触しているが、境界ポリゴン内にはない。
st_intersects() の反対は st_disjoint() で、これは選択したオブジェクトと空間的に何ら関係のないオブジェクトだけを返す (注: [, 1] は結果をベクトルに変換する)。
st_disjoint(point_sf, polygon_sfc, sparse = FALSE)[, 1]
#> [1] FALSE TRUE FALSE関数 st_is_within_distance() は、選択オブジェクトにほぼ接触しているフィーチャを検出する。この関数には、さらに dist という引数がある。
ターゲットオブジェクトが選択されるまでに必要な距離を設定することができる。
‘is within distance’ という二値空間述語は以下のコードチャンクで示され、その結果、すべての点がポリゴンから 0.2 単位以内にあることが示される。
st_is_within_distance(point_sf, polygon_sfc, dist = 0.2, sparse = FALSE)[, 1]
#> [1] TRUE TRUE TRUE点 2 は polygon_sfc の最も近い頂点から 0.2 単位以上離れているが、距離を 0.2 に設定すると、まだ選択されていることに注意されたい。
これは、距離が最も近い辺まで測定されるためで、この場合、Figure 4.3 の点 2 の真上にあるポリゴンの部分である。
(点 2 とポリゴンの実際の距離が 0.13 であることは、コマンド st_distance(point_sf, polygon_sfc) で確認できる。)
st_join 関数も、空間インデックスを利用している。
詳しくは、以下のサイトを参照。 https://www.r-spatial.org/r/2017/06/22/spatial-index.html
4.2.3 距離関係
前のセクションで示したトポロジー関係はバイナリ (フィーチャが他のフィーチャと交差するかしないか) であるが、距離関係は連続である。
2 つの sf オブジェクト間の距離は st_distance() で計算される。これは、Section 4.2.6 の距離ベースの結合でも裏で使用されている。
これは、Section 4.2.1 で作成された、New Zealand で最も高い地点と Canterbury 地域の地理的な重心との間の距離を求める以下のコードチャンクに示されている。
nz_highest = nz_height |> slice_max(n = 1, order_by = elevation)
canterbury_centroid = st_centroid(canterbury)
st_distance(nz_highest, canterbury_centroid)
#> Units: [m]
#> [,1]
#> [1,] 115540結果について、2 点驚くべき点がある。
-
unitsがある。つまり、 100,000 メートルである。100,000 インチではない。 - 戻り値はたとえ一つでも行列で返る。
この 2 つ目の機能は、st_distance() のもう 1 つの便利な機能である、オブジェクト x と y のすべてのフィーチャの組み合わせ間の距離行列を返す機能を示唆している。
これは、nz_height に含まれる最初の 3 つのフィーチャと、オブジェクト co で表される New Zealand の Otago と Canterbury の地域との間の距離を求める以下のコマンドに示されている。
co = filter(nz, grepl("Canter|Otag", Name))
st_distance(nz_height[1:3, ], co)
#> Units: [m]
#> [,1] [,2]
#> [1,] 123537 15498
#> [2,] 94283 0
#> [3,] 93019 0nz_height の 2 番目と 3 番目のフィーチャーと co の 2 番目のフィーチャ間の距離はゼロであることに注意。
これは、点と多角形の間の距離は、ポリゴンの任意の部分 までの距離を指すという事実を示している。
nz_height の 2 番目と 3 番目の点は Otago の中にあり、プロットすることで確認できる (結果は示していない)。
plot(st_geometry(co)[2])
plot(st_geometry(nz_height)[2:3], add = TRUE)4.2.4 DE-9IM 文字列
前節で示した二項述語の根底には、DE-9IM (Dimensionally Extended 9-Intersection Model) というものがある。 名前からして暗号のようであり、簡単なテーマではない。しかし、空間的な関係をよりよく理解することができ、カスタム空間述語を作成することも可能になる。 このモデルは当初、発明者によって「2 つのフィーチャの境界、内部、外部の交点の次元」を意味する「DE + 9IM」と表示されていたが (Clementini and Di Felice 1995)、現在は「DE-9IM」と表記されている (Shen, Chen, and Liu 2018)。 DE-9IM は、ユークリッド空間の 2 次元オブジェクト (点、線、ポリゴン) に適用される。つまり、このモデル (および GEOS のようなそれを実装したソフトウェア) は、投影座標参照系でデータを扱うことを前提としている。
DE-9IM 文字列がどのように機能するかを示すために、Figure 4.2 の最初のジオメトリペアの様々な関連性を見てみよう。
