12 統計的学習
必須パッケージ
本章では、Chapter 2 から Chapter 7 までの内容を学習し、演習を行うなどして、地理データ解析 に習熟していることを前提としている。 一般化線形モデル (Generalized Linear Model, GLM) と機械学習に精通していることを強く推奨する James et al. (2013)。
この章では、以下のパッケージを使用する。84
library(sf)
library(terra)
library(dplyr)
library(future) # 並列処理
library(lgr) # logging framework for R
library(mlr3) # 機械学習アルゴリズムへの統一インターフェース
library(mlr3learners) # 最重要の機械学習アルゴリズム
library(mlr3extralearners) # その他の機械学習アルゴリズム
library(mlr3spatiotempcv) # 時空間リサンプリング
library(mlr3proba) # mlr3extralearners::list_learners() が使う
library(mlr3tuning) # ハイパーパラメータのチューニング
library(mlr3viz) # mlr3 オブジェクトのプロット関数
library(progressr) # 進捗状況を報告
library(pROC) # ROC 値を計算データは必要に応じて読み込む。
12.1 イントロダクション
統計的学習は、データのパターンを特定し、そのパターンから予測するための統計的・計算的モデルの使用に関するものである。 その起源から、統計的学習は R の の大きな強みの一つである ( Section 1.4 参照)。85 統計的学習とは、統計学と機械学習の手法を組み合わせたもので、教師あり手法と教師なし手法に分類される。 どちらも物理学、生物学、生態学から地理学、経済学に至るまで、ますます多くの分野で利用されるようになっている (James et al. 2013)。
この章では、クラスタリングのような教師なし技術ではなく、学習データセットが存在する教師あり技術に焦点を当てていきたい。 応答変数は、二値 (地すべりの発生など)、カテゴリ (土地利用)、整数 (種の豊富さ)、数値 (土壌酸性度の pH 測定値) のいずれでもよい。 教師あり技術は、観測のサンプルについて既知の応答と、1 つまたは複数の予測変数の間の関係をモデル化する。
多くの機械学習において、研究の主な目的は優れた予測を行うことである。 機械学習が「ビッグデータ」の時代に繁栄しているのは、その手法が入力変数に関する仮定をほとんど必要とせず、巨大なデータセットを扱えるからである。 機械学習は、将来の顧客行動予測、推奨サービス (音楽、映画、次に買うもの)、顔認識、自律走行、テキスト分類、予知保全 (インフラ、産業) などのタスクに資するものである。
この章では、地すべりの発生モデルという事例をもとに説明する。 この応用例は、Chapter 1 で定義されているジオコンピュテーションの応用的な性質とリンクしており、機械学習が、予測を唯一の目的とする場合に統計学の分野から借用する方法を示している。 そこで、この章では、まず、GLM (A. Zuur et al. 2009) の助けを借りて、モデリングと交差検証 (cross validation, CV) の概念を紹介する。 これを踏まえて、この章では、より典型的な機械学習 アルゴリズム 、すなわちサポートベクタマシン (Support Vector Machine, SVM) を実装している。 モデルの予測性能は、地理データが特殊であることを考慮した空間交差検証 (空間 CV) を用いて評価していこう。
