10 GIS ソフトウェアへのブリッジ
必須パッケージ
- 本章では、QGIS、SAGA、GRASS GIS がインストールされていること、および以下のパッケージが添付されていることを条件とする。
#> Warning: package 'sf' was built under R version 4.3.3
#> Warning: package 'terra' was built under R version 4.3.310.1 イントロダクション
対話式コンソールを使うインタプリタ言語の特徴は、その対話の方法にある。技術的には、入力・評価・出力 (read-evaluate-print loop, REPL) と言い、R もその一つである。
マウスで画面上のさまざまな場所をクリックする代わりに、コマンドを入力し、Enter を押すことで、コマンドを実行する。
RStudio や VS Code などの対話型開発環境を使った作業では、通常ソースエディタでソースファイルに書き込み、Ctrl+Enter などのショートカットキーでコードの対話的実行を制御する。
Command Line Interface (CLI) は R だけのものではない。初期のコンピュータ環境は、おおむねコマンドライン「シェル」に依存しており、GUI が一般的になったのは、コンピューターのマウスが普及した1990年代以降のことである。 例えば、最も長い歴史を持つ GIS プログラムの一つである GRASS GIS は、洗練された GUI (Landa 2008) を獲得するまでは、主にコマンドラインでの対話に依存していた。 ほとんどの GIS パッケージは、グラフィカルユーザーインターフェース (Grafical User Interface, GUI) を採用している。 QGIS、SAGA、GRASS GIS、gvSIG を、システムターミナルや組み込み CLI から操作することも可能であるが、「マウス操作」が一般的である。 これは多くの GIS ユーザーがコマンドラインの利点を見逃していることを意味する。 QGIS (Sherman 2008) の作成者によれば、
「近代的」GIS ソフトウェアの発展に伴い、マウス操作を好む人がほとんどである。それはいいことであるが、コマンドラインには、とてつもない量の柔軟性とパワーが待っている。繰り返しコマンドラインで作業をする場合、同じことを GUI で行う場合よりも短い時間で行うことができる。
「CLI vs GUI」 の議論は、敵対的になる必要はない。作業の内容 (フィーチャを描く時は GUI の方が優れている)、再現可能性、ユーザーのスキルセットに応じて、どちらの選択肢も利点はある。 GRASS GIS は、CLI をベースとしながらも GUI がある GIS の良い例である。 同様に、R は CLI であり、そして RStudio のような IDE が GUI を提供することで、アクセシビリティを向上している。 このように、ソフトウエアは CLI または GUI というように完全に分けられるものではない。 しかしながら、CLI は以下のような重要な点があることは押さえておきたい。
- 繰り返し作業の自動化
- 透明性と再現性を可能にする
- 既存の機能を修正したり、新しい機能を実装するためのツールを提供することで、ソフトウェア開発を促進する
- 将来性があり、かつ効率的なプログラミングスキルを身につけることができる
- デジタル時代に必須のタッチタイピング
一方、GUI ベースの GIS システムにも有利な点がある。
- 学習曲線が「浅い」ので、新しい言語を何時間も学ぶことなく、地理データを探索し、可視化することができる
- トレース、スナップ、トポロジーツールなど、「デジタイジング」 (新しいベクタデータセットの作成) のための優れたサポートを提供する56
- 地上基準点によるジオリファレンス (georeference、ラスタ画像と既存地図とのマッチング)、オルソ補正 (orthorectification) が可能である
- 立体視マッピング (LiDAR、Structure from Motion など) に対応する
専用 GIS のもう一つの利点は、「GIS ブリッジ」を経由して何百もの「ジオアルゴリズム」 を利用できることである (Neteler and Mitasova 2008) 。 ブリッジを通して R の機能を拡張し、地理データ問題を解決することが本章のテーマである。
bash や Windows の PowerShell が、OS のほとんど全てを制御するコマンドラインの代表例である。
CLI は、RStudio や VS Code のような IDE で補強することができ、コードの自動補完やユーザーエクスペリエンスを向上させる機能を提供する。
R はインターフェース言語として誕生したため、再現可能なデータ分析と GIS をつなぐブリッジを構築する選択肢として当然のごとく選ばれた。 R (および、その前身である S) は、他の言語 (特に FORTRAN と C) の統計アルゴリズムへのアクセスを提供しており、また C と FORTRAN にはない高レベルの REPL 環境からアクセスできるようになっていた (Chambers 2016)。 R はこの伝統を受け継ぎ、特に C++ などの多くの言語へのインタフェースを提供している。
R は GIS として設計されたものではない。しかし、専用の GIS とのインターフェースが可能なため、驚異的な地理空間能力を発揮する。 GIS ブリッジを通すことで、R はさまざまな作業を実行でき、さらには CLI の持っている再現可能性、拡張性、生産性といった付加価値をもたらす。 さらに、R は、インタラクティブ地図/地図アニメーション作成 (Chapter 9 参照) や空間統計モデリング ( Chapter 12 参照) など、ジオコンピュテーションのいくつかの分野では GIS を凌駕する性能を有している。
この章では、Table 10.1 にまとめた 3 つの成熟したオープンソース GIS 製品への「ブリッジ」に焦点を当てる。
- QGIS qgisprocess; [Dunnington et al. (2024); Section 10.2]
- SAGA Rsagacmd; [Pawley (2023); Section 10.3]
- GRASS GIS rgrass; [Bivand (2023); Section 10.4]
また、QGIS (docs.qgis.org 参照) や GRASS GIS (grasswiki.osgeo.org 参照) など GIS から R を実行する環境も開発されている。
| GIS | 最初のリリース | 機能数 | Support |
|---|---|---|---|
| QGIS | 2002 | >1000 | hybrid |
| SAGA | 2004 | >600 | hybrid |
| GRASS GIS | 1982 | >500 | hybrid |
また、R-GIS ブリッジを補完するために、3 つのブリッジの後で空間ライブラリへのインタフェース (Section 10.6)、空間データベース (Section 10.7)、地球観測データのクラウド処理 (Section 10.8) について簡単に紹介する。
10.2 qgisprocess: QGIS へのブリッジなど
QGIS は、最も人気のあるオープンソース GIS である (Table 10.1; Graser and Olaya (2015))。
QGIS は、統一されたインターフェースで、QGIS 自身のジオアルゴリズム、GDAL、さらにインストールされている場合には GRASS GIS、SAGA などのプロバイダを利用することができる (Graser and Olaya 2015)。
バージョン 3.14 (2020年夏にリリース) 以降、QGIS は、さまざまジオコンピュテーション機能にアクセスできる qgis_process コマンドラインを提供している。
qgis_process は、標準的 QGIS に備わる 300 以上のジオアルゴリズムと、GRASS GIS や SAGA など 1000 以上の外部プロバイダへのアクセスを提供している。
qgisprocess パッケージは、R からアクセスすることも可能である。 このパッケージは、 システム上に最低でも QGIS、また本章で使用する関連するプラグインである GRASS GIS や SAGA を必要とする。 インストールに関しては、qgisprocess ドキュメントを参照。
あるいは、Docker がインストール済みであれば、本プロジェクトの qgis イメージから qgisprocess を使うこともできる。
Docker をインストールしており、十分な実行環境のある方は、以下のコマンドで qgisprocess および関連プラグインを実行できる (geocompx/docker リポジトリを参照)。
docker run -e DISABLE_AUTH=true -p 8786:8787 ghcr.io/geocompx/docker:qgis
library(qgisprocess)
#> Attempting to load the cache ... Success!