Figure 4.4 は、各オブジェクトの内部、境界、外部のあらゆる組み合わせの交点を示す 9 交差点モデル (9IM) を示している。最初のオブジェクト x の各コンポーネントを列とし、y の各コンポーネントを行として配置すると、各要素間の交点が強調されたファセット図形が作成される。
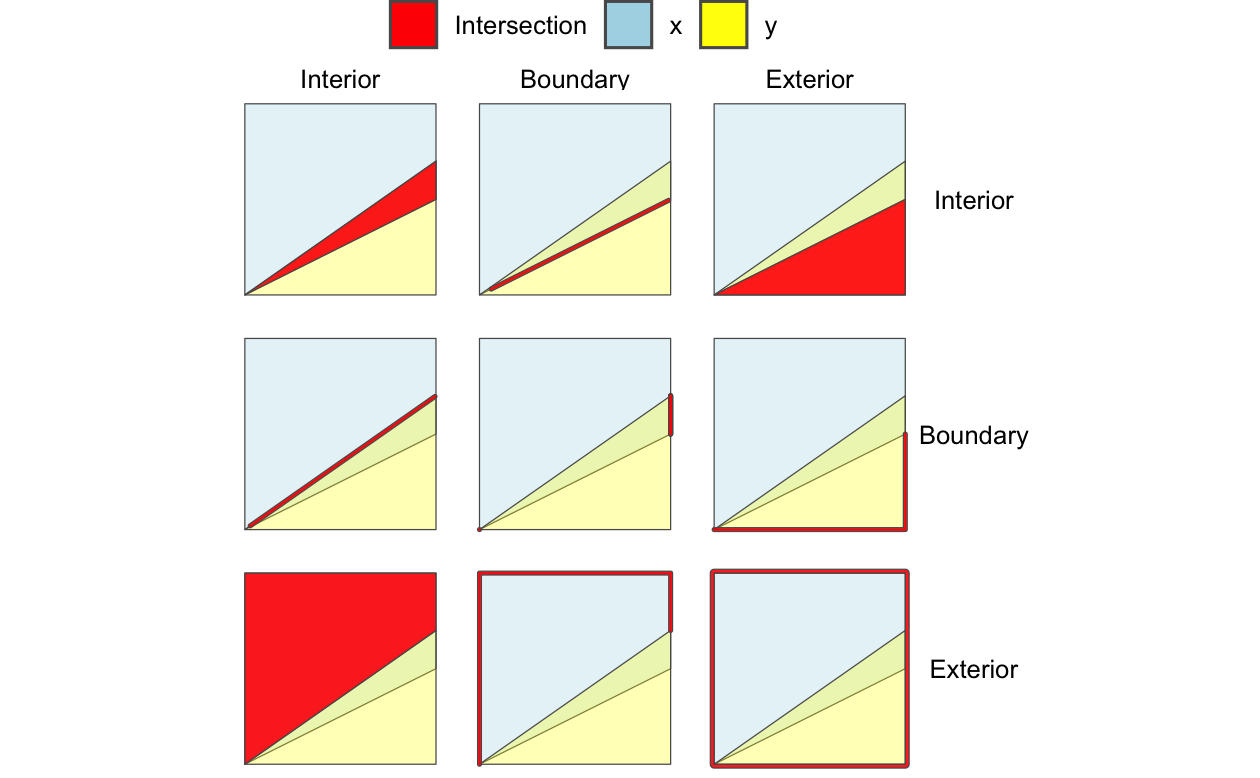
FIGURE 4.4: 次元拡張 9 交差モデル (Dimensionally Extended 9 Intersection Model, DE-9IM) の仕組みを説明する図。凡例にない色は、異なる構成要素間の重なりを表している。太い線は2次元の交わりを強調する。例えば、オブジェクト x の境界とオブジェクト y の内部の交わりは、中央上部のファセットで示されている。
DE-9IM 文字列は、各タイプの関係の次元から導き出される。 この場合、Figure 4.4 の赤い交点は、 Table 4.1 に示すように、0 (点)、1 (線)、2 (ポリゴン) の次元を持つ。
| Interior (x) | Boundary (x) | Exterior (x) | |
|---|---|---|---|
| Interior (y) | 2 | 1 | 2 |
| Boundary (y) | 1 | 1 | 1 |
| Exterior (y) | 2 | 1 | 2 |
この行列を「行単位」で一列にすると (つまり、1 行目、2 行目、3 行目の順に連結する)、文字列 212111212 が得られる。
もうひとつの例で、このシステムを紹介する。
Figure 4.2 に示す関係 (3 列目 1 行目のポリゴンペア) は、DE-9IM システムでは以下のように定義できる。
- 大きなオブジェクト
xの内部とyの内部、境界、外部との交点は、それぞれ 2、1、2 の次元を持つ - 大きなオブジェクト
xの境界とyの内部、境界、外部との交点はそれぞれ F、F、1 の次元を持ち、ここで ‘F’ は ‘false’ を意味し、オブジェクトは不連続である -
xの外部とyの内部、境界、外部との交点はそれぞれ F、F、2 の次元を持つ。大きなオブジェクトの外部はyの内部や境界に接触しないが、小さなオブジェクトと大きなオブジェクトの外部は同じ面積をカバーする
これら 3 つの構成要素を連結すると、文字列 212 , FF1 , FF2 が作成される。
これは、関数 st_relate() で得られた結果と同じである ( Figure 4.2 の他の形状がどのように作成されたかは、この章のソースコードを参照されたい)。
xy2sfc = function(x, y) st_sfc(st_polygon(list(cbind(x, y))))
x = xy2sfc(x = c(0, 0, 1, 1, 0), y = c(0, 1, 1, 0.5, 0))
y = xy2sfc(x = c(0.7, 0.7, 0.9, 0.7), y = c(0.8, 0.5, 0.5, 0.8))
st_relate(x, y)
#> [,1]
#> [1,] "212FF1FF2"DE-9IM 文字列を理解することで、新しい二値空間述語を開発することができる。
ヘルプページ ?st_relate では、チェスの駒を利用して、ポリゴンが境界を共有する「クイーン」 (queen) と点のみを共有する「ルーク」 (rook、将棋でいう飛車と同じ動き、ただし隣接するセルのみ) 関係に対する関数定義がそれぞれ記載されている。
「クイーン」の関係は、「境界-境界」の関係 (Table 4.1 の 2 列目と 2 行目のセル、または DE-9IM 文字列の 5 番目の要素) が空であってはならないという意味で、パターン F***T**** に対応し、「ルーク」の関係では同じ要素が 1 でなければならない (線形交点を意味する) ことを意味している (Figure 4.5 参照)。
これらは以下のように実装されている。
st_queen = function(x, y) st_relate(x, y, pattern = "F***T****")
st_rook = function(x, y) st_relate(x, y, pattern = "F***1****")先に作成したオブジェクト x をベースに、新たに作成した関数を用いて、グリッドの中央のマスに対して、どの要素が「クイーン」「ルーク」であるかを以下のように調べることができる。
grid = st_make_grid(x, n = 3)
grid_sf = st_sf(grid)
grid_sf$queens = lengths(st_queen(grid, grid[5])) > 0
plot(grid, col = grid_sf$queens)
grid_sf$rooks = lengths(st_rook(grid, grid[5])) > 0
plot(grid, col = grid_sf$rooks)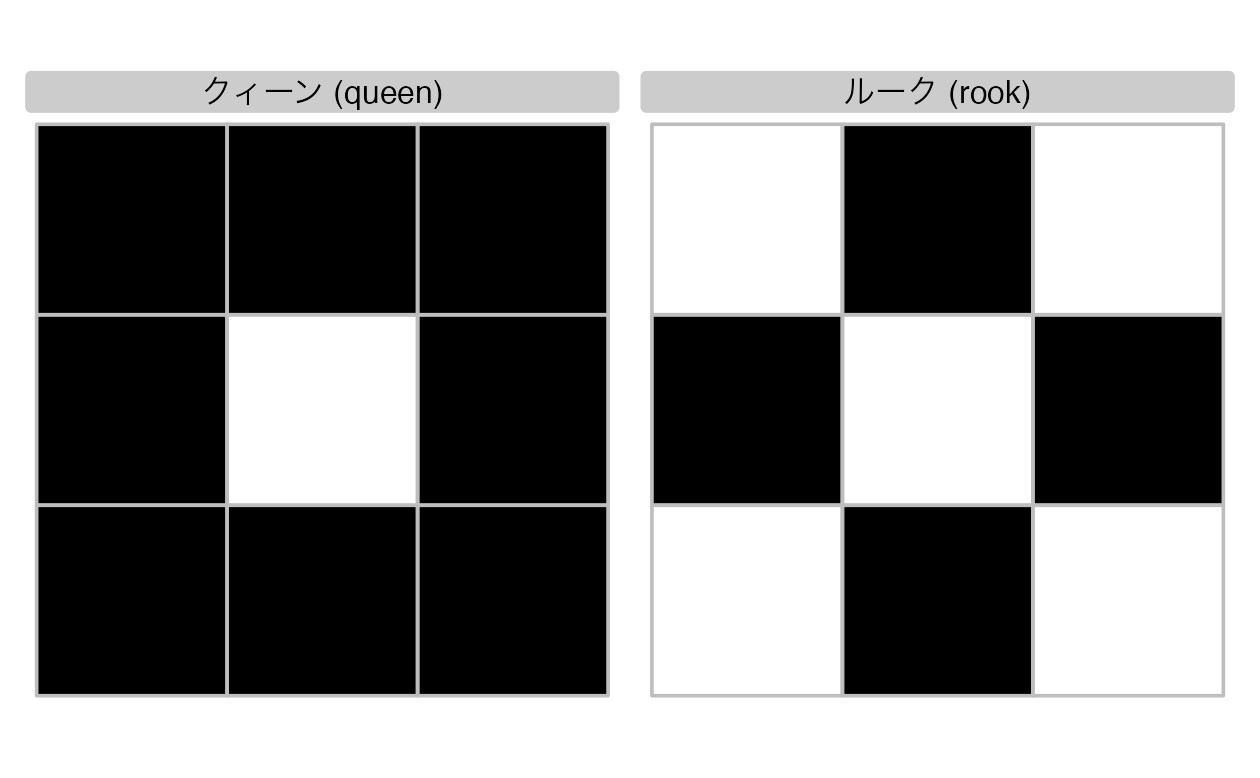
FIGURE 4.5: 9つの形状を持つグリッドの中央の正方形に対する「クイーン」 (左) と「ルーク」 (右) の関係を見つけるためのカスタムバイナリ空間述語のデモ。
4.2.5 空間結合
2 つの非空間データセットを結合する場合、Section 3.2.4 で説明されているように、共有の「キー」変数に依存する。
空間データ結合も概念的には同様であるが、変数ではなく前節で説明した空間関係に依存する。
属性データの場合と同様に、結合では、ソースオブジェクト (y) からターゲットオブジェクト (結合関数の引数 x ) に新しい列を追加する。