CV データセットをトレーニングセットとテストセットに (繰り返し) 分割することで、モデルが新しいデータに対して汎化する能力を決定する。 学習データを使ってモデルを適合させ、テストデータに対して予測したときの性能をチェックする。 CV は過適合を検出するのに役立つ。なぜなら、学習データをあまりに忠実に予測するモデル (ノイズ) は、テストデータでのパフォーマンスが低くなる傾向があるからである。
空間データをランダムに分割することで、テスト点と空間的に隣接する学習点を得ることができる。 空間的に自己相関していると、このシナリオではテストとトレーニングのデータセットが独立しておらず、結果として CV は過適合の可能性を検出できなくなる。 空間交差検証 は、本章の中心テーマであり、この問題を軽減する。。
繰り返しになるが、この章ではモデルの予測性能に焦点を当てる。 予測地図は扱わない。 これは、Chapter 15 で扱う。
12.2 ケーススタディ: 地すべりの発生しやすさ
このケーススタディは、Ecuador 南部の地すべり地点のデータセットに基づいている。図は Figure 12.1、詳細は Muenchow, Brenning, and Richter (2012) で説明されている。 論文で使用されたデータセットの部分集合は spDataLarge パッケージで提供されており、以下のように読み込むことができる。
data("lsl", "study_mask", package = "spDataLarge")
ta = terra::rast(system.file("raster/ta.tif", package = "spDataLarge"))上記のコードでは、lsl、sf という名前の data.frame、study_mask という名前の sf オブジェクト、そして ta (Section 2.3.4 を参照) という名前の地形属性ラスタ SpatRaster という 3 つのオブジェクトをロードしている。
lsl は要因列 lslpts を含み、TRUEは観測された地すべり「開始点」に対応し、座標は列 x と y に格納されている。 86
summary(lsl$lslpts) に示すように、地すべり地点が 175 箇所、非地すべり地点が 175 箇所ある。
非地すべり点 175 点は、地すべりポリゴン周辺の小さな緩衝地帯の外に位置しなければならないという制約のもと、調査地域からランダムにサンプル化されたものである。
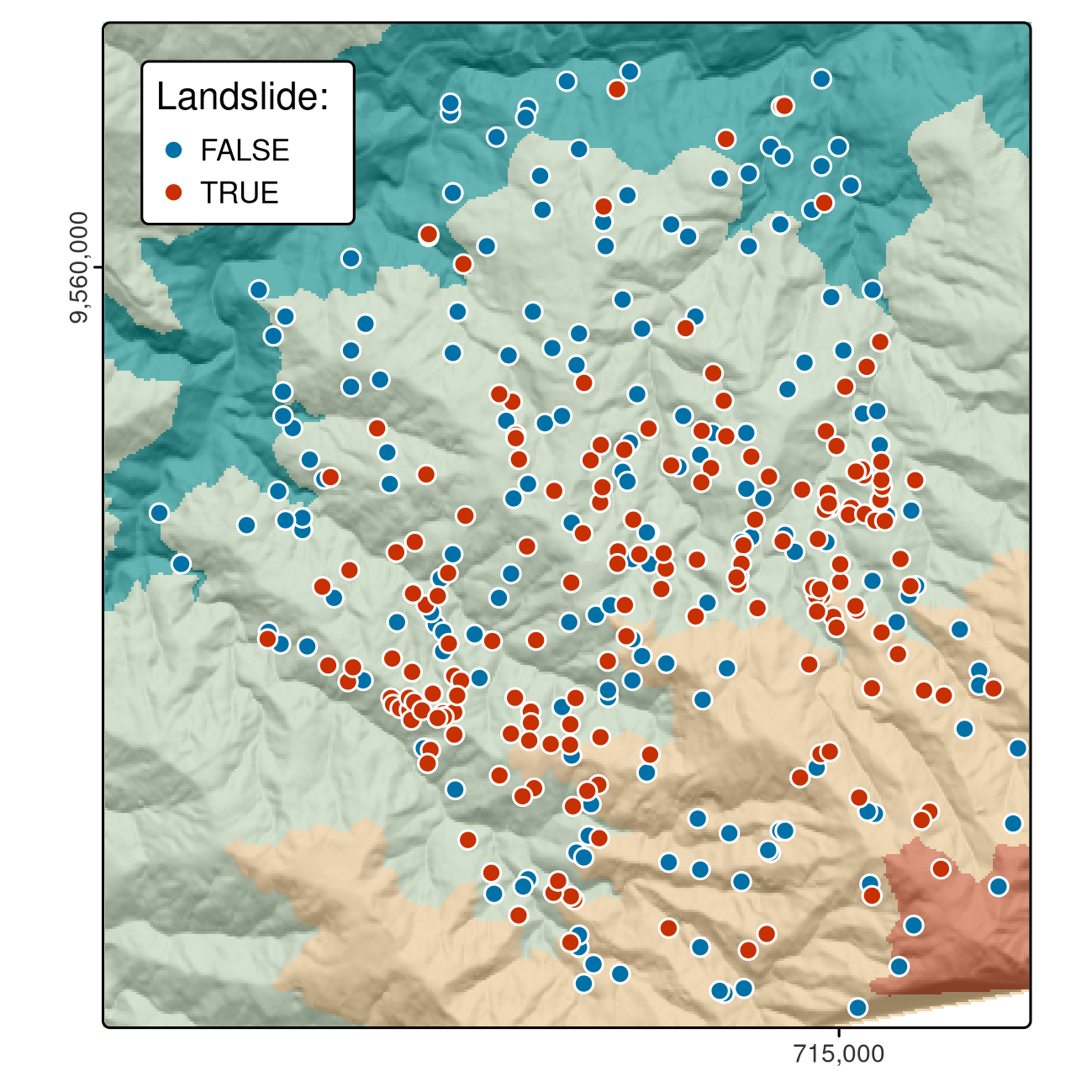
FIGURE 12.1: Ecuador 南部における地すべり発生地点 (赤) と地すべりの影響を受けていない地点 (青)。
Table 12.1 に、lsl の最初の 3 行を有効数字 2 桁に丸めたものを掲載している。
| x | y | lslpts | slope | cplan | cprof | elev | log10_carea | |
|---|---|---|---|---|---|---|---|---|
| 1 | 713888 | 9558537 | FALSE | 34 | 0.023 | 0.003 | 2400 | 2.8 |
| 2 | 712788 | 9558917 | FALSE | 39 | -0.039 | -0.017 | 2100 | 4.1 |