#> QGIS version: 3.30.3-'s-Hertogenbosch
#> ...このパッケージは、QGIS のインストールを自動的に検出しようとし、検出できない場合は警告を発する。 57
設定に失敗した場合の解決策としては、options(qgisprocess.path = "path/to/your_qgis_process")、環境変数 R_QGISPROCESS_PATH を設定する方法が考えられる。
上記の方法は、複数の QGIS がインストールされており、どれを使うかを決めたい場合にも使える。
詳細については、qgisprocess ‘getting started’ vignette を参照。
次に、どのプラグイン (異なるソフトウェアを意味する) が自分のコンピュータで利用できるかを調べてみよう。
qgis_plugins()
#> # A tibble: 4 × 2
#> name enabled
#> <chr> <lgl>
#> 1 grassprovider FALSE
#> 2 otbprovider FALSE
#> 3 processing TRUE
#> 4 processing_saga_nextgen FALSEプラグイン GRASS GIS (grassprovider) と SAGA (processing_saga_nextgen) が存在しているが、有効になっていないことがわかる。
この二つは本章の後半で使用するので、有効化しよう。
qgis_enable_plugins(c("grassprovider", "processing_saga_nextgen"),
quiet = TRUE)SAGA のほかにも、QGIS Python プラグイン Processing Saga NextGen をインストールしておく必要がある。 このプラグインは、プラグインの管理とインストール あるいは、Python パッケージの qgis-plugin-manager (Linux の場合) からインストールすることができる。
qgis_providers() で、ソフトウェアの名称と対応するジオアルゴリズム数の一覧を表示する。
qgis_providers()
#> # A tibble: 7 × 3
#> provider provider_title algorithm_count
#> <chr> <chr> <int>
#> 1 gdal GDAL 56
#> 2 grass GRASS 306
#> 3 qgis QGIS 50
#> 4 3d QGIS (3D) 1
#> 5 native QGIS (native c++) 243
#> 6 pdal QGIS (PDAL) 17
#> 7 sagang SAGA Next Gen 509出力表から、QGIS のジオアルゴリズム (native, qgis, 3d) と、サードパーティプロバイダの GDAL、SAGA、GRASS GIS の外部アルゴリズムを QGIS インターフェースを通して使用できることが確認できた。
これで、R から QGIS などの地理計算をする準備ができた。 それでは、2 つの事例を試してみよう。 最初のものは、異なる境界線を持つ 2 つのポリゴンデータセットを和集合を作成 (union) する方法を示している (Section 10.2.1)。 もう一つは、ラスタ (Section 10.2.2) で表現された数値標高モデルから新しい情報を導き出すことに重点を置いている。
10.2.1 ベクタデータ
異なる空間単位 (地域、行政単位など) を持つ 2 つのポリゴンオブジェクトがある場合を考えてみよう。 この 2 つのオブジェクトを統合して、すべての境界線と関連する属性を含む 1 つのオブジェクトにすることが目標である。 Section 4.2.8 (Figure 10.1) でも見た不整合なポリゴンを再び利用する。 どちらのポリゴンデータセットも spData パッケージで提供されており、その両方に地理的な CRS を使用したい (Chapter 7 も参照)。
data("incongruent", "aggregating_zones", package = "spData")
incongr_wgs = st_transform(incongruent, "EPSG:4326")
aggzone_wgs = st_transform(aggregating_zones, "EPSG:4326")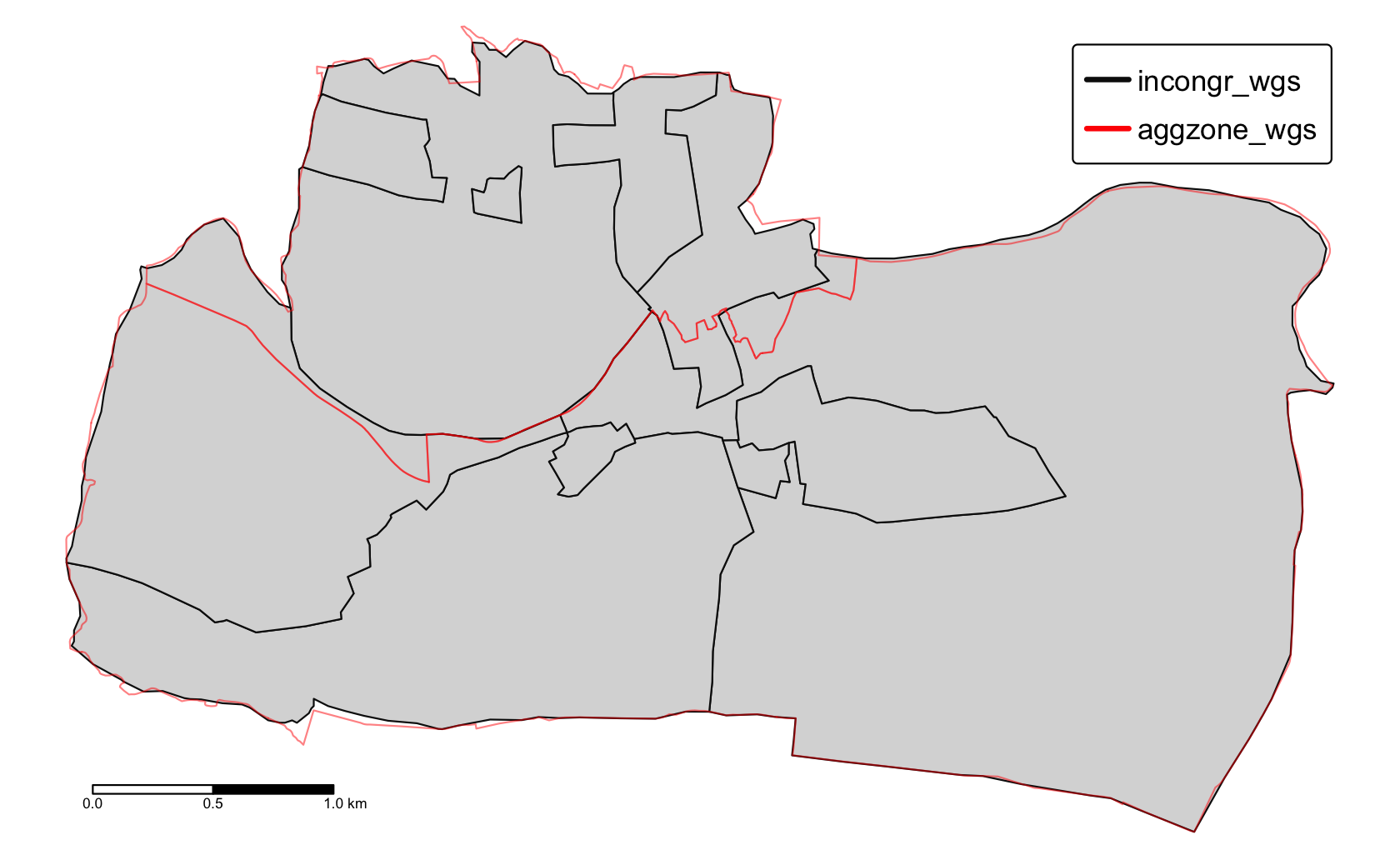
FIGURE 10.1: 二つの単位: 不一致 (黒い線) と集合ゾーン (赤い境界)。
最初に、二つのベクタをマージ (merge) するアルゴリズムを探そう。
qgis_algorithms() 関数は、利用可能なアルゴリズムをすべて表示する。
この関数は、利用可能なすべてのプロバイダと、それらが含むアルゴリズムを含むデータフレームを返す。58
# 出力は表示せず
qgis_algo = qgis_algorithms()qgis_search_algorithms() 関数は、アルゴリズムを探すために使うことができる。
関数の短い説明文に “union”という単語が含まれていると仮定すると、以下のコードを実行して、興味のあるアルゴリズムを見つけることができる。
qgis_search_algorithms("union")
#> # A tibble: 2 × 5
#> provider provider_title group algorithm algorithm_title
#> <chr> <chr> <chr> <chr> <chr>
#> 1 native QGIS (native c++) Vector overlay native:multiunion Union (multiple)
#> 2 native QGIS (native c++) Vector overlay native:union Union 上記のリストにあるアルゴリズムの 1 つ "native:union" は、探している機能の可能性が高そうである。
次のステップとしては、このアルゴリズムが何をするのか、どう使えばいいのかを調べよう。
qgis_show_help() は、アルゴリズムが何をし、引数や出力についての要約を返す。59
これによって、出力が長くなる。
以下のコマンドは、各行に "native:union" が必要とする引数を表すデータフレームを返し、各列は名前、説明、種類、デフォルト値、とりうる値を示す。
alg = "native:union"
union_arguments = qgis_get_argument_specs(alg)
union_arguments
#> # A tibble: 5 × 6
#> name description qgis_type default_value available_values acceptable_...
#> <chr> <chr> <chr> <list> <list> <list>
#> 1 INPUT Input layer source <NULL> <NULL> <chr [1]>
#> 2 OVERLAY Overlay la… source <NULL> <NULL> <chr [1]>
#> 3 OVERLA… Overlay fi… string <NULL> <NULL> <chr [3]>
#> 4 OUTPUT Union sink <NULL> <NULL> <chr [1]>
#> 5 GRID_S… Grid size number <NULL> <NULL> <chr [3]>
#> [[1]]
#> [1] "A numeric value"
#> [2] "field:FIELD_NAME to use a data defined value taken from the FIELD_NAME
#> field"
#> [3] "expression:SOME EXPRESSION to use a data defined value calculated using
#> a custom QGIS expression"union_arguments$name の引数は、INPUT、OVERLAY、OVERLAY_FIELDS_PREFIX、OUTPUT である。
union_arguments$acceptable_values は、各引数に対して、とりうる値のリストを持っている。
多くの関数は、ベクタレイヤへのパスを入力に必要としているが、qgisprocess の関数は sf オブジェクトも受けることができる。
ラスタへのパスが必要とされる場合は、terra と stars のオブジェクトも対応している。
これは便利であるが、もし qgisprocess アルゴリズムに引き渡しだけであれば、パスを渡すことをお薦めする。というのも、qgisprocess はジオアルゴリズムの最初に、QGIS が読める形式である .gpkg や .tif に変換しているからである。
これはアルゴリズムの実行時間を長くしてしまう。
qgisprocess の主な機能は qgis_run_algorithm() であり、QGIS に入力を送り、出力を受け取る。
これは、アルゴリズム名とヘルプに示される名前付き引数のセットを受け取り、期待される計算を実行する。
今回のケースでは、INPUT、OVERLAY、OUTPUT の 3 つの引数が重要だと思われる。
最初の INPUT は、主なベクタオブジェクト incongr_wgs であり、2 番目の OVERLAY は、aggzone_wgs である。
最後の引数、OUTPUT は出力ファイル名だが、指定されていない場合、qgisprocess は自動的に tempdir() に一時ファイルを作成する。
union = qgis_run_algorithm(alg,
INPUT = incongr_wgs, OVERLAY = aggzone_wgs
)
union
#> $ OUTPUT: 'qgis_outputVector' chr "/tmp/...gpkg"上記のコードを実行すると、2 つの入力オブジェクトが一時的な .gpkg ファイルに保存され、選択されたアルゴリズムがそれらに実行され、一時的な .gpkg ファイルが出力として返される。
qgisprocess パッケージは、qgis_run_algorithm() の結果を、この場合は出力ファイルへのパスを含むリストとして保存する。
このファイルを R に読み戻すには、read_sf() (例, union_sf = read_sf(union[[1]]) を使うか、st_as_sf() を使って直接読み込むことができる。
union_sf = st_as_sf(union)QGIS の和集合 (union) の操作は、2 つの入力レイヤの交差 (intersect) と対称差 (symmetrical difference) を用いて、2 つの入力レイヤを 1 つのレイヤにマージすることに注意 (ちなみに、これは GRASS GIS と SAGA で結合操作をするときのデフォルトでもある)。
これは st_union(incongr_wgs, aggzone_wgs) とは違う (演習参照)!