例として、地球上にランダムに分布する 10 個の点があり、そのうちの陸地にある点はどの国のものかを調べたいとする。 このアイデアを再現可能な例として実装することで、地理データを扱うスキルが身に付き、空間結合がどのように機能するかを知ることができる。 まず、地表にランダムに散らばる点を作ることから始めよう。
set.seed(2018) # 再現できるように seed を設定
(bb = st_bbox(world)) # 世界の境界
#> xmin ymin xmax ymax
#> -180.0 -89.9 180.0 83.6
random_df = data.frame(
x = runif(n = 10, min = bb[1], max = bb[3]),
y = runif(n = 10, min = bb[2], max = bb[4])
)
random_points = random_df |>
st_as_sf(coords = c("x", "y"), crs = "EPSG:4326") # 座標と CRC を設定Figure 4.6 で示したシナリオでは、random_points オブジェクト (左上) には属性データがないのに対し、world (右上) には凡例で示した国名のサンプルを含む属性があることがわかる。
空間結合は、以下のコードチャンクに示すように、st_join() で実装されている。
出力は、random_joined のオブジェクトで、Figure 4.6 (左下) に図示されている。
結合データセットを作成する前に、空間部分集合を用いて、ランダムな点を含む国だけを含む world_random を作成し、結合データセットで返される国名の数が4であることを検証している ( Figure 4.6 右上)。
world_random = world[random_points, ]
nrow(world_random)
#> [1] 4
random_joined = st_join(random_points, world["name_long"])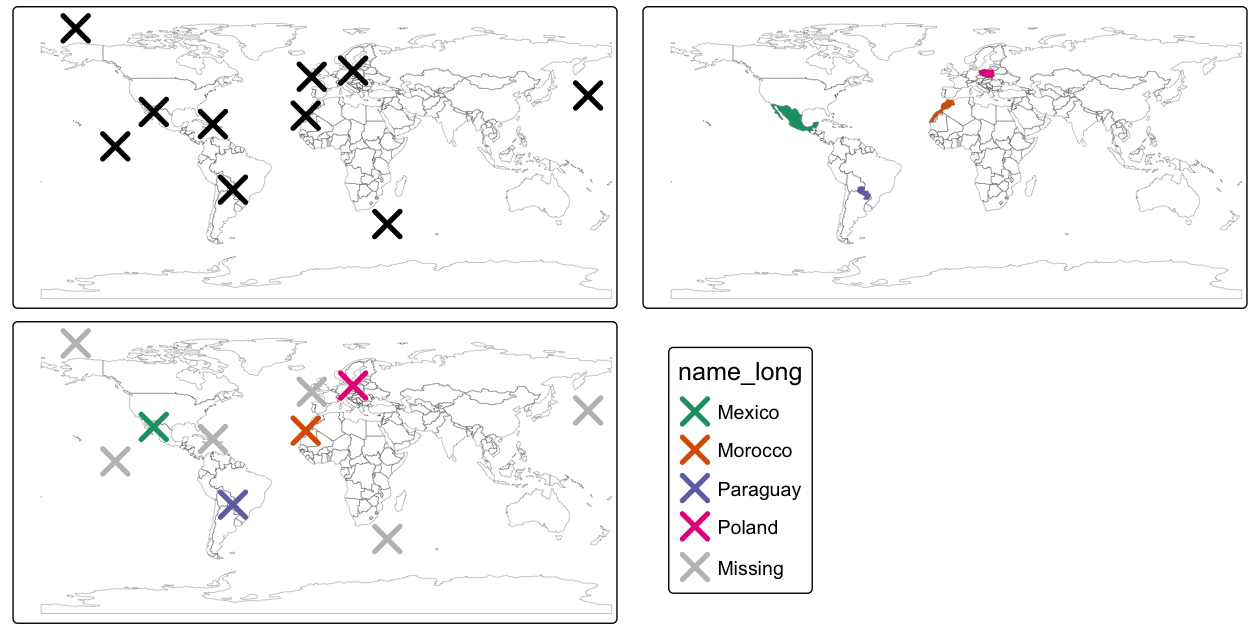
FIGURE 4.6: 空間結合の図解。ソースワールドオブジェクト (右上) からランダムポイント (左上) に新しい属性変数が追加され、最後のパネルで表されるデータになる。
デフォルトでは、st_join() は左結合を行う。つまり、結果は y にマッチしない行を含む x の全ての行を含むオブジェクトとなる (Section 3.2.4 を参照)。Inner Join をする場合には、left = FALSE とする。
空間部分集合と同様に、st_join() で使用されるデフォルトの位相演算子は st_intersects() である。これは join 引数を設定することで変更できる (詳細は ?st_join を参照)。
上の例では、ポリゴンレイヤからポイントレイヤへの列の追加を示しているが、ジオメトリの種類に関係なく同じ方法で行える。
このような場合、例えば x にポリゴンが含まれ、それぞれが y の複数のオブジェクトと一致する場合、空間結合では y の一致するオブジェクトごとに新しい行が作成されるため、重複フィーチャが作られる。
4.2.6 距離結合
2 つの地理データセットが交差 (intersect) していなくても、近接関係により地理的に強い関係がある場合がある。
すでに spData パッケージに含まれているデータセット cycle_hire と cycle_hire_osm が良い例となる。
これらをプロットすると、Figure 4.7 に示すように、しばしば密接に関連しているが、接触していないことがわかる。このベースバージョンは、以下のコードで作成される。
plot(st_geometry(cycle_hire), col = "blue")
plot(st_geometry(cycle_hire_osm), add = TRUE, pch = 3, col = "red")以下のように、同じ点であるかどうかを、st_intersects() を使って確認することができる。
any(st_intersects(cycle_hire, cycle_hire_osm, sparse = FALSE))
#> [1] FALSEFIGURE 4.7: 公式データ (青) とOpenStreetMapのデータ (赤) に基づく、ロンドンにおける自転車レンタルポイントの空間分布。
cycle_hire_osm の変数 capacity を cycle_hire に含まれる公式の「ターゲット」データに結合する必要があるとする。
このとき、オーバーラップしない結合が必要である。
最も簡単な方法は、トポロジカル演算子 st_is_within_distance() を使用することである。これは、下の例で 20 m で示している。
距離は、球面幾何エンジン S2 を使っていれば、非投影座標系 (例えば WGS84 の緯度経度) であってもメートル法を使うことができる。これは、 sf のデフォルトである (Section 2.2.9 参照)。
sel = st_is_within_distance(cycle_hire, cycle_hire_osm,
dist = units::set_units(20, "m"))
summary(lengths(sel) > 0)
#> Mode FALSE TRUE
#> logical 304 438これは、ターゲットオブジェクト cycle_hire の中に、閾値距離 cycle_hire_osm 内に 438 個の点があることを示している。
それぞれの cycle_hire_osm ポイントに関連する値を取得する方法は?