| 350 | 713826 | 9559078 | TRUE | 35 | 0.020 | -0.003 | 2400 | 3.2 |
地すべりの発生しやすさをモデル化するためには、いくつかの予測因子が必要である。
地形属性は地すべりと関連することが多いので (Muenchow, Brenning, and Richter 2012)、すでに ta から lsl まで、以下の地形属性を抽出している。
-
slope: 傾斜角 (°) -
cplan: 斜面の収束・発散を表す平面曲率 (rad m-1) で、水の流れを表現する。 -
cprof: 流れの加速度の指標としてのプロファイル曲率 (rad m-1)、傾斜角のダウンスロープ変化としても知られている。 -
elev: 調査地域の植生と降水量の異なる標高帯を表す標高 (m a.s.l.) -
log10_carea: ある地点に向かって流れる水の量を表す集水面積の十進対数 (log10 m2) のこと。
R-GIS ブリッジ (Chapter 10 参照) を用いて地形属性を計算し、地すべり地点に抽出することは、有意義な演習となるだろう (本章末の演習の項参照)。
12.3 R による従来のモデリング手法
何十もの学習アルゴリズムへの統一的なインタフェースを提供するアンブレラパッケージである mlr3 パッケージを紹介する (Section 12.5) が、その前に R の従来のモデリングインタフェースについて見ておく価値がある。 この教師あり統計学習の入門は、空間交差検証 を行うための基礎となり、この後に紹介する mlr3 のアプローチの把握に貢献する。
教師あり学習では、予測変数の関数として応答変数を予測する (Section 12.4)。
R では、モデリング関数は通常、数式を使って指定する (R の数式の詳細については、?formula を参照)。
次のコマンドは、一般化線形モデルを指定し、実行する。
3 つの入力引数のそれぞれを理解しておくとよいだろう。
- 地すべりの発生状況 (
lslpts) を予測変数の関数として指定した式 - モデルの種類を指定する family で、この場合は応答が二値なので
binomialとしている (?familyを参照) - 応答と予測変数 (列として) を含むデータフレーム
このモデルの結果を表示すると次のようになる (summary(fit) にはより詳細な説明がある)。
class(fit)
#> [1] "glm" "lm"
fit
#>
#> Call: glm(formula = lslpts ~ slope + cplan + cprof + elev + log10_carea,
#> family = binomial(), data = lsl)
#>
#> Coefficients:
#> (Intercept) slope cplan cprof elev log10_carea
#> 2.51e+00 7.90e-02 -2.89e+01 -1.76e+01 1.79e-04 -2.27e+00
#>
#> Degrees of Freedom: 349 Total (i.e. Null); 344 Residual
#> Null Deviance: 485
#> Residual Deviance: 373 AIC: 385クラス glm のモデルオブジェクト fit は、応答と予測変数の間の適合関係を定義する係数を含む。
また、予測にも利用することができる。