その結果である union_sf は、2 つの入力オブジェクトよりも多くのフィーチャを持つポリゴンとなる。
しかし、これらのポリゴンの多くは小さく、実際の領域を表しているわけではなく、2 つのデータセットの細部が異なるために生じたものであることに注意しておこう。
こうした誤差によってできたものは、スライバー (sliver) ポリゴンと呼ばれている (Figure 10.2 の左側のパネルにある赤い色のポリゴンを参照)。
スライバーを識別する一つの方法として、面積が比較的非常に小さいポリゴン、ここでは例えば 25,000 m2 を見つけ、次にそれを削除する。
適切なアルゴリズムを探そう。
qgis_search_algorithms("clean")
#> # A tibble: 1 × 5
#> provider provider_title group algorithm algorithm_title
#> <chr> <chr> <chr> <chr> <chr>
#> 1 grass GRASS Vector (v.*) grass:v.clean v.clean今回見つかったアルゴリズム (v.clean) は、QGIS ではなく、GRASS GIS に含まれている。
GRASS GIS の v.clean は、空間ベクタデータのトポロジーをクリーニングする強力なツールである。
重要なのは、qgisprocess を通して使用できることである。
grass7 という名称だった。
よって、QGIS バージョンが古い場合、grass ではなく grass7 とする。
前のステップと同様に、このアルゴリズムのヘルプを見るところから始めよう。
qgis_show_help("grass:v.clean")ここでは出力を省略した。実際のヘルプテキストはかなり長く、多くの引数を含んでいる。60
これは、v.clean がマルチツールであり、さまざまな種類のジオメトリをクリーニングし、さまざまな種類のトポロジー問題を解決することができることがある。
この例では、いくつかの引数に絞って説明するが、v.clean の機能については、 アルゴリズムのドキュメントを勧める。
qgis_get_argument_specs("grass:v.clean") |>
select(name, description) |>
slice_head(n = 4)
#> # A tibble: 4 × 2
#> name description
#> <chr> <chr>
#> 1 input Layer to clean
#> 2 type Input feature type
#> 3 tool Cleaning tool
#> 4 threshold Threshold (comma separated for each tool)このアルゴリズムの主な引数は input で、これはベクタオブジェクトである。
次に tool の選択であるが、これはクリーニングの方法である。 61
v.clean には、重複した形状の削除、線間の微小角度の削除、微小領域の削除など、12 種類のツールが存在する。
今回は、後者のツール、rmarea を解説する。
いくつかのツール (rmarea を含む) は、追加の引数 threshold を必要とし、その動作は選択されたツールに依存する。
この場合、rmarea ツールは、threshold で与えられた値より小さいか等しい領域をすべて削除する。
なお、入力レイヤの空間参照系によらず単位は平方メートルである。
このアルゴリズムを実行し、その出力を新しい sf オブジェクト clean_sf に変換してみよう。
clean = qgis_run_algorithm("grass7:v.clean",
input = union_sf,
tool = "rmarea", threshold = 25000
)
clean_sf = st_as_sf(clean)その結果、Figure 10.2 の右側のパネルでは、予想通り、灰色のポリゴンが削除されているように見える。
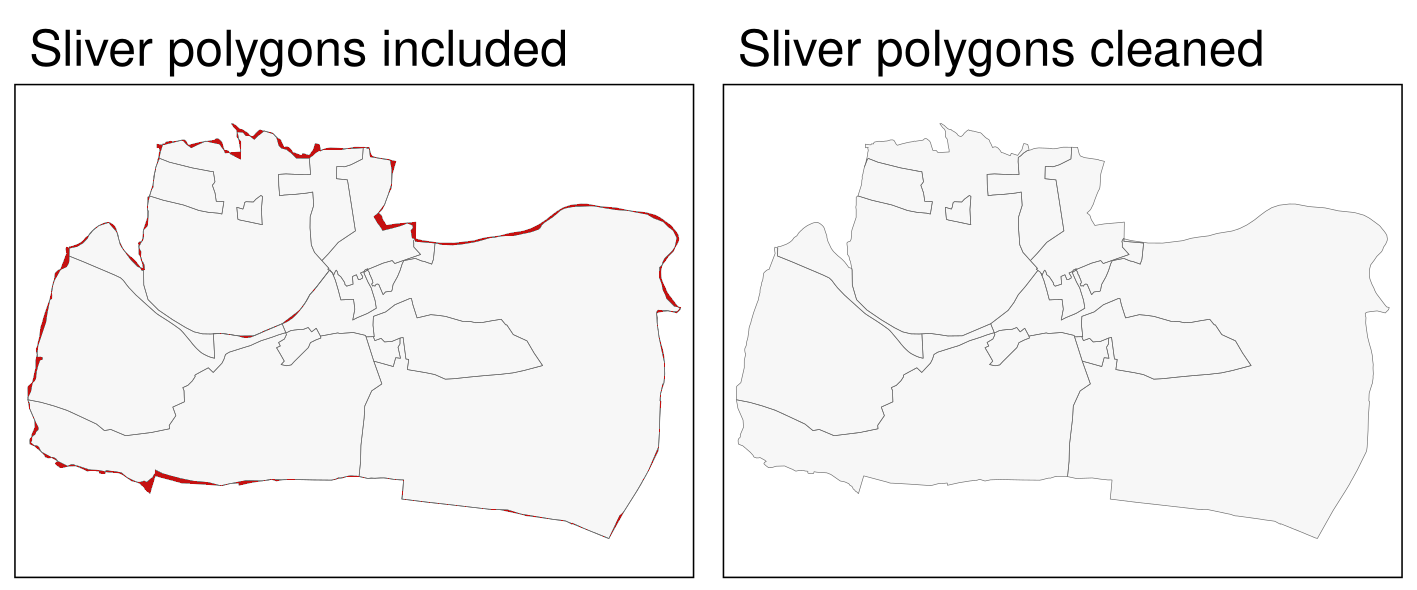
FIGURE 10.2: 灰色部分を赤で強調 (左) と灰色部分を除去 (右)。
10.2.2 ラスタデータ
デジタル標高モデル (Digital Elevation Model, DEM) には、ラスタセルごとの標高情報が含まれている。 DEM は、衛星航法、水流モデル、表面分析、可視化など、さまざまな用途で使用されている。 ここでは、DEM ラスタから統計学習における予測因子として利用可能な新しい情報を導き出してみたい。 例えば、様々な地形パラメータは、地滑りの予測に役立つ (Chapter 12 参照)。
このセクションでは、dem.tif を使用することにする。これは、Mongón 調査地域のデジタル標高モデルである (Land Process Distributed Active Archive Center からダウンロード、?dem.tif も参照)。
解像度は約 30 m × 30 m で、投影型 CRS を使用している。
library(qgisprocess)
library(terra)
dem = rast(system.file("raster/dem.tif", package = "spDataLarge"))terra パッケージの terrain() では、傾斜、アスペクト、TPI (Topographic Position Index)、TRI (Topographic Ruggedness Index)、粗さ、流れ方向など、地形の基本特性を算出することができる。
とはいえ、GIS は、地形の特性に関する機能が他にもたくさんあり、文脈によってはより適しているものもある。
例えば、地形湿潤指数 (Topologic Wetness Index, TWI) は、水文・生物学的プロセスの研究に有用であることがわかっている (Sørensen, Zinko, and Seibert 2006)。
このインデックスのアルゴリズムリストを、"wetness" というキーワードで検索してみよう。
qgis_search_algorithms("wetness") |>
dplyr::select(provider_title, algorithm) |>
head(2)
#> # A tibble: 2 × 2
#> provider_title algorithm
#> <chr> <chr>
#> 1 SAGA Next Gen sagang:sagawetnessindex
#> 2 SAGA Next Gen sagang:topographicwetnessindexonestep上記のコードの出力は、目的のアルゴリズムが SAGA ソフトウェアに存在することを示唆するものである。62 SAGA はハイブリッド GIS であるが、主にラスタ処理、ここでは特にデジタル標高モデル (土壌特性、地形属性、気候パラメータ) に重点を置いている。 したがって、SAGA は大規模な (高解像度の) ラスタデータセットの高速処理に特に優れている (Conrad et al. 2015)。
"sagang:sagawetnessindex" アルゴリズムは、実際には修正された TWI であり、谷底に位置するセルに対してより現実的な土壌水分ポテンシャルをもたらすものである (Böhner and Selige 2006)。
qgis_show_help("sagang:sagawetnessindex")ここでは、デフォルトの引数を使用する。
与える引数は、入力となる DEM だけである。
このアルゴリズムを使う際は、パラメータ値が研究の目的にあっているか確認する必要がある。63
QGIS から SAGA アルゴリズムを使う前に、デフォルトのラスタ形式を .tif から、SAGA のデフォルトの .sdat に変更しておこう。
これで、指定しなければ保存形式は .sdat となる。
ソフトウェア (SAGA, GDAL) のバージョンによっては必要はないが、SAGA のラスタに関する問題を未然に防ぐことができる。
options(qgisprocess.tmp_raster_ext = ".sdat")
dem_wetness = qgis_run_algorithm("sagang:sagawetnessindex",
DEM = dem
)"sagang:sagawetnessindex" は、集水域、集水勾配、修正集水域、地形湿潤指数という 4 つのラスタを返す。qgis_as_terra() 関数で出力名を指定することで、選択した出力を読み出すことができる。
選択された出力は、qgis_as_terra() 関数に出力名を与えることで読むことができる。
QGIS から SAGA を使う作業は終わったので、デフォルト形式を .tif に戻す。
dem_wetness_twi = qgis_as_terra(dem_wetness$TWI)