解答は再び st_join() だが、引数 dist を追加する (20 m 以下に設定)。
z = st_join(cycle_hire, cycle_hire_osm, st_is_within_distance,
dist = units::set_units(20, "m"))
nrow(cycle_hire)
#> [1] 742
nrow(z)
#> [1] 762結合結果の行数がターゲットより多いことに注意。
これは、cycle_hire の一部のサイクルレンタル・ステーションが、cycle_hire_osm で複数のマッチングを行っているためである。
Chapter 3 で学習した集約方法を用いると、重なった点の値を集約して平均値を返し、対象と同じ行数を持つオブジェクトが得られる。
z = z |>
group_by(id) |>
summarize(capacity = mean(capacity))
nrow(z) == nrow(cycle_hire)
#> [1] TRUE近くのステーションの収容台数は、ソース cycle_hire_osm のデータの収容台数のプロットとこの新しいオブジェクトの結果を比較することで検証できる (プロットは表示していない)。
この結合の結果、単純なフィーチャの属性データは空間演算で変更されたが、各フィーチャに関連するジオメトリは変更されていない。
4.2.7 空間的な集計
属性データの集約と同様に、空間データの集約では、集約された出力は集約されていない入力よりも少ない行数で済む。
平均値や合計値などの統計的な集約関数は、変数の複数の値を要約し、グループ化変数ごとに単一の値を返す。
Section 3.2.3 は、aggregate() と group_by() |> summarize() が属性変数に基づいてデータを集約する方法を示したが、このセクションでは、同じ関数が空間オブジェクトでどのように機能するかを示す。
aggregate() group_by() |> summarize()
New Zealand の例に戻って、各地域の高所の平均的な高さを求めよう。ソース (この場合は y または nz) のジオメトリが、ターゲットオブジェクト (x または nz_height) の値がどのようにグループ化されるかを定義する。
これは、Base R の aggregate() メソッドで 1 行のコードで書くことができる。
nz_agg = aggregate(x = nz_height, by = nz, FUN = mean)前のコマンドの結果は、 (空間) 集約オブジェクト (nz) と同じジオメトリを持つ sf オブジェクトである。これは、コマンド identical(st_geometry(nz), st_geometry(nz_agg)) で確認することができる。
先の操作の結果を Figure 4.8 に示す。これは、New Zealand の16の地域それぞれにおける nz_height のフィーチャの平均値を示している。
また、次のように st_join() の出力を「tidy」関数 group_by() と summarize() にパイプすることでも、同じ結果を生成することができる。
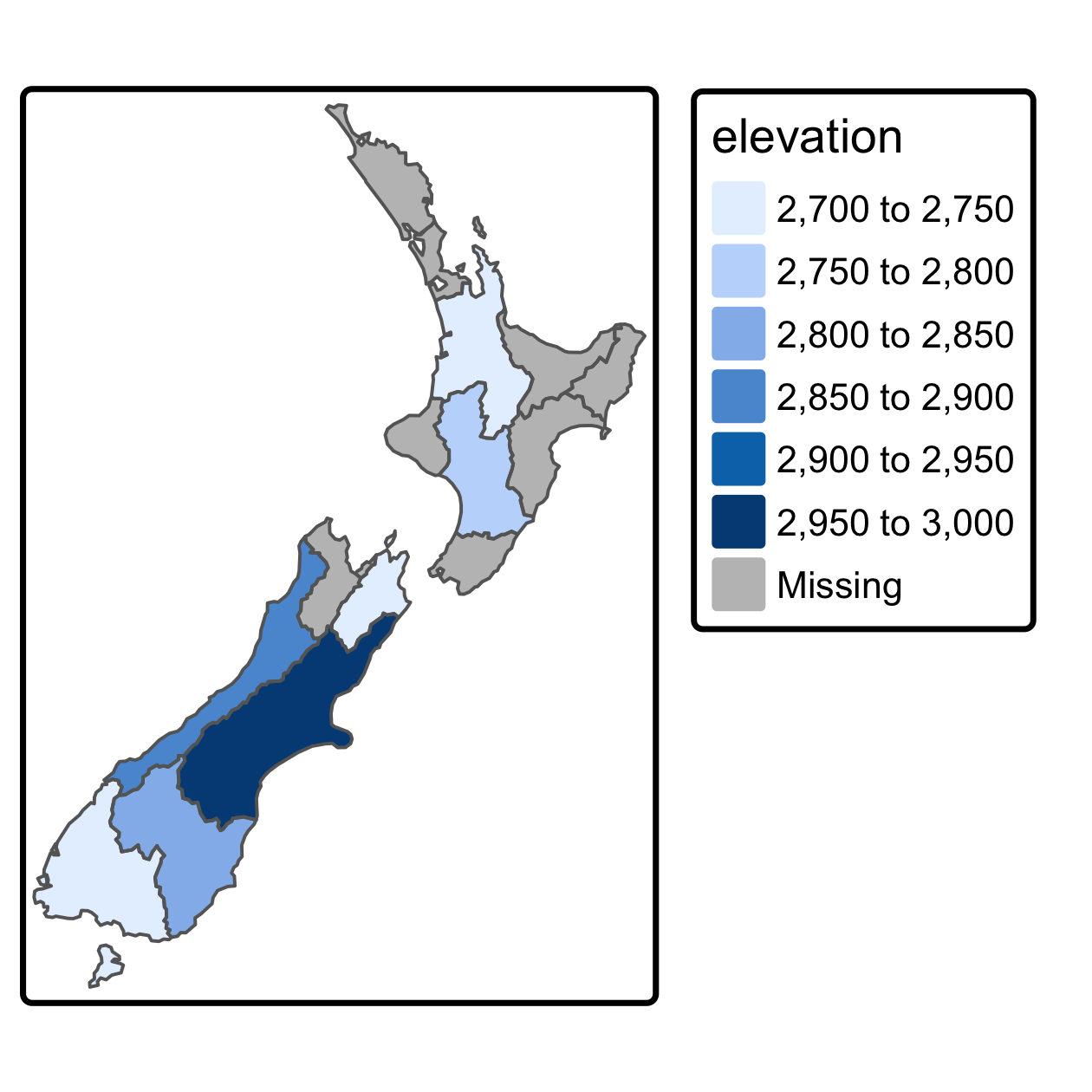
FIGURE 4.8: New Zealand の各地域の上位 101 の高さの平均値。
nz_agg2 = st_join(x = nz, y = nz_height) |>
group_by(Name) |>
summarize(elevation = mean(elevation, na.rm = TRUE))nz_agg オブジェクトは、集計オブジェクト nz と同じジオメトリを持つが、関数 mean() を用いて、各地域の x の値をまとめた列が新たに追加されている。
ここでは、mean() の代わりに、median()、sd() など、グループごとに単一の値を返す他の関数を使用することも可能である。
注: aggregate() と group_by() |> summarize() のアプローチの違いの一つは、前者は一致しない地域名に対して NA の値を返すのに対し、後者は地域名を保持することである。
したがって、「tidy」アプローチは、集計関数や結果の列名の点でより柔軟である。
新しいジオメトリも作成する集計操作については、Section 5.2.7 で説明している。
4.2.8 不一致レイヤを結合
空間一致 (Spatial congruence) は、空間的集計に関連する重要な概念である。
集合体 (ここでは y と呼ぶ) は、2 つのオブジェクトが境界を共有している場合、ターゲットオブジェクト (x) と一致している。
行政区域のデータでは、大きな単位、例えばイギリスの Middle Layer Super Output Area (MSOAs) や他の多くのヨーロッパ諸国の地区が、多くの小さな単位で構成されていることがよくあることである。
対照的に、不一致 (incongruent) 集約オブジェクトは、ターゲットと共通の境界を共有しない (Qiu, Zhang, and Zhou 2012)。 これは、Figure 4.9 で説明されている空間集約 (およびその他の空間操作) において問題となる。各サブゾーンの重心を集約すると、正確な結果を得ることができない。 面積補間は、単純な面積加重法や「ピクノフィラティック」 (pycnophylactic) 法などのより洗練されたアプローチを含む様々なアルゴリズムを使用して、1 セットの面積単位から別の単位に値を転送することによってこの問題を克服している (Waldo R. Tobler 1979)。
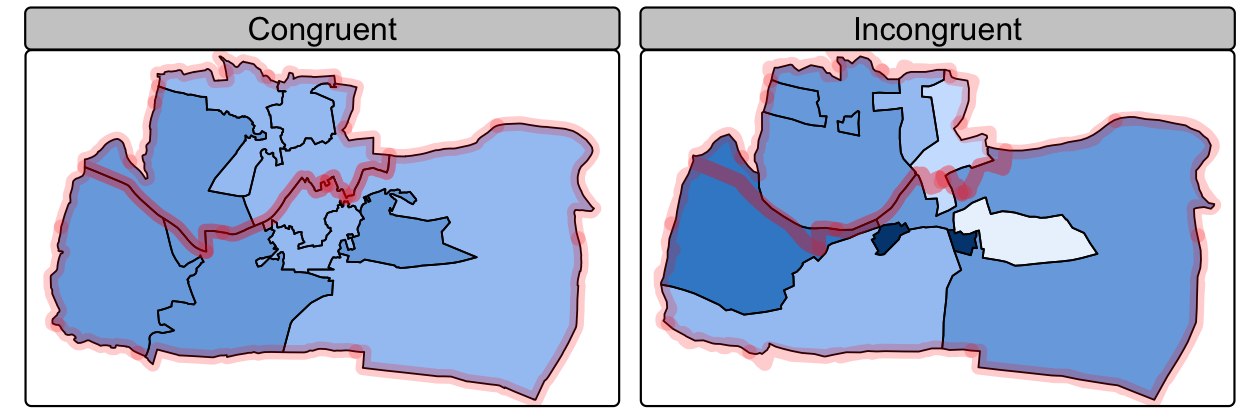
FIGURE 4.9: 大きな凝集帯 (半透明の青い枠) に対して、一致する面単位 (左) と不一致する面単位 (右)。
spData パッケージには、incongruent ( Figure 4.9 の右側のパネルにある黒い縁取りのある色のついたポリゴン) と aggregating_zones ( Figure 4.9 の右側のパネルにある半透明の青い縁取りのある 2 つのポリゴン) という名前のデータセットが含まれている。
ここで、incongruent の value 列が、百万ユーロ単位の地域総所得を指すと仮定しよう。
基礎となる 9 つの空間ポリゴンの値を、aggregating_zones の 2 つのポリゴンにどのように移せばいいのだろうか?