これは一般的な predict() メソッドで行われ、この場合、関数 predict.glm() を呼び出す。
type を response に設定すると、下図のように lsl の各観測値に対する (地すべり発生の) 予測確率が返される (?predict.glm を参照)。
pred_glm = predict(object = fit, type = "response")
head(pred_glm)
#> 1 2 3 4 5 6
#> 0.1901 0.1172 0.0952 0.2503 0.3382 0.1575予測ラスタに係数を適用することで、空間分布図を作成することができる。
これは、手動または terra::predict() で行うことができる。
モデルオブジェクト (fit) に加えて、後者の関数は、モデルの入力データフレーム (Figure 12.2) と同じ名前の予測子 (ラスタレイヤ) を持つ SpatRaster も必要とする。
# 予測する
pred = terra::predict(ta, model = fit, type = "response")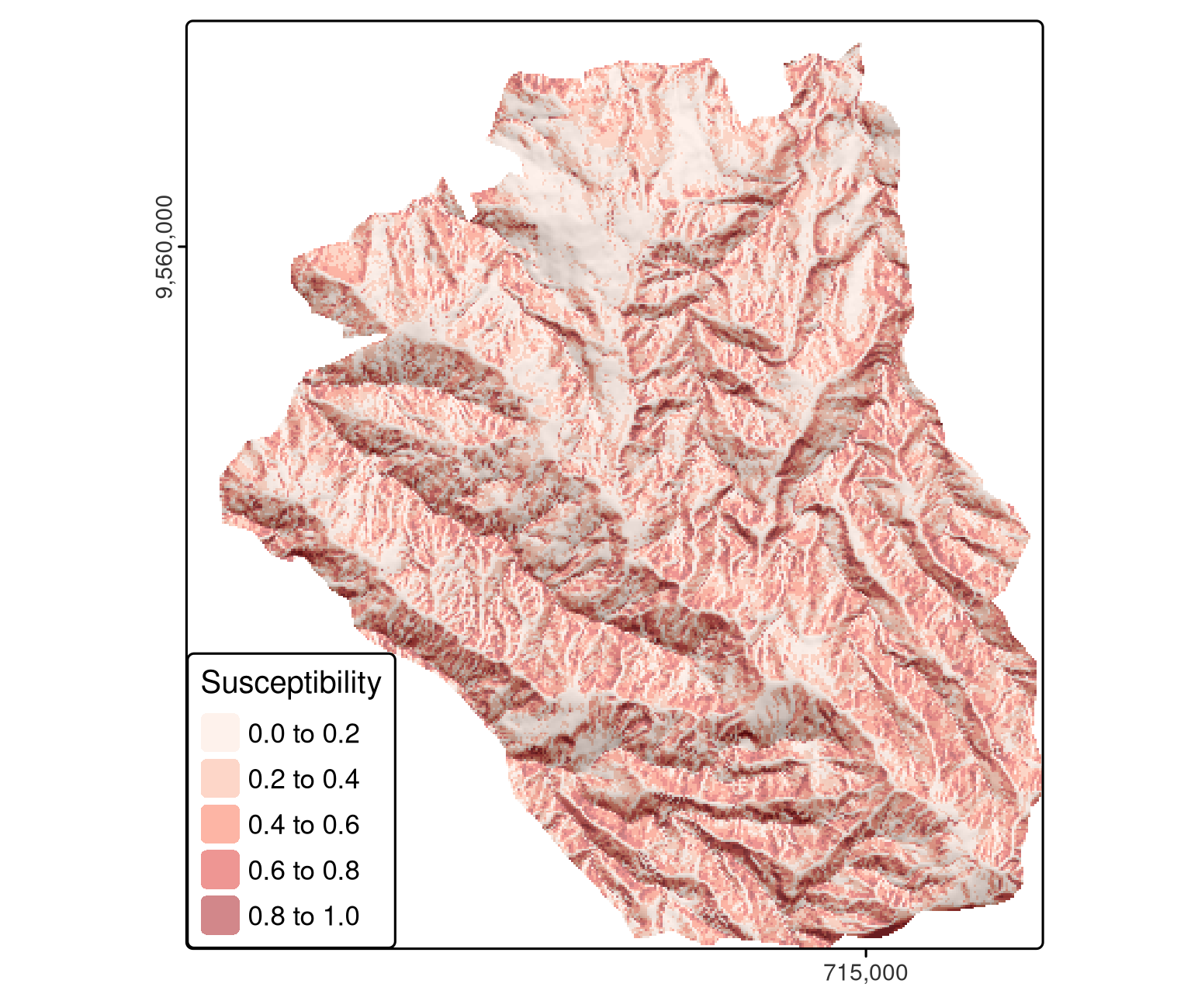
FIGURE 12.2: GLM を用いた地すべり感受性の空間分布図.
ここで、予測を行う際には、空間自己相関構造があってもなくても平均的に予測精度は変わらないと仮定しているため、空間自己相関を無視する。 空間自己相関 を、モデルと予測に組み入れることも可能である。 これは本書の範疇を越えるが、いくつかの資料を紹介する。
- 回帰クリギングの予測値は、回帰の予測値と回帰の残差のクリギングを組み合わせたものである (Goovaerts 1997; Hengl 2007; Bivand, Pebesma, and Gómez-Rubio 2013)。
- また、一般化最小二乗モデルに空間相関 (依存関係) 構造を追加することもできる (
nlme::gls(), A. Zuur et al. 2009; A. F. Zuur et al. 2017)。 - また、混合効果モデリング・アプローチを使用することもできる。 基本的に、ランダム効果は、応答変数に従属構造を課し、それによって、あるクラスの観測が、他のクラスの観測よりも互いに類似していることを可能にする (A. Zuur et al. 2009)。 クラスは、例えば、ハチの巣、フクロウの巣、植生トランセクト、標高の層別などである。 この混合モデリングのアプローチは、正規かつ独立に分布するランダム切片を仮定している。 これは、正規分布で空間的に依存するランダム切片を使用することによっても拡張することができる。 しかし、このためには、ベイズ・モデリング・アプローチに頼らなければならないだろう (Blangiardo and Cameletti 2015; A. F. Zuur et al. 2017)。
空間分布図は、モデルの非常に重要なアウトカムの一つである。
さらに重要なのは、モデルの予測性能が低ければ、予測マップは役に立たないので、基盤となるモデルがどれだけ優れているかということである。
二項モデルの予測性能を評価する最も一般的な尺度の一つは、Area Under the Receiver Operator Characteristic Curve (AUROC) である。
これは 0.5 から 1.0 の間の値で、0.5 はランダム化より良くないモデル、1.0 は 2 つのクラスを完全に予測することを示す。
したがって、AUROC が高いほど、モデルの予測力が優れていることになる。