# plot(dem_wetness_twi)
options(qgisprocess.tmp_raster_ext = ".tif")Figure 10.3 の左パネルに出力された TWI マップを見ることができる。 地形湿潤指数には単位がない。数値が小さいほど水がたまらず、数値が大きいほど水がたまるエリアであることを示す。
また、デジタル標高モデルからの情報は、例えばジオモルフォン (geomorphon) に分類することができる。地形は、斜面、尾根、谷などの地形を表す 10 のクラスからなる地形学的表現型である (Jasiewicz and Stepinski 2013)。 これらの表現型は、地滑りしやすさ、生態系サービス、人間の移動性、デジタル土壌マッピングなど、多くの研究で利用されている。
ジオモルフォンのアルゴリズムのオリジナルの実装は GRASS GIS で作成され、qgisprocess のリストで "grass:r.geomorphon" として見つけることができる。
qgis_search_algorithms("geomorphon")
#> [1] "grass:r.geomorphon" "sagang:geomorphons"
qgis_show_help("grass:r.geomorphon")
# 出力は非表示ジオモルフォンの計算には、入力 DEM (elevation) が必要で、オプションの引数でカスタマイズすることができる。
フラグ search は視線距離を計算する長さ、および -m は検索値を (セル数ではなく) メートル単位で提供することを指定する。
追加論点の詳細は、原著論文と GRASS GIS documentation に記載されている。
dem_geomorph = qgis_run_algorithm("grass7:r.geomorphon",
elevation = dem,
`-m` = TRUE, search = 120
)出力される dem_geomorph$forms は、10 個のカテゴリからなるラスタファイルで、それぞれが地形形状を表している。
これを qgis_as_terra() で R に読み込んで可視化したり (Figure 10.3 右図)、その後の計算で使うことができる。
dem_geomorph_terra = qgis_as_terra(dem_geomorph$forms)興味深いことに、Figure 10.3 に示すように、いくつかの地形と TWI 値の間にはつながりがある。 TWI 値が最も大きいのは谷や窪地であり、最も小さいのは予想通り尾根であった。
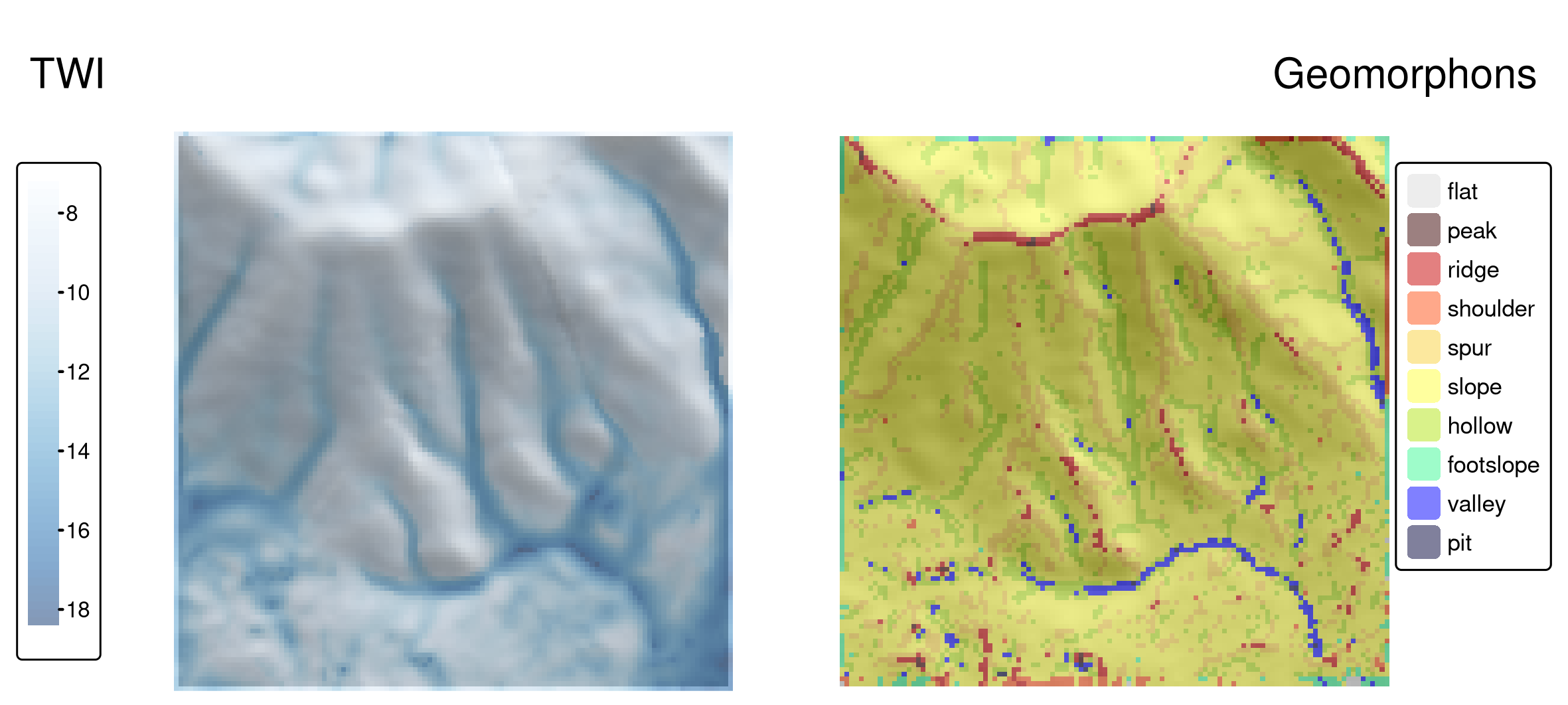
FIGURE 10.3: 研究対象地 Mongón の地形湿潤指数 (TWI、パネル左) とジオモルフォン (パネル右)。
10.3 SAGA
System for Automated Geoscientific Analyses (SAGA; Table 10.1) は、コマンドラインインタフェース (Windows では saga_cmd.exe、Linux では単に saga_cmd) を介して SAGA モジュールを実行する可能性を提供する (SAGA wiki on modules を参照)。
また、Python インターフェース (SAGA Python API) も用意されている。
Rsagacmd は、前者を使って R 内で SAGA を実行している。
この Section では、Rsagacmd を使用して、SAGA の seeded region growing アルゴリズムを使って、2000年9月の Peru の Mongón 調査地域の正規化差分植生指数 (normalized difference vegetation index, NDVI) の値が類似した地域を抽出する (Figure 10.4 左図)。64
ndvi = rast(system.file("raster/ndvi.tif", package = "spDataLarge"))Rsagacmd を始めるには、saga_gis() 関数を実行する必要がある。
この関数は主に 2 つの目的がある。
- 有効な SAGA ライブラリやツールへのリンクを含む新しいオブジェクトを動的に作成すること65
-
raster_backend(ラスタデータを扱う際に用いる R パッケージ)、vector_backend(ベクタデータを扱う際に用いる R パッケージ)、cores(処理に用いる CPU コアの最大数、デフォルトは all) など、一般的なパッケージオプションを設定すること
この saga オブジェクトは、利用可能なすべての SAGA ツールへの接続を含んでいる。
これはライブラリ (ツールのグループ) のリストとして構成されており、ライブラリの内部にはツールのリストがある。
どのツールにも $ 記号でアクセスできる (TAB キーで自動補完することが可能)。
シード領域拡大アルゴリズムは,主に 2 つのステップで動作する (Adams and Bischof 1994; Böhner, Selige, and Ringeler 2006)。 まず、指定されたサイズのローカルウィンドウにおいて、最も分散の小さいセルを見つけることで、初期セル (seed) が生成される。 次に、領域成長アルゴリズムを用いて、seed の近傍画素をマージし、均質な領域を作成する。
sg = saga$imagery_segmentation$seed_generation上記の例では、まず imagery_segmentation ライブラリを示し、次にその seed_generation ツールを使用した。
また、次のステップでツールのコード全体を再入力しないように、sg オブジェクトに割り当てる。66
sg と入力することで、ツールの簡単な概要と、パラメータ、説明、およびデフォルトのデータフレームが表示される。
また、tidy(sg) を使用すると、パラメータのテーブルだけを取り出すことができる。
seed_generation ツールは、引数にラスタデータ (features) を必要とする。また、初期ポリゴンのサイズを指定する band_width などの追加パラメータを提供することができる。
ndvi_seeds = sg(ndvi, band_width = 2)
#plot(ndvi_seeds$seed_grid)この出力は、3 つのオブジェクトからなるリストである。variance は局所分散のラスタマップ、 seed_grid は生成されたシードを含むラスタマップ、seed_points は生成されたシードを含む空間ベクタオブジェクトである。
つぎの SAGA ツールとして seeded_region_growing を紹介しよう。67
seed_region_growing ツールは、前のステップで計算した seed_grid と ndvi ラスタオブジェクトの 2 つの入力を必要とする。
さらに、入力フィーチャを標準化するための normalize や neighbour (4 または 8-neighborhood)、 method などのパラメータを指定することができる。
最後のパラメータには、0 または 1 を指定することができる (ラスタセルの値とその位置に基づいて領域を成長させるか、値のみを成長させるか)。
このメソッドの詳細な説明は、 Böhner, Selige, and Ringeler (2006) を参照。
ここでは、method を 1 に変更するだけである。つまり、出力される地域は、NDVI 値の類似性に基づいてのみ作成されることを意味する。
srg = saga$imagery_segmentation$seeded_region_growing
ndvi_srg = srg(ndvi_seeds$seed_grid, ndvi, method = 1)
plot(ndvi_srg$segments)このツールは、3 つのオブジェクトのリストを返す。このツールは、segments、similarity、table という 3 つのオブジェクトのリストを返す。
similarity オブジェクトは、シードと他のセルとの類似性を示すラスタであり、table は入力シードに関する情報を格納したデータフレームである。
最後に、ndvi_srg$segments は、結果として得られた領域 (Figure 10.4 右図) を表すラスタである。
これをポリゴンに変換するには、as.polygons() と st_as_sf() を使用する (Section 6.5)。
ndvi_segments = ndvi_srg$segments |>
as.polygons() |>
st_as_sf()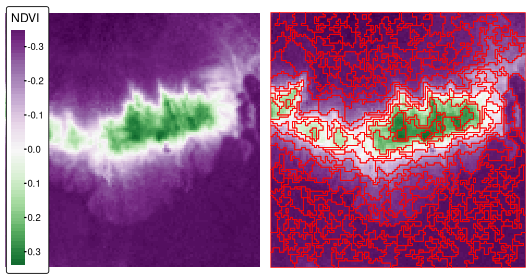
FIGURE 10.4: 正規化差分植生指数 (NDVI、左図) と、Mongón調査地域のシード領域成長アルゴリズムを用いて得られた NDVI ベースのセグメント。
結果として得られるポリゴン (セグメント) は、類似した値を持つ領域を表す。 また、クラスタリング (k-means など)、地域化 (SKATER など)、教師あり分類法など、さまざまな手法でさらに大きなポリゴンに集約することができる。 演習で試すことができる。