このための最も簡単で有用な方法は、面積加重空間補間で、incongruent オブジェクトから aggregating_zones の新しい列に、重なり合う面積に比例して値を転送する。入力と出力のフィーチャの空間交差が大きければ大きいほど、対応する値も大きくなる。
これは、以下のコードチャンクに示すように、st_interpolate_aw() で実装されている。
iv = incongruent["value"] # 転送する値だけを残す
agg_aw = st_interpolate_aw(iv, aggregating_zones, extensive = TRUE)
#> Warning in st_interpolate_aw.sf(iv, aggregating_zones, extensive = TRUE):
#> st_interpolate_aw assumes attributes are constant or uniform over areas of x
agg_aw$value
#> [1] 19.6 25.7この場合、所得が小さなゾーンに均等に分布していると仮定すると、総所得はいわゆる空間的に広範な変数 (面積とともに増加する) なので、集計ゾーンに入る交差点の値を合計することは意味がある (したがって、上記の警告メッセージが表示されるの)。
これは、平均所得やパーセンテージのような空間的に集中しがちな変数では異なるだろうが、面積が大きくなればなるほど増加するわけではない。
st_interpolate_aw() は、空間的に集約された変数でも同様に動作する。extensive パラメータを FALSE に設定すると、集約の際に合計関数ではなく平均を使用する。
4.3 ラスタデータに対する空間演算
このセクションでは、ラスタデータセットを操作するためのさまざまな基本メソッドを紹介した Section 3.3 をベースに、より高度で明示的な空間ラスタ操作を実演する。また、Section 3.3 で手動で作成したオブジェクト elev と grain を使用する。
これらのデータセットは、読者の便宜を図るため spData パッケージにも含まれている。
elev = rast(system.file("raster/elev.tif", package = "spData"))
grain = rast(system.file("raster/grain.tif", package = "spData"))4.3.1 空間部分集合
前の章 (Section 3.3) では、特定のセル ID や行と列の組み合わせに関連する値を取得する方法を紹介した。
ラスタオブジェクトは、位置 (座標) などの空間オブジェクトを抽出することも可能である。
部分集合に座標を使用するには、terra の関数 cellFromXY() で座標をセル ID に「変換」することができる。
別の方法として、terra::extract() (注意: tidyverse の中にも extract() という関数がある) を使って値を抽出することができる。
以下に、座標 0.1, 0.1 に位置する点を覆うセルの値を求める方法を示す。
id = cellFromXY(elev, xy = matrix(c(0.1, 0.1), ncol = 2))
elev[id]
# the same as
terra::extract(elev, matrix(c(0.1, 0.1), ncol = 2))ラスタオブジェクトは、以下のコードのように、別のラスタオブジェクトの内部に部分集合することもできる。
clip = rast(xmin = 0.9, xmax = 1.8, ymin = -0.45, ymax = 0.45,
resolution = 0.3, vals = rep(1, 9))
elev[clip]
# we can also use extract
# terra::extract(elev, ext(clip))これは、Figure 4.10 に示すように、2 番目のラスタ (ここでは clip) の範囲内にある最初のラスタオブジェクト (この場合は elev) の値を取得することになる。
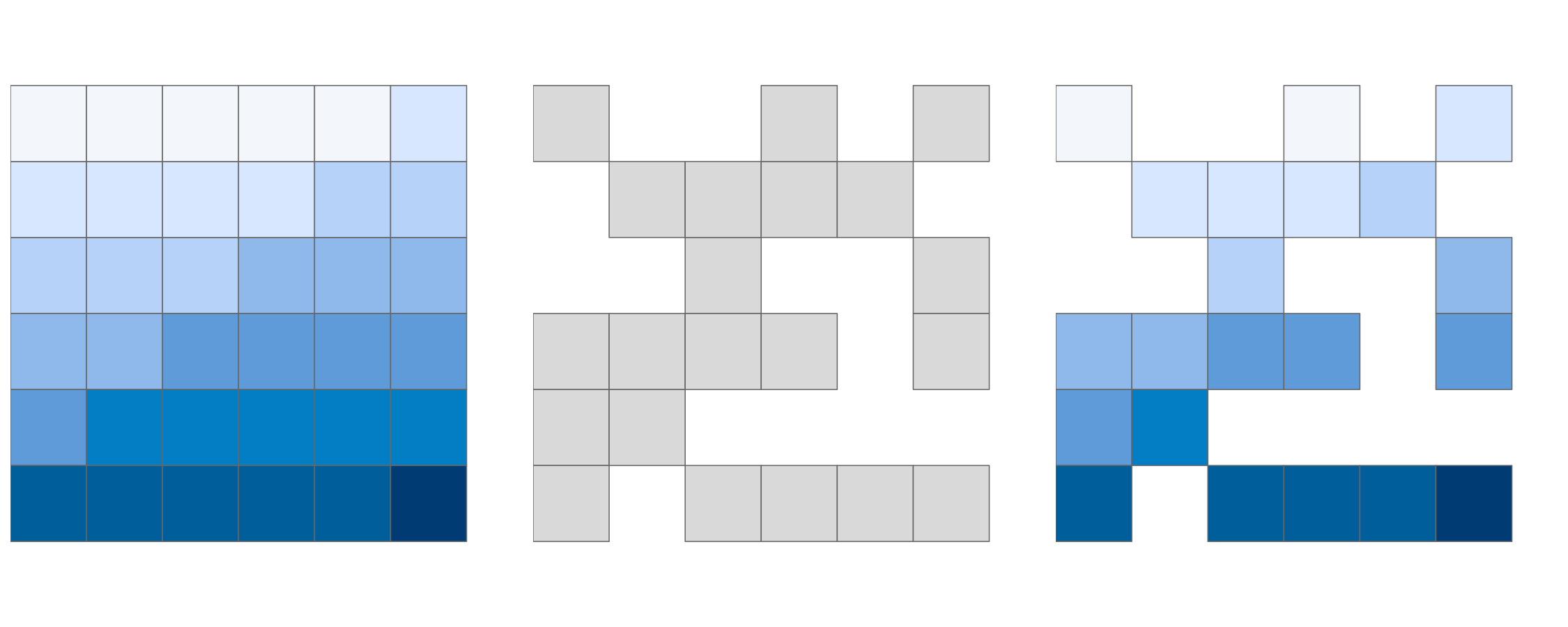
FIGURE 4.10: 元のラスタ (左)、ラスタマスク (中)、ラスタをマスクした出力 (右)。
上記の例では、特定のセルの値を返したが、多くの場合、ラスタデータセットの部分集合操作による空間出力が必要である。
これは、[ 演算子で、drop を FALSE に設定して行うことができる。
以下のコードは、elev の先頭行の 2 つのセル、つまり最初の 2 行をラスタオブジェクトとして返す (出力の最初の 2 行のみ表示)。
elev[1:2, drop = FALSE] # spatial subsetting with cell IDs
#> class : SpatRaster
#> dimensions : 1, 2, 1 (nrow, ncol, nlyr)
#> ...空間部分集合のもう一つの一般的な使用例は、logical (または NA) 値のラスタを使用して、同じ範囲と解像度の別のラスタをマスクする場合である (Figure 4.10 に図示)。
この場合、[、mask() 関数を使用することができる (結果は示していない)。
上記のコードでは、rmask というマスクオブジェクトを作成し、NA と TRUE にランダムな値を割り当てている。
次に、elev のうち、TRUE となる値を rmask に保持したい。
つまり、elev を rmask でマスクしたい。
# 空間的に部分集合を作成
elev[rmask, drop = FALSE] # [ operator を使用
# mask も使うことができる
# mask(elev, rmask)上記の方法は、一部の値 (例えば、間違っていると予想される値) を NA に置き換えるために使用することも可能である。
elev[elev < 20] = NAこれらの操作は、実際のところ、2 つのラスタをセル単位で比較するローカルの論理操作である。 次のサブセクションでは、これらの操作と関連する操作についてより詳しく説明する。
4.3.2 マップ代数
「マップ代数」(map algebra) という用語は、1970年代後半に、地理的なラスタデータおよび (あまり目立たないが) ベクタデータを分析するための「規則、機能、および技術のセット」を表すために作られたものである (Tomlin 1994)。 ここでは、マップ代数をより狭く定義し、周囲のセル、ゾーン、またはすべてのセルに適用される統計関数を参照して、ラスタセル値を修正または要約する操作としている。
ラスタデータセットは暗黙的に座標を保存しているだけなので、マップ代数演算は高速になる傾向があり、そのため古いことわざでは「ラスタは高速だがベクタは補正が効く」とされている。 ラスタデータセットのセルの位置は、その行列の位置と、データセットの解像度および原点 (ヘッダに格納) を使用して計算することができる。 しかし、処理にあたっては、処理後のセル位置が変わらないことを確認すれば、セルの地理的な位置はほとんど関係ない。 さらに、2つ以上のラスタデータセットが同じ範囲、投影、解像度を共有している場合、それらを行列として処理することができる。