次のコードチャンクは、応答と予測値を入力とする roc() を用いて、モデルの AUROC 値を計算するものである。
auc() は、曲線の下の面積を返す。
AUROC の値 0.82 は良好な適合性を示している。 しかし、これは完全なデータセットに対して計算したものであるため、楽観的すぎる推定値である。 偏りを抑えた評価を導き出すためには、交差検証を用いる必要があり、空間データの場合は空間交差検証 を利用する必要がある。
12.4 (空間) 交差検証の紹介
交差検証 は、リサンプリング法のファミリーに属する (James et al. 2013)。 基本的な考え方としては、データセットをトレーニングセットとテストセットに (繰り返し) 分割し、トレーニングデータを使ってモデルを適合させ、それをテストセットに適用する。 予測値とテストセットの既知の応答値を比較することにより (二項式の場合は AUROC のような性能指標を使用)、学習した関係を独立したデータに一般化するモデルの能力について、バイアスを低減した評価を得ることができる。 例えば、5 倍交差検証を 100 回繰り返すとは、データをランダムに 5 分割 (フォールド) し、各フォールドをテストセットとして 1 回使用することを意味する (Figure 12.3 の上段を参照)。 これは、各観測が 1 つのテストセットで 1 回使用されることを保証し、5 つのモデルの適合を必要とする。 その後、この手順を 100 回繰り返す。 もちろん、データの分割は繰り返しごとに異なる。 全体として、これは 500 のモデルに合計される。一方、すべてのモデルの平均性能指標 (AUROC) は、モデルの全体的な予測力である。
しかし、地理的なデータは特殊である。 Chapter 13 で見るように、地理学の「第一法則」は、互いに近い地点は、一般に、遠い地点よりも似ているとするものである (Miller 2004)。 つまり、従来の CV では学習点とテスト点が近すぎることが多いため、点が統計的に独立していないことになる (Figure 12.3 の最初の行を参照)。 「テスト」観測の近くにある「トレーニング」観測は、一種の「カンニング」を提供することができる。 すなわち、学習データセットでは利用できないはずの情報である。 この問題を軽減するために、観測を空間的に不連続なサブセットに分割する「空間分割」が使用される (k-means クラスタリングで観測の座標を使用; Brenning (2012b); Figure 12.3 の 2 行目)。 この分割戦略が、従来の CV との唯一の違いである。 その結果、空間 CV はモデルの予測性能のバイアスを低減させ、過適合を回避するのに役立つ。
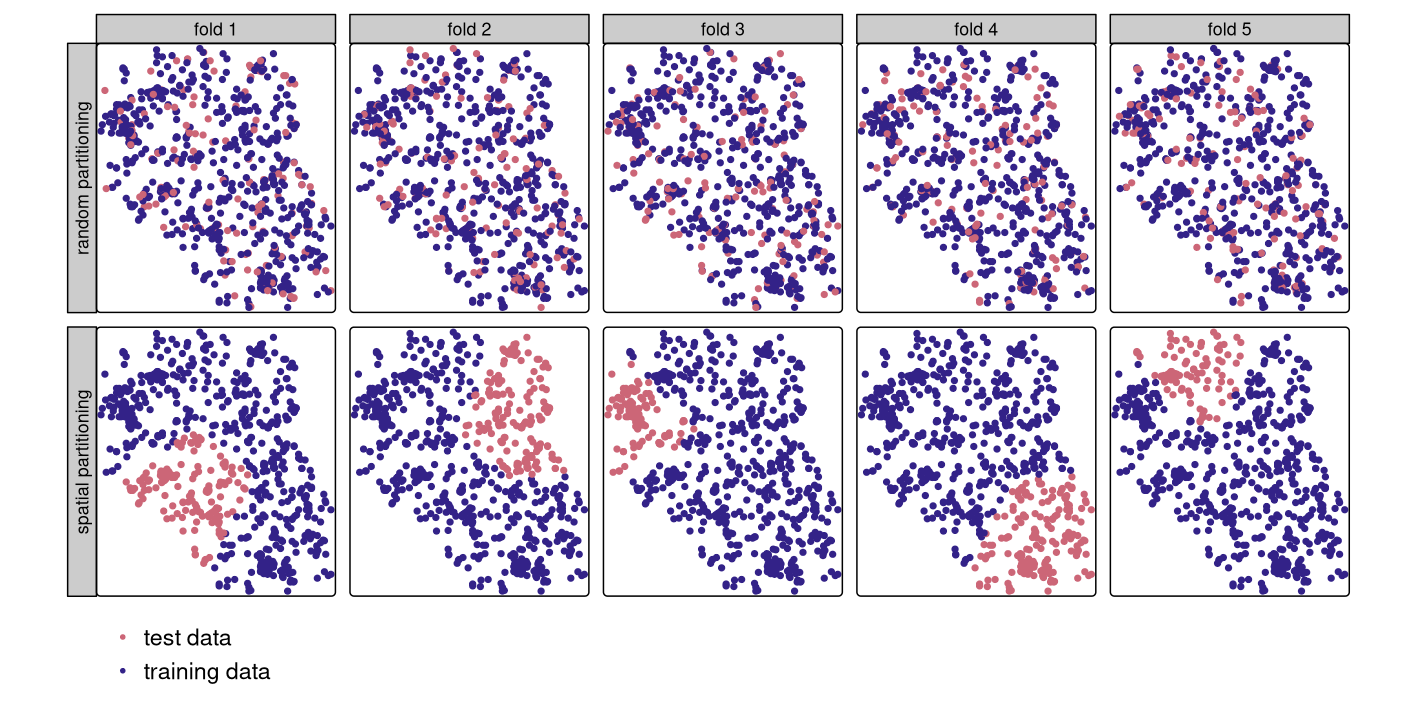
FIGURE 12.3: 1 回の繰り返しの交差検証で選択されたテストおよびトレーニングの観測の空間的な可視化。ランダム (上段) および空間分割 (下段)。
12.5 mlr3 を用いた空間交差検証
統計的学習のためのパッケージは何十種類もある。例えば CRAN machine learning task view で説明されている。 交差検証やハイパーパラメータのチューニング方法など、各パッケージに精通することは時間のかかる作業である。 異なるパッケージのモデル結果を比較するのは、さらに手間がかかる。 これらの問題を解決するために開発されたのが、mlr3 パッケージとエコシステムである。 これは「メタパッケージ」として機能し、分類、回帰 、生存時間分析、クラスタリングなど、一般的な教師あり・教師なしの統計学習技術への統一的なインタフェースを提供する (Lang et al. 2019; Bischl et al. 2024)。 標準化された mlr3 インターフェースは、8 つの「ビルディングブロック」に基づいている。 Figure 12.4 に示すように、これらは明確な順序を持っている。