R には、似たような値を持つポリゴン (いわゆるセグメント) を作成するという目的を達成するための他のツールもある。 いくつかの画像分割アルゴリズムを実行できる SegOptim パッケージ (Gonçalves et al. 2019) や、地理空間データを扱うためにスーパーピクセルアルゴリズム SLIC を実装した supercells (Nowosad and Stepinski 2022) などが含まれている。
10.4 GRASS GIS
米国陸軍建設工学研究所 (U.S. Army - Construction Engineering Research Laboratory, USA-CERL) は、1982年から1995年にかけて、地理資源解析支援システム (Geographical Resources Analysis Support System, GRASS GIS) の中核となるシステムを作成した [Table 10.1; Neteler and Mitasova (2008)]。 アカデミアは1997年からこの作業を継続した。 SAGA と同様、グラスも当初はラスタ処理に注力し、その後、GRASS GIS 6.0 以降、高度なベクタ機能を追加している (Bivand, Pebesma, and Gómez-Rubio 2013)。
GRASS は、入力データを内部データベースに格納する。 ベクタデータに関して、GRASS GIS はデフォルトでトポロジカル GIS、すなわち隣接するフィーチャのジオメトリを一度だけ保存する。 ベクタ属性の管理にはデフォルトで SQLite を用い、属性はキーによってジオメトリ、すなわち GRASS GIS データベースにリンクされる (GRASS GIS vector management)。
GRASS GIS を使う前に、GRASS GIS データベースを (R からも) セットアップする必要があるが、このプロセスに少し戸惑うかもしれない。 まず、GRASS GIS のデータベースは専用のディレクトリを必要とし、そのディレクトリには location を置く必要がある (詳しくは grass.osgeo.org の GRASS GIS Database ヘルプページを参照)。 location には、1 つのプロジェクトまたは 1 つの領域のジオデータが格納される。 通常、1 つの場所の中に、異なるユーザや異なるタスクを参照するいくつかのマップセットを存在させることができる。 各 location には、PERMANENT マップセット (自動的に作成される必須のマップセット) もある。 プロジェクトのすべてのユーザと地理データを共有するために、データベース所有者は PERMANENT マップセットに空間データを追加することができる。 さらに、PERMANENT マップセットには、ラスタデータの投影法、空間範囲、およびデフォルトの解像度が格納される。 まとめると、GRASS GIS データベースは多くの location を含み (1 つのロケーションのデータはすべて同じ CRS を持つ)、それぞれの location は多くのマップセット (データセットのグループ) を格納することができる。 GRASS GIS 空間データベースシステムの詳細は、Neteler and Mitasova (2008) と GRASS GIS quick start を参照。 こkでは R から手軽に GRASS GIS を使うため link2GI パッケージを使う。しかし、GRASS GIS データベースを順番に作ることもできる。 作り方は GRASS within R を参照。 以下の段落で解説するコードは、初めて GRASS GIS を使う方には難しいかもしれないが、コードを 1 行 1 行実行して途中の結果を確認することで、コードの元となる理由が明らかになる。
ここでは、GIScience における最も興味深い問題の一つである巡回セールスマン問題 を用いた rgrass を紹介する。
ある巡回セールスマンが 24 件の顧客を訪問したいとする。
さらに自宅を起点かつ終点とするので、結果的に 25 カ所を、最短距離で回りたい。
この問題に対する最適解は一つであるが、考えられる解をすべてチェックすることは、現代のコンピュータでは (ほとんど) 不可能である (Longley 2015)。
この場合、可能な解の数は (25 - 1)! / 2、すなわち 24 の階乗を 2 で割った数に相当する (2 で割るのは、順方向と逆方向を区別しないため)。
1 回の繰り返しがナノ秒でも、9837145 年間に相当する。
幸いなことに、この想像を絶する時間のごく一部で実行できる、巧妙でほぼ最適なソリューションがある。
GRASS GIS は、これらの解決策の一つを提供する (詳細は、 v.net.salesmanを参照)。
今回の使用例では、ロンドンの街角にある最初の 25 レンタルサイクルのステーション (顧客の代わり) 間の最短経路を見つけたい (最初の自転車ステーションは、巡回セールスマンの自宅に相当すると仮定する)。
data("cycle_hire", package = "spData")
points = cycle_hire[1:25, ]レンタルサイクルのステーションのデータの他に、この地域の道路網が必要である。
osmdata パッケージで OpenStreetMap から ダウンロードすることができる (Section 8.5 も参照)。
そのために、道路網のクエリ (OSM 言語では “highway” とラベル付けされている) を points のバウンディングボックス に制限し、対応するデータを sf オブジェクトとして読み込む。
osmdata_sf() は、複数の空間オブジェクト (点、線、ポリゴンなど) を含むリストを返すが、ここでは線オブジェクトとその関連 ID のみを保持する。68
library(osmdata)
b_box = st_bbox(points)
london_streets = opq(b_box) |>
add_osm_feature(key = "highway") |>
osmdata_sf()
london_streets = london_streets[["osm_lines"]]
london_streets = select(london_streets, osm_id)これでデータが揃ったので、次に GRASS GIS のセッションを開始する。
幸い、link2GI パッケージの linkGRASS() を使えば、たった一行のコードで GRASS GIS 環境をセットアップできる。
空間オブジェクトは、空間データベースの投影と範囲を決定するものである。
まず、linkGRASS() は、あなたのコンピュータにインストールされている全ての GRASS GIS を検索する。
ここでは ver_select を TRUE に設定しているので、見つかった GRASS GIS-installation の中から対話的に一つを選択することができる。
もし、インストールが一つしかない場合は、linkGRASS() が自動的にそれを選択する。
次に、linkGRASS() は、GRASS GIS への接続を確立する。
GRASS GIS のジオアルゴリズムを使用する前に、GRASS GIS の空間データベースにデータを追加する必要がある。
幸いなことに、便利な関数 write_VECT() がこれを代行してくれる。
(ラスタデータには write_RAST() を使用する。)
この例では、最初の属性列のみを使用して、道路と自転車レンタル点データを追加し、GRASS GIS で london_streets と points という名前を付けている。
write_VECT(terra::vect(london_streets), vname = "london_streets")
write_VECT(terra::vect(points[, 1]), vname = "points")rgrass パッケージは、入力と出力が terra オブジェクトであることを想定している。
したがって、write_VECT() を使用するためには、vect() 関数を使用して sf 空間ベクタを terra の SpatVector に変換する必要がある。69
現在、両方のデータセットが GRASS GIS のデータベースに存在している。
ネットワークの解析を行うには、トポロジカルクリーンな道路ネットワークが必要である。
GRASS GIS の "v.clean" は、重複、小角、ダングルの除去などを行う。
ここでは、後続のルート検索アルゴリズムが実際に交差点で右折または左折できるように、各交差点で改行し、その出力を streets_clean という名前の GRASS GIS オブジェクトに保存している。
execGRASS(
cmd = "v.clean", input = "london_streets", output = "streets_clean",