これは、マップ代数が terra パッケージで動作する方法である。 まず、ラスタデータセットのヘッダを照会し、 (マップ代数演算が複数のデータセットに対して行われる場合) データセットの互換性を確認する。 第二に、マップ代数はいわゆる一対一の位置対応を保持しており、セルは移動できないことを意味している。 これは、行列の掛け算や割り算などで値の位置が変わる行列代数とは異なる。
マップ代数 (またはラスタデータによる地図作成) では、ラスタ操作を4つのサブクラスに分け (Tomlin 1990)、それぞれが1つまたは複数のグリッドを同時に処理するようにしている。
- ローカル (Local)、つまりセル単位の操作
- フォーカル (Focal)、つまり近傍 (Nighborhood) オペレーション。 多くの場合、出力セルの値は、3×3 の入力セルブロックの結果
- ゾーン (Zonal) 演算は、フォーカル演算と似ているが、新しい値を計算する周囲の画素グリッドは不規則なサイズと形状を持つことができる。
- グローバル (Global) またはラスタ単位の操作。 つまり、出力セルは 1 つまたは複数のラスタ全体から潜在的にその値を引き出す。
このトポロジーは、マップ代数演算を、各ピクセル処理ステップに使用するセル数と出力の種類によって分類したものである。 なお、ラスタ演算は、地形、水文解析、画像分類などの分野ごとの分類方法もある。 以下では、各タイプのマップ代数演算の使用方法について、動作例を参照しながら説明する。
4.3.3 ローカル操作
ローカル操作は、1 つまたは複数のレイヤにおけるすべてのセル単位の操作で構成されている。 これには、ラスタからの値の加算や減算、ラスタの二乗や乗算が含まれる。 ラスタ代数では、特定の値 (下の例では 5) より大きいラスタセルをすべて見つけるなどの論理演算も可能である。 terra パッケージは、以下のように、これらすべての操作に対応している (Figure 4.11)。
elev + elev
elev^2
log(elev)
elev > 5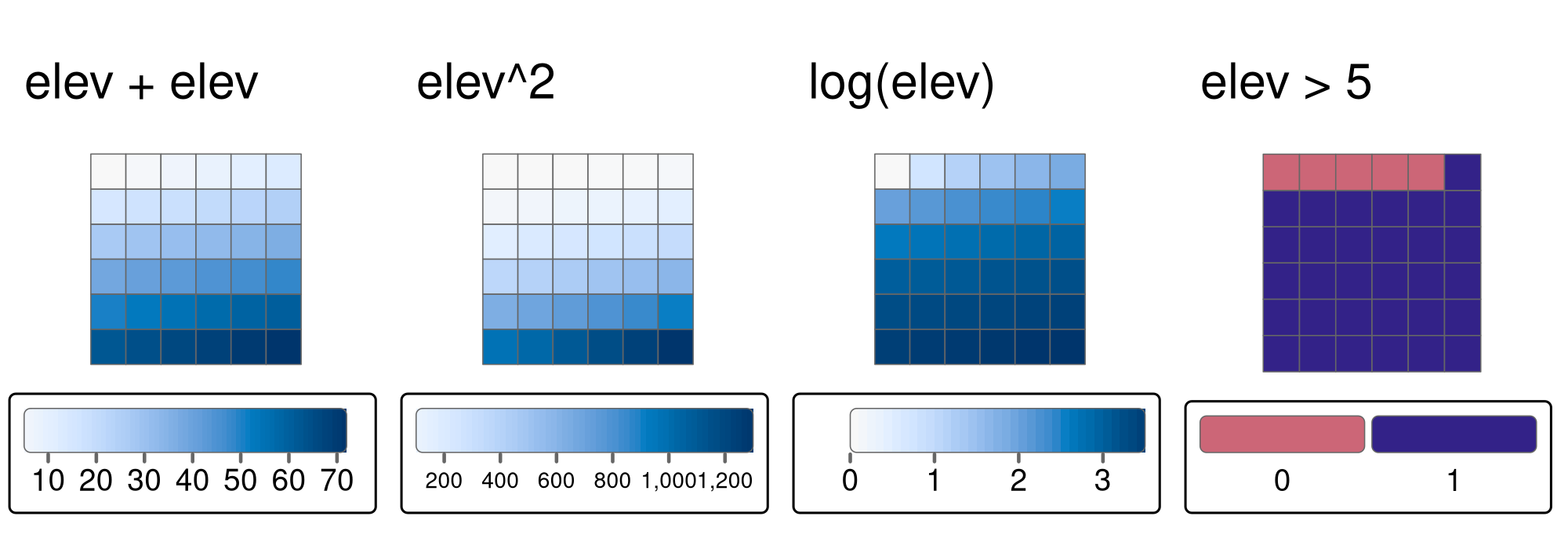
FIGURE 4.11: elev ラスタオブジェクトのさまざまなローカル操作の例: 2つのラスタの加算、二乗、対数変換の適用、論理演算の実行。
ローカル演算のもう一つの良い例は、デジタル標高モデルを低標高 (クラス 1)、中標高 (クラス 2)、高標高 (クラス 3) にグループ化するように、数値の間隔をグループに分類することである。
classify() コマンドを使って、まず再分類行列を作る必要がある。ここで、最初の列はクラスの下限、2 番目の列は上限に対応する。
3 列目は、1 列目と 2 列目で指定した範囲の新しい値を表している。
rcl = matrix(c(0, 12, 1, 12, 24, 2, 24, 36, 3), ncol = 3, byrow = TRUE)
rcl
#> [,1] [,2] [,3]
#> [1,] 0 12 1
#> [2,] 12 24 2
#> [3,] 24 36 3ここでは、0~12、12~24、24~36 の範囲のラスタ値をそれぞれ 1、2、3 に再分類している。
recl = classify(elev, rcl = rcl)classify() 関数は、カテゴリ別ラスタのクラス数を減らしたい場合にも使用できる。
Chapter 14 では、いくつかの追加的な再分類を実施する予定である。
直接算術演算子するだけでなく、app()、tapp()、lapp() 関数も使用することができる。
より効率的であるため、大規模なラスタデータが存在する場合に適している。
さらに、出力ファイルを直接保存することも可能である。
関数 app() は、ラスタの各セルに関数を適用し、複数のレイヤの値を 1 つのレイヤにまとめる (合計を計算するなど) ために使用される。
tapp() は、app() の拡張で、ある操作を行いたいレイヤの部分集合 (index の引数を参照) を選択することができるようになっている。
最後に、関数 lapp() は、レイヤを引数として各セルに関数を適用することができる。lapp() のアプリケーションを以下に示す。
正規化差分植生指数 (normalized difference vegetation index, NDVI) の算出は、よく知られたローカル (ピクセル単位) のラスタ処理である。 正の値は生きた植物が存在することを示す(ほとんどが 0.2 以上)。 NDVI は、Landsat や Sentinel などの衛星システムから得られるリモートセンシング画像の赤色および近赤外 (near-infrared、NIR) バンドから算出されるものである。 植物は可視光線、特に赤色光を強く吸収し、近赤外光を反射する。以下は、NDVI の式である。
\[ \begin{split} NDVI&= \frac{\text{NIR} - \text{Red}}{\text{NIR} + \text{Red}}\\ \end{split} \]
Zion 国立公園のマルチスペクトル衛星ファイルについて、NDVI を計算してみよう。
multi_raster_file = system.file("raster/landsat.tif", package = "spDataLarge")
multi_rast = rast(multi_raster_file)ラスタオブジェクトは、Landsat 8 からの青、緑、赤、近赤外 (NIR) の 4 つの衛星バンドを持っている。 重要なのは、Landsat レベル 2 のプロダクトはディスクスペースを節約するために整数として保存されているため、計算を行う前に浮動小数点数に変換する必要があるということだ。 そのためには、スケーリング係数 (0.0000275) を適用し、元の値にオフセット (-0.2) を加える必要がある。21
multi_rast = (multi_rast * 0.0000275) - 0.2適切な値は 0 から 1 の範囲になければならない。 実際には範囲外のデータがあるが、その原因はおそらく雲やその他の大気の影響によるものだと思われる。 以下の通り、負値を 0 に置き換える。
multi_rast[multi_rast < 0] = 0次のステップは、NDVI の計算式を R の関数に実装することである。
ndvi_fun = function(nir, red){
(nir - red) / (nir + red)
}この関数は、2 つの数値引数 (nir と red) を受け取り、NDVI 値を含む数値ベクトルを返す。
lapp() の fun 引数として使用することができる。
この関数が想定するのは 2 つのバンド (元のラスタの 4 つではない) であり、それらは NIR、赤の順である必要があることを覚えておく必要がある。
そのため、入力ラスタを部分集合し、計算を行う前に multi_rast [[c(4, 3)] ] で部分集合してから計算を行う。
その結果を右図 (Figure 4.12 ) に示すように、同じ領域の RGB 画像 (同図の左図) と比較することができる。 これにより、NDVI 値が最も大きいのは北部の密林地帯、最も低いのは北部の湖と雪山の尾根に関連していることがわかる。

FIGURE 4.12: Zion 国立公園の衛星ファイルの例で計算された RGB 画像 (左) と NDVI 値 (右)
予測マッピングも、ローカルラスタ操作の興味深い応用例である。