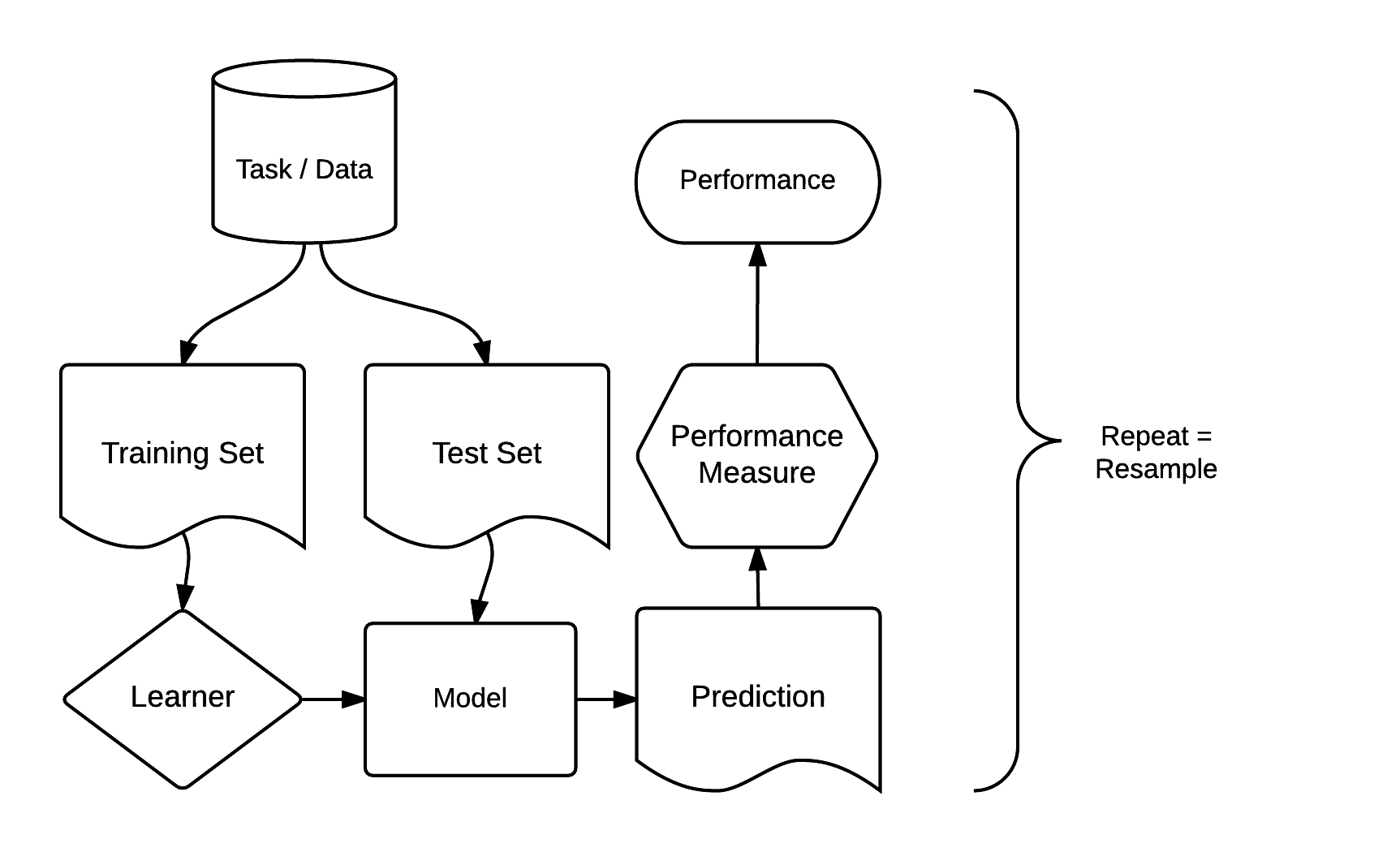
FIGURE 12.4: mlr3 パッケージの基本的な構成要素 (Bischl et al. 2024)。この図の再利用を快く承諾していただいた。
mlr3 のモデリングプロセスは、主に3つのステージで構成されている。 まず、task で、データ (応答変数と予測変数を含む) とモデルの種類 (回帰や分類など) を指定する。 次に、learnerは、作成されたタスクに適用される特定の学習アルゴリズムを定義する。 第三に、リサンプリングアプローチでは、モデルの予測性能、すなわち新しいデータへの汎化能力を評価する (Section 12.4 も参照)。
12.5.1 一般化線形モデル
GLM を mlr3 で使うためには、地すべりデータを含む task を作成する必要がある。
応答は二値 (2 カテゴリの変数) で、空間次元を持つので、mlr3spatiotempcv パッケージの as_task_classif_st() を使用し、分類タスクを作成する (Schratz et al. 2021 、非空間 task には mlr3::as_task_classif()、回帰には as_task_regr() を使用。他の task の詳細は、?Task を参照。) 。87
as_task_ 関数の最初の必須引数は、x である。
x は、入力データが応答変数と予測変数を含んでいることを想定している。
target の引数は応答変数の名前を示し (ここでは lslpts)、positive は応答変数の 2 つの因子レベルのうちどちらが地すべり開始点を示すかを決定する (ここでは TRUE)。
lsl データセットの他のすべての変数が予測因子として機能する。
空間 CV のためには、いくつかの追加引数を与える必要がある。
coordinate_names 引数は、座標列の名前を期待する (Section 12.4 と Figure 12.3 を参照)。
さらに、使用する CRS (crs) を示し、その座標を予測因子としてモデリング (coords_as_features) に使用するかどうかを決定する必要がある。
# 1. task を作成
task = mlr3spatiotempcv::as_task_classif_st(
mlr3::as_data_backend(lsl),
target = "lslpts",
id = "ecuador_lsl",
positive = "TRUE",
coordinate_names = c("x", "y"),
crs = "EPSG:32717",
coords_as_features = FALSE
)なお、mlr3spatiotempcv::as_task_classif_st() は、backend パラメータの入力として sf-オブジェクトも受け付ける。
この場合、引数 coords_as_features のみを追加して指定するとよいだろう。
lsl を sf-オブジェクトに変換しなかったのは、as_task_classif_st() がバックグラウンドで非空間的な data.table オブジェクトに戻してしまうだけだからである。