tool = "break", flags = "overwrite"
)help フラグを使うことができる。
例えば execGRASS("g.region", flags = "help") と試してみよう。
レンタルサイクルのステーションのいくつかのポイントは、正確に街路セグメント上に位置しない可能性がある。
しかし、それらの間の最短経路を見つけるために、それらを最も近い道路セグメントに接続する必要がある。
"v.net"のconnect-operatorはまさにこれを行う。
その出力を streets_points_con に保存する。
execGRASS(
cmd = "v.net", input = "streets_clean", output = "streets_points_con",
points = "points", operation = "connect", threshold = 0.001,
flags = c("overwrite", "c")
)得られたクリーンなデータセットは "v.net.salesman" アルゴリズムの入力となり、最終的にすべての自転車レンタルステーション間の最短経路を見つけることができる。
その引数の一つが center_cats で、これは入力として数値の範囲を必要とする。
この範囲は、最短ルートを計算するためのポイントを表している。
ここでは、すべての自転車ステーション間の経路を計算したいので、1-25 に設定しておく。
巡回セールスマンアルゴリズムの GRASS GIS ヘルプページを参照するには、execGRASS("g.manual", entry = "v.net.salesman") を実行する。
execGRASS(
cmd = "v.net.salesman", input = "streets_points_con",
output = "shortest_route", center_cats = paste0("1-", nrow(points)),
flags = "overwrite"
)結果を見るには、結果を R に入れ、ジオメトリのみ保持した sf オブジェクトに変換する。これを mapview で可視化する (Figure 10.5 と Section 9.4)。
route = read_VECT("shortest_route") |>
st_as_sf() |>
st_geometry()
mapview::mapview(route) + points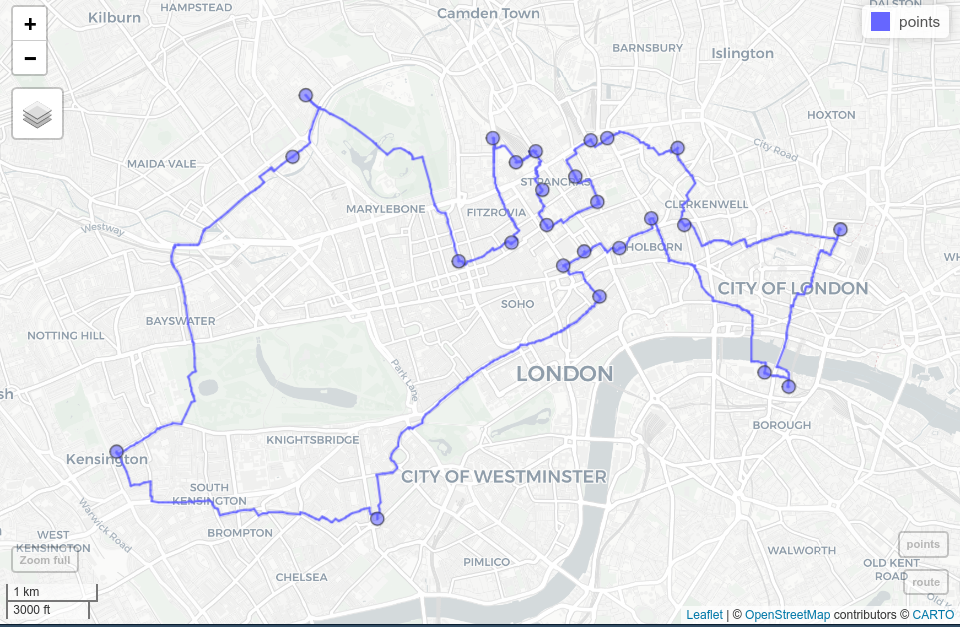
FIGURE 10.5: ロンドンの OSM 道路網の24の自転車レンタル地点 (青点) とその最短ルート (青線)
その際、いくつか注意すべき点がある。
- GRASS GIS の空間データベースを使えば、より高速に処理できた。
しかし、ここでは最初に地理データを書き出した。
そして、新しいオブジェクトを作成し、最終結果だけを R にインポートした。
現在利用可能なデータセットを調べるには、
execGRASS("g.list", type = "vector,raster", flags = "p")を実行する。 - また、R から既にある GRASS GIS 空間データベースにアクセスすることも可能であった。
R にデータをインポートする前に、いくつかの (空間) 部分集合を作成したい場合がある。
ベクタデータには
"v.select"と"v.extract"を使用する。"db.select"を使用すると、対応するジオメトリを返さずにベクタレイヤの属性テーブルの部分集合を選択することができる。 - また、実行中の GRASS GIS のセッションから R を起動することもできる (詳細は Bivand, Pebesma, and Gómez-Rubio 2013 を参照)。
- GRASS GIS で提供されて入るジオアルゴリズムの素晴らしいドキュメントは、 GRASS GIS online help または
execGRASS("g.manual", flags = "i")を参照。
10.5 いつ、何を使うべきか?
R-GIS のインターフェースは、個人の好みや作業内容、GIS の使い方に依存するため、一概にお勧めすることはできないし、研究分野にもよるだろう。 前述の通り、SAGA は大規模 (高解像度) ラスタデータセットの高速処理に特に優れており、水文学者、気候学者、土壌学者に頻繁に利用されている (Conrad et al. 2015)。 一方、GRASS GIS は、トポロジーに基づく空間データベースをサポートする唯一の GIS であり、ネットワーク分析だけでなくシミュレーション研究にも特に有用である。 QGIS は、GRASS GIS や SAGA と比較して、特に初めて GIS を使う方にとって使いやすく、おそらく最も人気のあるオープンソースの GIS だと思われる。 したがって、qgisprocess は、ほとんどのユースケースに適切な選択である。 その主なメリットは
- 複数の GIS に統一的にアクセスできるため、重複した機能を含む 1,000 以上のジオアルゴリズム ( Table 10.1 ) を提供。例えば、QGIS、SAGA、GRASS GIS などのジオアルゴリズムを使ってオーバーレイ操作を実行することが可能である。
- データ形式の自動変換 (SAGAは
.sdatグリッドファイル、GRASS GIS は独自のデータベース形式を使用するが、対応する変換は QGIS が行う。) - 地理的な R オブジェクトを QGIS ジオアルゴリズムに自動的に渡し、R に戻すことができる。
- 名前付き引数、デフォルト値の自動取得をサポートする便利な機能 (rgrass からインスパイアされた)
もちろん、他の R-GIS ブリッジを使用した方が良いケースもある。 QGIS は、複数の GIS ソフトウェアパッケージへの統一インターフェースを提供する唯一の GIS であるが、対応するサードパーティのジオアルゴリズムのサブセットへのアクセスしか提供しない (詳細については、Muenchow, Schratz, and Brenning (2017) を参照)。 したがって、SAGA と GRASS GIS の関数一式を使用するには、RSAGA と rgrass 以外は使わない方が良い。 また、ジオデータベースを用いてシミュレーションを行いたい場合 (Krug, Roura-Pascual, and Richardson 2010)、qgisprocess が、呼び出しごとに常に新しい GRASS GIS セッションを開始するので、rgrass を直接使用してみよう。 最後に、地形データ、空間データベース管理機能 (マルチユーザーアクセスなど) が必要な場合は、GRASS GIS の利用を勧める。
なお、スクリプティング・インターフェースを持つ GIS ソフトウェアパッケージは以下のように数多くあるが、これらを利用できる専用の R パッケージはない: gvSig、OpenJump、Orfeo Toolbox。70
10.6 GDAL へのブリッジ
Chapter 8 で述べたように、GDAL は多くの地理データ形式をサポートする低レベルのライブラリである。
GDAL は非常に効果的なので、ほとんどの GIS プログラムは、車輪の再発明や特注の読み書きコードを使用するのではなく、地理データのインポートとエクスポートのためにバックグラウンドで GDAL を使用している。
しかし、GDAL が提供するのは、データ入出力だけではない。
ベクタデータとラスタデータの geoprocessing tools、ラスタデータをオンラインで提供するためのタイルを作成する機能、ベクタデータの高速ラスタ化がある。
GDAL はコマンドラインツールであるため、R からは system() コマンドからアクセスすることができる。
以下のコードは、この機能を実現するものである。
linkGDAL() は、GDAL が動作しているコンピュータを検索し、実行ファイルの場所を PATH 変数に追加して、GDAL を呼び出せるようにする (Windows で通常必要になる)。
link2GI::linkGDAL()これで、system() 関数を使用して、任意の GDAL ツールを呼び出すことができる。
例えば、ogrinfo は、ベクタデータセットのメタデータを提供する。
ここでは、このツールに 2 つのフラグを追加して呼び出する。 -al は全レイヤの全フィーチャをリストアップし、-so は要約のみを取得する (完全なジオメトリのリストではない)。
our_filepath = system.file("shapes/world.gpkg", package = "spData")
cmd = paste("ogrinfo -al -so", our_filepath)
system(cmd)
#> INFO: Open of `.../spData/shapes/world.gpkg'
#> using driver `GPKG' successful.