応答変数は、例えば、種の豊富さ、地滑りの存在、木の病気、作物の収穫量など、空間における測定または観測された点に対応する。
その結果、様々なラスタ (標高、pH、降水量、気温、土地被覆、土壌等級など) から、宇宙や空中の予測変数を簡単に取得することができるようになる。
その後、lm()、glm()、gam() または機械学習技術を使用して、予測因子の関数として応答をモデル化する。
したがって、ラスタオブジェクトの空間予測は、予測ラスタ値に推定係数を適用し、出力ラスタ値を合計することで行うことができる (Chapter 15 を参照)。
4.3.4 フォーカル操作
ローカルな機能とは、1 つのセル (複数の層からなる可能性もある) を対象とするものであるのに対し、フォーカルな機能とは、中心 (焦点) のセルとその近隣のセルを考慮したものである。 近傍領域 (カーネル、フィルタ、移動窓とも呼ばれる) は、通常、3×3 セル (つまり、中心セルとその周囲 8 個の近傍セル) のサイズであるが、ユーザーが定義する他のサイズや形状 (必ずしも長方形ではない) をとることができる。 フォーカル操作は、指定された近傍領域内のすべてのセルに集約関数を適用し、対応する出力を中心セルの新しい値として使用し、次の中心セル (Figure 4.13) へと進む。 この操作は、空間フィルタリング (spatial filtering) や畳み込み (convolution) などと呼ばれることもある (Burrough, McDonnell, and Lloyd 2015)。
R では、focal() 関数で空間フィルタリングを行うことができる。
移動窓の形状を matrix で定義する。その値は重みに対応する (以下のコードチャンクの w パラメータを参照)。
次に、fun パラメータで、この近傍領域に適用したい関数を指定することができる。
ここでは、最小値を選んでいるが、sum()、mean()、var() など、他の要約関数も使用可能である。
main() 関数は、プロセス中の NA を削除すべきか (na.rm = TRUE)、しないか (na.rm = FALSE こちらがデフォルト) などの追加引数も受け付ける。
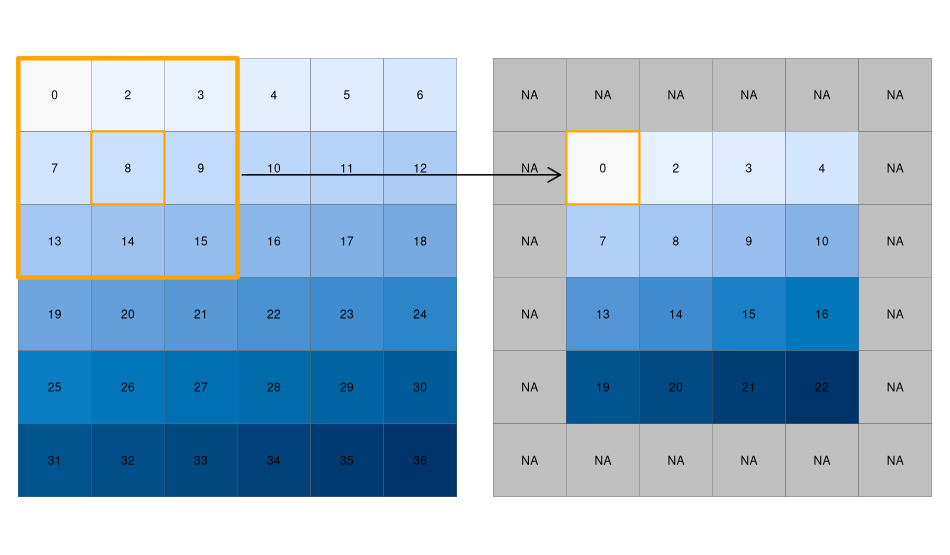
FIGURE 4.13: 焦点演算による入力ラスタ (左) と出力ラスタ (右) -3×3の移動窓で最小値を求める。
期待通りの出力が得られるかどうか、すぐに確認することができる。 この例では、最小値は常に移動窓の左上隅でなければならない (入力ラスタは、左上隅から始まるセルの値を行単位で1つずつ増加させることによって作成したことを思い出してほしい)。 この例では、重み付け行列は 1 だけで構成されており、各セルの出力に対する重みが同じであることを意味しているが、これは変更可能である。
画像処理では、焦点関数やフィルタが重要な役割を担っている。
ローパスフィルタやスムージングフィルタは、平均関数を用いて極端な部分を除去する。
カテゴリデータの場合、平均値を最頻値に置き換えることができる。
それに対して、ハイパスフィルタはフィーチャを強調する。
ここでは、ライン検出のラプラスフィルタやソーベルフィルタがその例として挙げられるだろう。
R での使い方は、focal() のヘルプページで確認してみよう (この章の最後の演習でも使用する)。
傾斜、アスペクト、流れ方向などの地形特性を計算する地形処理では、焦点関数に依存している。
terrain() は、これらの指標の計算に使用することができる。ただし、勾配を計算する Zevenbergen and Thorne 法を含むいくつかの地形アルゴリズムは、この terra 関数には実装されていない。
その他、曲率、寄与率、湿潤指数など多くのアルゴリズムが、オープンソースのデスクトップ型地理情報システム (GIS) ソフトウェアに実装されている。
Chapter 10 は、このような GIS 機能を R 内からアクセスする方法を示している。
4.3.5 ゾーン操作
ゾーン演算は、フォーカル演算と同様に、複数のラスタセルに集計関数を適用する。 しかし、前節で紹介したフォーカル操作の場合の近傍窓とは対照的に、ゾーン操作の場合は、通常カテゴリ値で構成される第二ラスタがゾーンフィルター/u> (または「ゾーン」) を定義する。 そのため、ゾーンフィルタを定義するラスタセルは、必ずしも隣接している必要はない。 粒径ラスタはその良い例で、Figure 3.2 の右側のパネルに示されているように、異なる粒径がラスタ全体に不規則に広がっていることがわかる。 最後に、ゾーン操作の結果は、ゾーンごとにグループ化された要約表となる。このため、この操作は、GIS の世界ではゾーン統計とも呼ばれる。 これは、デフォルトでラスタオブジェクトを返すフォーカルオペレーションとは対照的である。
次のコードチャンクは、zonal() 関数を使用して、各粒度クラスに関連する平均標高を計算する。
z = zonal(elev, grain, fun = "mean")
z
#> grain elev
#> 1 clay 14.8
#> 2 silt 21.2
#> 3 sand 18.7これは、各カテゴリの統計値 、ここでは各粒度クラスの平均高度を返す。
注: as.raster 引数を TRUE に設定することで、各ゾーンの統計情報を計算したラスタを取得することも可能である。
4.3.6 グローバルな操作と距離
グローバル操作は、ラスタデータセット全体が 1 つのゾーンに相当するゾーン操作の特殊なケースである。 最も一般的なグローバル操作は、最小値や最大値など、ラスタデータセット全体の記述統計である。これらの操作については、Section 3.3.2 ですでに説明した。
それ以外にも、距離や重みのラスタの計算にもグローバル操作は有効である。
最初のケースでは、各セルから特定のターゲットセルまでの距離を計算することができる。
例えば、最も近い海岸までの距離を計算したい場合がある (terra::distance() も参照)。
また、地形も考慮したい。つまり、純粋な距離だけでなく、海岸に行くときに山脈を越えないようにしたいのである。
そのためには、標高が 1 メートル増えるごとにユークリッド距離が「伸びる」ように、標高で距離に重みをつければよい (この章の演習 E8 と E9 で実際に行う。)。
Visibility と viewshed の計算もグローバル操作に属する (Chapter 10 の演習では、viewshed ラスタを計算する)。
4.3.7 ベクタ処理における写像代数の対応
多くのマップ代数演算はベクタ処理に対応するものである (Liu and Mason 2009)。
最大距離のみを考慮した距離ラスタの計算 (グローバル演算) は、ベクタバッファ演算 (Section 5.2.5) と同等である。
ラスタデータの再分類 (入力に応じてローカルまたはゾーン関数) は、ベクタデータの融合 (dissolve) (Section 4.2.5) と同等である。
2 つのラスタを重ね合わせ (ローカル操作)、一方がマスクを表す NULL または NA の値を含む場合、ベクタクリッピング (Section 5.2.5) に類似している。
空間クリッピングとよく似たものに、2 つのレイヤを交差させるものがある (Section 4.2.1 )。
違いは、これら 2 つのレイヤ (ベクタまたはラスタ) は、単に重複する領域を共有することである (例として Figure 5.8 を参照)。