短時間のデータ探索では、mlr3viz パッケージの autoplot() 関数は、すべての予測因子に対する応答とすべての予測因子に対する応答をプロットするので便利だろう (図示していない)。
# 予測因子それぞれに対して応答をプロット
mlr3viz::autoplot(task, type = "duo")
# 変数それぞれに対して相互にプロット
mlr3viz::autoplot(task, type = "pairs")task を作成したら、使用する統計的学習方式を決定する 学習器 (learner) を選択する必要がある。
分類の学習器 は classif. で始まり、回帰の学習器は regr. で始まる (詳しくは ?Learner を参照)。
mlr3extralearners::list_mlr3learners() は、利用可能なすべての学習器と、どのパッケージから mlr3 がそれらをインポートしているかをリストアップする (Table 12.3)。
二値応答変数をモデル化できる学習器について調べるには、次のように実行する。
mlr3extralearners::list_mlr3learners(
filter = list(class = "classif", properties = "twoclass"),
select = c("id", "mlr3_package", "required_packages")) |>
head()| Class | Name | Short name | Package |
|---|---|---|---|
| classif.adaboostm1 | ada Boosting M1 | adaboostm1 | RWeka |
| classif.binomial | 二項回帰 | binomial | stats |
| classif.featureless | Featureless classifier | featureless | mlr |
| classif.fnn | Fast k-Nearest Neighbour | fnn | FNN |
| classif.gausspr | ガウス過程 | gausspr | kernlab |
| classif.IBk | k-近傍法 | ibk | RWeka |
これにより、すべての学習器が 2 クラス問題 (地すべりの有無) をモデル化することができるようになった。
Section 12.3 で使用され、mlr3learners では classif.log_reg として実装されている二項分類方式を選択することにする。
さらに、予測の種類を決める predict.type を指定する必要がある。prob は、地すべり発生の予測確率を 0 から 1 の間で決定する (これは type = response の predict.glm() に対応する)。
# 2. 学習器を指定
learner = mlr3::lrn("classif.log_reg", predict_type = "prob")学習器のヘルプページにアクセスし、どのパッケージから取得したものかを調べるには、次のように実行する。
learner$help()mlr3 でモデリングするためのセットアップ手順は、面倒に思えるだろう。
しかし、この一つのインターフェースで、mlr3extralearners::list_mlr3learners() が示す 130 種類以上の学習器にアクセスできることを思い出してほしい。各学習器のインターフェースを学ぶことはもっと退屈である。