#>
#> Layer name: world
#> Geometry: Multi Polygon
#> Feature Count: 177
#> Extent: (-180.000000, -89.900000) - (179.999990, 83.645130)
#> Layer SRS WKT:
#> ...その他、よく使われる GDAL のツールは以下の通り
-
gdalinfo: ラスタデータセットのメタデータを提供 -
gdal_translate: 異なるラスタファイル形式間の変換 -
ogr2ogr: 異なるベクタファイル形式間で変換 -
gdalwarp: ラスタデータセットの再投影、変換、切り抜き (clip) -
gdaltransform: 座標変換
GDAL ツールの全リストとそのヘルプファイルは https://gdal.org/programs/ 。
link2GI が提供する GDAL への「リンク」は、R やシステムの CLI からより高度な GDAL の作業を行うための基盤として利用することができるだろう。 TauDEM (http://hydrology.usu.edu/taudem) や Orfeo Toolbox (https://www.orfeo-toolbox.org/) は、コマンドラインインタフェースを提供する空間データ処理ライブラリ/プログラムである。上記の例は、R を介してシステムのコマンドラインからこれらのライブラリにアクセスする方法である。 これは、新しい R パッケージという形で、これらのライブラリへの適切なインタフェースを作成するための出発点となる可能性がある。
しかし、新しいブリッジを作成するプロジェクトに飛び込む前に、既存の R パッケージのパワーと、system() の呼び出しがプラットフォームに依存しない (一部のコンピュータで失敗する) 可能性があることを認識しておくことが重要である。
一方、sf は GDAL、GEOS、PROJ が提供するパワーのほとんどを Rcpp が提供する R/C++ インターフェースを介して R にもたらし、system() の呼び出しを回避している。71
10.7 空間データベースへのブリッジ
空間データベース管理システム (空間 DBMS) は、空間および非空間データを構造化して保存する。 大規模なデータの集合を、一意の識別子 (主キーと外部キー) および暗黙のうちに空間を介して関連するテーブル (エンティティ) に整理することができる (たとえば、空間結合を考えてみてみよう)。 地理的なデータセットはすぐに大きくなったり、乱雑になったりする傾向があるため、この機能は便利である。 データベースは、空間および非空間フィールドに基づく大規模なデータセットの保存とクエリを効率的に行うことができ、マルチユーザーアクセスとトポロジーのサポートを提供する。
最も重要なオープンソースの空間データベースは PostGIS である (Obe and Hsu 2015)。72 PostGIS のような空間 DBMS への R ブリッジは重要で、数ギガバイトの地理データを RAM にロードすることなく、R セッションをクラッシュさせる可能性があるような巨大なデータストアにアクセスできる。 このセクションの残りの部分では、PostGIS in Action, Second Edition の “Hello real world” に基づいて、R から PostGIS を呼び出す方法を紹介する (Obe and Hsu 2015)。73
QGIS Cloud (https://qgiscloud.com/) にある PostgreSQL/PostGIS データベースにアクセスしているため、この後のコードはインターネット接続している必要がある。74 最初のステップは、データベース名、ホスト名、およびユーザー情報を指定して、データベースへの接続を作成することである。
library(RPostgreSQL)
conn = dbConnect(
drv = PostgreSQL(),
dbname = "rtafdf_zljbqm", host = "db.qgiscloud.com",
port = "5432", user = "rtafdf_zljbqm", password = "d3290ead"
)新しいオブジェクト conn は、R セッションとデータベースの間のリンクを確立したに過ぎない。
データを保存することはない。
多くの場合、最初の質問は「データベースからどのテーブルが見つかるか」である。
これには、dbListTables() で次のように答えることができる。
dbListTables(conn)
#> [1] "spatial_ref_sys" "topology" "layer" "restaurants"
#> [5] "highways"答えは、この 5 つのテーブルである。
ここでは、restaurants と highways のテーブルのみを対象としている。
前者は米国内のファストフード店の位置を、後者は米国の主要な高速道路を表している。
テーブルで利用可能な属性について調べるには、dbListFields を実行する。
dbListFields(conn, "highways")
#> [1] "qc_id" "wkb_geometry" "gid" "feature"
#> [5] "name" "state"さて、利用可能なデータセットがわかったところで、いくつかのクエリを実行し、データベースに質問することができる。
クエリは、データベースが理解できる言語 (通常はSQL) で提供される必要がある。
最初のクエリは、highways テーブルから Maryland 州 (MD) の US Route 1 を選択する。
なお、read_sf() は、データベースへのオープンな接続とクエリが提供されれば、データベースから地理データを読み込むことができる。
さらに、read_sf() は、どの列がジオメトリを表すかを知る必要がある (ここでは、wkb_geometry)。
query = paste(
"SELECT *",
"FROM highways",
"WHERE name = 'US Route 1' AND state = 'MD';"
)
us_route = read_sf(conn, query = query, geom = "wkb_geometry")この結果、MULTILINESTRING 型の us_route という名前の sf オブジェクトが生成される。
また、前述したように、非空間的な質クエリだけでなく、空間的な性質をもとにデータセットをクエリすることも可能である。 これを示すために、次の例では選択した高速道路 (Figure 10.6) の周囲に 35 km (35,000 m) のバッファを追加している。
query = paste(
"SELECT ST_Union(ST_Buffer(wkb_geometry, 35000))::geometry",
"FROM highways",
"WHERE name = 'US Route 1' AND state = 'MD';"
)
buf = read_sf(conn, query = query)なお、これはおそらく読者がすでに知っている (ST_Union()、ST_Buffer()) を使った空間クエリであった。
また、sf パッケージにも同名のものがあるが、こちらは小文字になっている (st_union()、st_buffer())。
実際、sf パッケージの関数名は、PostGIS の命名規則にほぼ従っている。75
最後のクエリは、35 km のバッファゾーン (Figure 10.6) 内にあるすべてのハーディーズレストラン (HDE) を検索する。
query = paste(
"SELECT *",
"FROM restaurants r",
"WHERE EXISTS (",
"SELECT gid",
"FROM highways",
"WHERE",
"ST_DWithin(r.wkb_geometry, wkb_geometry, 35000) AND",
"name = 'US Route 1' AND",
"state = 'MD' AND",
"r.franchise = 'HDE');"
)
hardees = read_sf(conn, query = query)空間 SQL クエリの詳細な説明は Obe and Hsu (2015) を参照。 最後に、次のようにデータベース接続を閉じるのがよい方法である。76
RPostgreSQL::postgresqlCloseConnection(conn)#>
#> ── tmap v3 code detected ───────────────────────────────────────────────────────
#> [v3->v4] `tm_polygons()`: use `col_alpha` instead of `border.alpha`.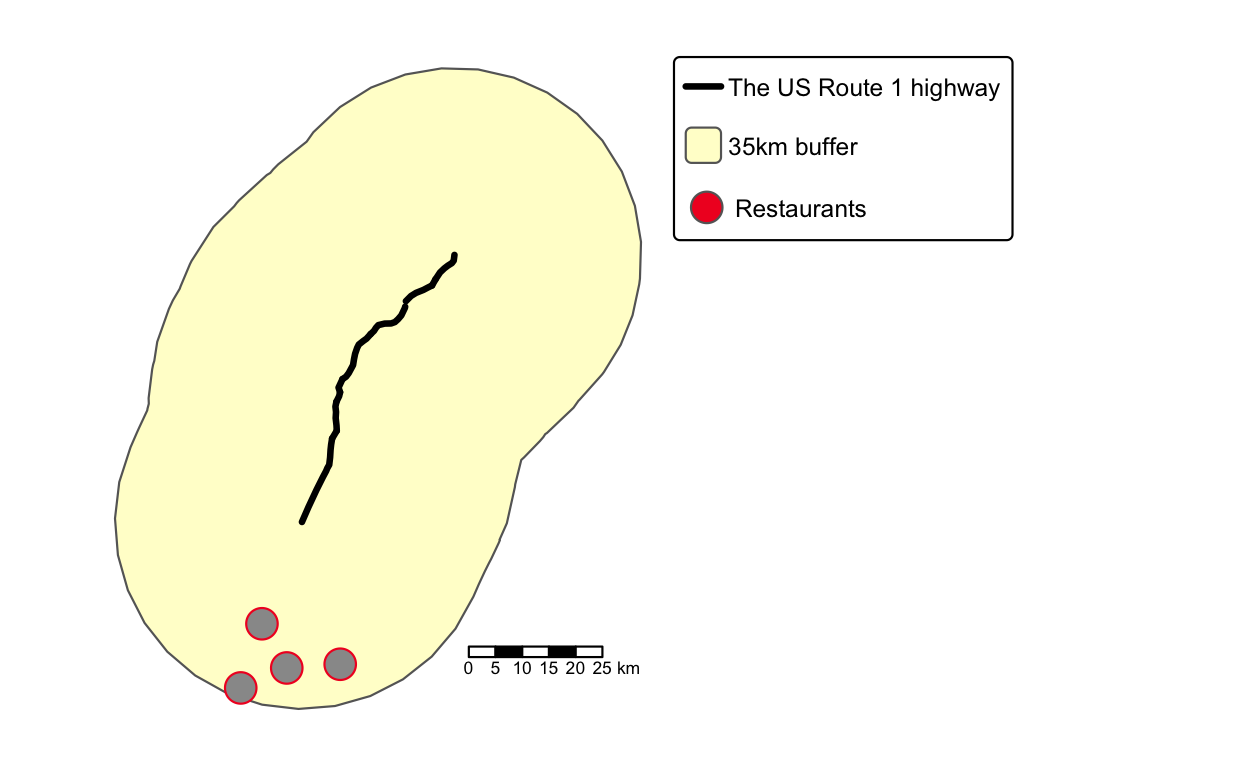
FIGURE 10.6: 直前の PostGIS コマンドによる出力の例。高速道路 (黒線)、バッファ (黄色)、バッファ内の 4 つのレストラン (赤点)。
PostGIS とは異なり、sf は空間ベクタデータのみをサポートしている。
PostGIS データベースに格納されたラスタデータを照会・操作するには、rpostgis パッケージ (Bucklin and Basille 2018)、または PostGIS インストールの一部に含まれる rastertopgsql などのコマンドラインツールを使用する必要がある。
このサブセクションでは、PostgreSQL/PostGIS の簡単な紹介にとどめる。 それでも、地理的および非地理的データを空間 DBMS で保存しながら、さらなる (地理) 統計解析に必要なそれらのサブセットだけを R のグローバル環境にアタッチするという実践を奨励したい。 提示された SQL クエリのより詳細な説明と PostgreSQL/PostGIS 一般のより包括的な紹介は Obe and Hsu (2015) を参照。 PostgreSQL/PostGIS は、非常に難解なオープンソースの空間データベースである。 しかし、軽量なデータベースエンジンである SQLite/SpatiaLite や、バックグラウンドで SQLite を使用する GRASS GIS も同様と言える (Section 10.4 参照)。
データセットが PostgreSQL/PostGIS では大きすぎる場合、大規模な空間データ管理とクエリ性能を必要とする場合、分散コンピューティングシステム上での大規模な地理クエリを検討する価値があるかもしれない。 このようなシステムは本書の範囲外ではあるが、この機能を提供するオープンソースソフトウェアが存在することは触れておく価値がある。 この分野の著名なプロジェクトには、GeoMesa と Apache Sedona がある。 後者については、apache.sedona パッケージがインタフェースを提供している。
10.8 クラウドへのブリッジ
近年、インターネット上では、クラウド技術の利用が目立ってきている。 この中には、空間データの保存や処理に利用されることも含まれている。 Amazon Web Services、Microsoft Azure / Planetary Computer、Google Cloud Platform などの主要なクラウドコンピューティングプロバイダは、Sentinel-2 アーカイブのようなオープンな地球観測データの巨大なカタログをプラットフォーム上で提供している。 R を使えば、これらのアーカイブから直接データに接続し、処理することができる。理想的には、同じクラウドや地域のマシンから接続することができる。
このような画像アーカイブをクラウド上でより簡単に、より効率的に利用するために、SpatioTemporal Asset Catalog (STAC)、cloud-optimized GeoTIFF (COG) 画像形式、データキューブが有望視されている。 Section 10.8.1 では、これらの個々の開発について紹介し、R からどのように利用できるかを簡単に説明する。
ここ数年、大規模なデータアーカイブをホストするだけでなく、地球観測データを処理するクラウドベースのサービスも多数始まっている。 その中には、R を含むプログラミング言語と様々なクラウドサービスとの間の統一的なインタフェースである OpenEO イニシアチブも含まれている。 OpenEO の詳細については、Section 10.8.2 を参照。