ただし、表現には注意が必要である。
ラスタデータモデルとベクタデータモデルでは、同じ言葉でも微妙に意味が異なることがある。
集計とは、ベクタデータの場合はポリゴンを分解することであり、ラスタデータの場合は解像度を上げることである。
ゾーン演算は、あるラスタのセルを、別のラスタのゾーン (カテゴリ) に合わせて、集約関数 (上記参照) を使って分解することができる。
4.3.8 ラスタのマージ
NDVI を計算し (Section 4.3.3 参照)、さらに、調査地域内の観測の標高データから地形属性を計算したいとする。
このような計算には、リモートセンシングの情報が必要である。
リモートセンシング画像は、特定の空間範囲をカバーするシーンに分割されることが多く、1つの調査エリアが複数のシーンにまたがっていることがよくある。
そして、調査対象シーンをマージする必要がある。
一番簡単なのは、これらのシーンをマージする、つまり並べることである。
これは例えば、デジタル標高データで可能である。
以下のコードでは、まずオーストリアとスイスの Shuttle Radar Topography Mission (SRTM) 標高データをダウンロードする (国番号については、geodata 関数 country_codes() を参照)。
第二段階では、2 つのラスタを 1 つに統合する。
aut = geodata::elevation_30s(country = "AUT", path = tempdir())
ch = geodata::elevation_30s(country = "CHE", path = tempdir())
aut_ch = merge(aut, ch)terra の merge() コマンドは、2 つの画像を合成し、重なった場合は、最初のラスタの値を使用する。
重複する値が互いに対応しない場合、マージはほとんど意味がない。
このようなケースは、撮影日が異なるシーンの分光画像を合成する場合によくある。
merge() コマンドはそのまま使え、出来上がった画像にはっきりとした枠が表示される。
一方、mosaic() コマンドでは、オーバーラップする領域に対して関数を定義することができる。
例えば、平均値を計算することもできる。この場合、マージされた結果における明確な境界線は滑らかになるだろうが、ほとんどの場合、それを消すことはできない。
R によるリモートセンシングの詳しい紹介は、Wegmann, Leutner, and Dech (2016) を参照。
4.4 演習
E1. Canterbury は、New Zealand の最高峰 101 地点のほとんどを含む地域であることは、Section 4.2 で述べたとおりである。 Canterbury 地方には、これらの高地がいくつあるだろうか?
ボーナス: その結果を plot() 関数を使って次のように表示しなさい。、まず、New Zealand 全土を示し、canterbury 地域を黄色で強調し、高地を赤い十字 (ヒント: pch = 7)、かつ他の地域の高地は青い円で表示しなさい。異なる pch 値の図解を含む詳細については、ヘルプページ ?points を参照。
E2. nz_height高地の数が 2 番目に多いのはどの地方で、いくつあるか?
E3. この質問を全地域に一般化すると、ニュージーランドの 16 地方のうち、国内最高地点トップ 100 に属する地点を含む地域はいくつあるか? どの地方か?
- ボーナス: これらの地域を、点の数と名前の順に並べた表を作成しなさい。
E4. 空間述語の知識を試すために、アメリカの州と他の空間オブジェクトとの関係を調べ、プロットしてみよう。
この練習の出発点は、アメリカのコロラド州を表すオブジェクトを作成することである。次のコマンドで実行する。
colorado = us_states[us_states$NAME == "Colorado",] (base R)、または filter() 関数 (tidyverse) を使って、結果のオブジェクトをアメリカの州のコンテキストでプロットしなさい。
- Colorado 州と地理的に交差するすべての州を表す新しいオブジェクトを作成し、その結果をプロットしなさい (ヒント: これを行う最も簡潔な方法は、部分集合化メソッド
[] を使用する)。 - Colorado 州に接する (境界を共有する) すべてのオブジェクトを表すもう 1 つのオブジェクトを作成し、その結果をプロットしなさい (ヒント: Base R の空間部分集合操作中に、引数
op = st_intersectsやその他の空間関係を使用できる)。 - ボーナス: 東海岸に近い Columbia 特別区の重心から、アメリカの西海岸に California 州の重心までの直線を作成し(ヒント: Chapter 5 で説明した関数
st_centroid()、st_union()、st_cast()が役に立つ)、この東西に長い直線がどの州を横切るかを特定しなさい。
E5. dem = rast(system.file("raster/dem.tif", package = "spDataLarge")) を使用し、標高を低 (<300)、中、高 (>500) の 3 つのクラスに再分類しなさい。
次に、NDVI ラスタ(ndvi = rast(system.file("raster/ndvi.tif", package = "spDataLarge"))) を読み込み、各標高クラスの平均 NDVI と平均標高を計算しなさい。
E6. rast(system.file("ex/logo.tif", package = "terra")) にライン検出フィルタを適用しなさい。
結果をプロットしなさい。
ヒント: ?terra::focal() を読むと良い。
E7. ランドサット画像の正規化差分水分指数 (Normalized Difference Water Index; NDWI; (green - nir)/(green + nir)) を計算しなさい。
spDataLargeパッケージが提供するランドサット画像を使用しなさい (system.file("raster/landsat.tif", package = "spDataLarge"))。
また、このエリアの NDVI と NDWI の相関を計算しなさい (ヒント: layerCor() 関数を使用できる)。
E8. StackOverflow の投稿では、raster::distance() を使って最も近い海岸線までの距離を計算する方法が紹介されている。
似たようなことを terra::distance() を使ってやってみよう。 Spain のデジタル標高モデルを取得し、全国の海岸までの距離を表すラスタを計算しなさい (ヒント: geodata::elevation_30s() を使う)。
得られた距離をメートルからキロメートルに変換しなさい。
注意: 操作 (aggregate()) の計算時間を短縮するために、入力ラスタのセルサイズを大きくすることが賢明かもしれない。
E9. 距離ラスタを標高ラスタで加重することによって、上記の演習で使用したアプローチを修正しなさい。100 高度メートルごとに、海岸までの距離が 10 km 増加する。 次に、ユークリッド距離 (E7) を使って作成したラスタと標高で重み付けしたラスタの差を計算し、可視化しなさい。