10.8.1 クラウドの STAC、COG、その他のデータキューブ
STAC (SpatioTemporal Asset Catalog) は、時空間データの汎用記述フォーマットで、画像、合成開口レーダー (synthetic aperture radar, SAR) データ、点群など、クラウド上の様々なデータセットの記述に使用されている。 STAC-API は、単純な静的カタログ記述の他に、カタログのアイテム (画像など) を空間、時間、その他のプロパティで照会するウェブサービスを提供している。 R では、rstac パッケージ (Simoes, Souza, et al. 2021) が STAC-API エンドポイントに接続し、アイテムを検索することができる。 以下の例では、Sentinel-2 Cloud-Optimized GeoTIFF (COG) dataset on Amazon Web Services から、事前に定義した関心領域と時間に交差するすべての画像を要求している。 結果は、見つかったすべての画像とそのメタデータ (雲量など)、および AWS 上の実際のファイルを指す URL を含んでいる。
library(rstac)
# Sentinel-2 データの STAC-API endpoint に接続し、
# AOI と交差する画像を検索
s = stac("https://earth-search.aws.element84.com/v0")
items = s |>
stac_search(collections = "sentinel-s2-l2a-cogs",
bbox = c(7.1, 51.8, 7.2, 52.8),
datetime = "2020-01-01/2020-12-31") |>
post_request() |>
items_fetch()クラウドストレージはローカルのハードディスクとは異なり、従来の画像ファイル形式はクラウドベースのジオプロセシングではうまく機能しない。 クラウドに最適化された GeoTIFF は、画像の矩形部分や低解像度の画像の読み込みが非常に効率的になる。 GDAL (およびそれを使ったパッケージ) はすでに COG を扱うことができるので、R ユーザーであれば COG を扱うために何かをインストールする必要はない。 ただし、データ提供者のカタログを閲覧する際には、COG が利用可能であることが大きなプラスになることを覚えておこう。
領域が大きい時、要求された画像を扱うのはまだ比較的困難である。それらは異なる地図投影を使用することがあり、空間的に重なることがあり、空間解像度はしばしばスペクトルバンドに依存する。 gdalcubes パッケージ (Appel and Pebesma 2019) は、個々の画像から抽象化し、画像コレクションを 4 次元データキューブとして作成し処理するために使用することができる。
以下のコードは、前回の STAC-API 検索で返された Sentinel-2 画像から、低解像度 (250 m) の最大 NDVI コンポジットを作成する最小限の例を示している。
library(gdalcubes)
# クラウドカバーで画像をフィルタし、画像コレクションを生成
cloud_filter = function(x) {
x[["eo:cloud_cover"]] < 10
}
collection = stac_image_collection(items$features,
property_filter = cloud_filter)
# データキューブの範囲、解像度 (250m、毎日)、CRS を定義
v = cube_view(srs = "EPSG:3857", extent = collection, dx = 250, dy = 250,
dt = "P1D") # "P1D" は ISO 8601 期間文字列
# データキューブを生成し処理
cube = raster_cube(collection, v) |>
select_bands(c("B04", "B08")) |>
apply_pixel("(B08-B04)/(B08+B04)", "NDVI") |>
reduce_time("max(NDVI)")
# gdalcubes_options(parallel = 8)
# plot(cube, zlim = c(0, 1))クラウドカバーによる画像のフィルタリングを行うために、画像コレクションを作成する際に各 STAC 結果アイテムに適用されるプロパティフィルタ関数を提供している。 この関数は、画像の利用可能なメタデータを入力リストとして受け取り、関数がTRUEを返す画像のみを考慮するような単一の論理値を返す。 この場合、10% 以上のクラウドカバーがある画像は無視する。 詳しくは、こちらの OpenGeoHub サマースクール 2021 で発表したチュートリアルを参照。77
STAC、COGs、データキューブ を組み合わせて、衛星画像の (大規模) コレクションをクラウド上で解析するクラウドネイティブワークフローを形成する. これらのツールは、例えば、大規模な地球観測データの土地利用や土地被覆の分類を可能にする sits パッケージのバックボーンを既に形成している。 このパッケージは、クラウドサービスで利用可能な画像コレクションから EO データキューブを構築し、様々な機械学習と真相学習アルゴリズムを用いてデータキューブの土地分類を実行するものである。 sits の詳細については、https://e-sensing.github.io/sitsbook/ または関連記事 (Simoes, Camara, et al. 2021) を参照。
10.8.2 openEO
OpenEO (Schramm et al. 2021) は、データ処理のための共通言語を定義することによって、クラウドサービス間の相互運用性を支援するイニシアチブである。 最初のアイデアはr-spatial.org blog postで説明されており、ユーザーができるだけ少ないコード変更で簡単にクラウドサービス間を変更できるようにすることを目的としている。 標準化プロセスでは、データへのインタフェースとして多次元データキューブモデルを使用している。 8 種類のバックエンドの実装が用意されており (https://hub.openeo.org)、ユーザーは R、Python、JavaScript、QGIS、Web エディタで接続し、コレクションに対してプロセスを定義 (およびチェーン) することができる。 バックエンドによって機能や利用できるデータが異なるため、openeo R パッケージ (Lahn 2021) は接続されたバックエンドから利用できるプロセスとコレクションを動的にロードする。 その後、ユーザーは画像コレクションのロード、プロセスの適用と連鎖、ジョブの送信、結果の探索とプロットを行うことができる。
以下のコードは、openEO platform backend に接続し、利用可能なデータセット、プロセス、出力フォーマットを要求し、Sentinel-2 データから最大 NDVI 画像を計算するプロセスグラフを定義し、最後にバックエンドにログインした後にグラフを実行する。 openEO プラットフォームのバックエンドには無料版があり、既存の機関やインターネットフォームのアカウントから登録することが可能である。
library(openeo)
con = connect(host = "https://openeo.cloud")
p = processes() # 利用可能なプロセスをロード
collections = list_collections() # 利用可能なコレクションをロード
formats = list_file_formats() # 利用可能な出力フォーマットをロード
# Sentinel-2 コレクションをロード
s2 = p$load_collection(id = "SENTINEL2_L2A",
spatial_extent = list(west = 7.5, east = 8.5,
north = 51.1, south = 50.1),
temporal_extent = list("2021-01-01", "2021-01-31"),
bands = list("B04", "B08"))
# NDVI vegetation index を計算
compute_ndvi = p$reduce_dimension(data = s2, dimension = "bands",
reducer = function(data, context) {
(data[2] - data[1]) / (data[2] + data[1])
})
# maximum over time を計算
reduce_max = p$reduce_dimension(data = compute_ndvi, dimension = "t",
reducer = function(x, y) {
max(x)
})
# GeoTIFF で出力
result = p$save_result(reduce_max, formats$output$GTiff)
# ログイン https://docs.openeo.cloud/getting-started/r/#authentication 参照
login(login_type = "oidc", provider = "egi",
config = list(client_id = "...", secret = "..."))
# プロセスを実行
compute_result(graph = result, output_file = tempfile(fileext = ".tif"))10.9 演習
E1. qgisprocess で r.sun GRASS GIS を使用して、system.file("raster/dem.tif", package = "spDataLarge") の3月21日午前11時の全球日射量を計算しなさい。
E2. **Rsagacmd* を使い、system.file("raster/dem.tif", package = "spDataLarge") の集水域と集水勾配を計算しなさい。
E3. SAGA セクションで作成した ndvi_segments オブジェクトの作業を続けなさい。
ndvi ラスターから平均 NDVI 値を抽出し、kmeans() を使用して 6 つのクラスターにグループ化しなさい。
結果を可視化しなさい。
E4. data(random_points, package = "spDataLarge") をアタッチし、 system.file("raster/dem.tif", package = "spDataLarge") を R に読み込みなさい。
random_points からランダムに点を選択し、この点から見えるすべての dem ピクセルを見つけなさい (ヒント: viewhedindex{viewshed} は GRASS GIS を使って計算できる)。
結果を視覚化する。
例えば、hillshade、digital elevation model、viewhed 出力、ポイントをプロットしなさい。
さらに、mapview を試してみよう。
E5. システムコールで gdalinfo を 使い、好きなディスクに保存されているラスタファイルを見なさい。
どのような情報があるか?
E6. gdalwarp を使ってラスタファイルの解像度を下げなさい (例えば、解像度が 0.5 の場合、それを 1 に変更する)。注意: この演習では -tr と -r フラグを使用する。
E7. この章で紹介したクラウド QGIS にある PostgreSQL/PostGIS データベースからすべてのカリフォルニアの高速道路をクエリしなさい。
E8. ndvi.tif ラスタ (system.file("raster/ndvi.tif", package = "spDataLarge")) は、2000年9月22日のランドサットデータに基づいて Mongón の調査地域で計算された NDVI を含んでいる。
rstac、gdalcubes、および terra を使用して、同じエリアの Sentinel-2 の画像をダウンロードしなさい。
2020-08-01 から 2020-10-31 までの Sentinel-2 画像をダウンロードし、NDVI を計算し、ndvi.tifの結果と比較しなさい。