さらに、リサンプリング技術の簡単な並列化と、機械学習のハイパーパラメータを調整できることも利点である (Section 12.5.2 を参照)。
最も重要なことは、mlr3spatiotempcv (Schratz et al. 2021) の (空間) リサンプリングは簡単で、リサンプリング法の指定と実行という 2 つのステップを追加するだけでよいということである。
100 回繰り返される 5 回空間交差検証 : task で提供された座標に基づいて 5 つのパーティションが選ばれ、パーティショニングは 100 回繰り返される。 88
# 3. リサンプリングを指定
resampling = mlr3::rsmp("repeated_spcv_coords", folds = 5, repeats = 100)空間リサンプリングを実行するために、先に指定したタスク、学習器、リサンプリング戦略を用いて、resample() を実行する。
500 個のリサンプリングパーティションと 500 個のモデルを計算するため、多少時間がかかる (最新のノートパソコンで 15 秒程度)。
性能指標として、今回も AUROC を選択した。
これを取得するために、リサンプリング結果出力オブジェクト (score_spcv_glm) の score() メソッドを使用する。
これは、500 行の data.table オブジェクトを返す。
# メッセージを減らす
lgr::get_logger("mlr3")$set_threshold("warn")
# 空間交差検証 を実行し、リサンプル結果 glm (rr_glm) に保存
rr_spcv_glm = mlr3::resample(task = task,
learner = learner,
resampling = resampling)
# AUROC を計算しデータフレームに格納
score_spcv_glm = rr_spcv_glm$score(measure = mlr3::msr("classif.auc"))
# 必要な列だけ残す
score_spcv_glm = dplyr::select(score_spcv_glm, task_id, learner_id,
resampling_id, classif.auc)前述のコードチャンクの出力は、モデルの予測性能のバイアスを低減した評価である。
書籍の GitHub リポジトリに extdata/12-bmr_score.rds として保存している。
必要であれば、以下のように読み込むことができる。
score = readRDS("extdata/12-bmr_score.rds")
score_spcv_glm = dplyr::filter(score, learner_id == "classif.log_reg",
resampling_id == "repeated_spcv_coords")全 500 モデルの平均 AUROC を計算するために、以下を実行した。
これらの結果を整理するために、100 回繰り返した 5 回非空間交差検証の AUROC 値と比較してみよう (Figure 12.5 ; 非空間CVのコードはここでは示さないが、演習セクションで検討する)。 予想通り (Section 12.4 参照)、空間交差検証の結果は、従来の交差検証アプローチよりも平均して低い AUROC 値をもたらし、空間自己相関のため、後者の空間自己相関による楽観的な予測性能が強調された。
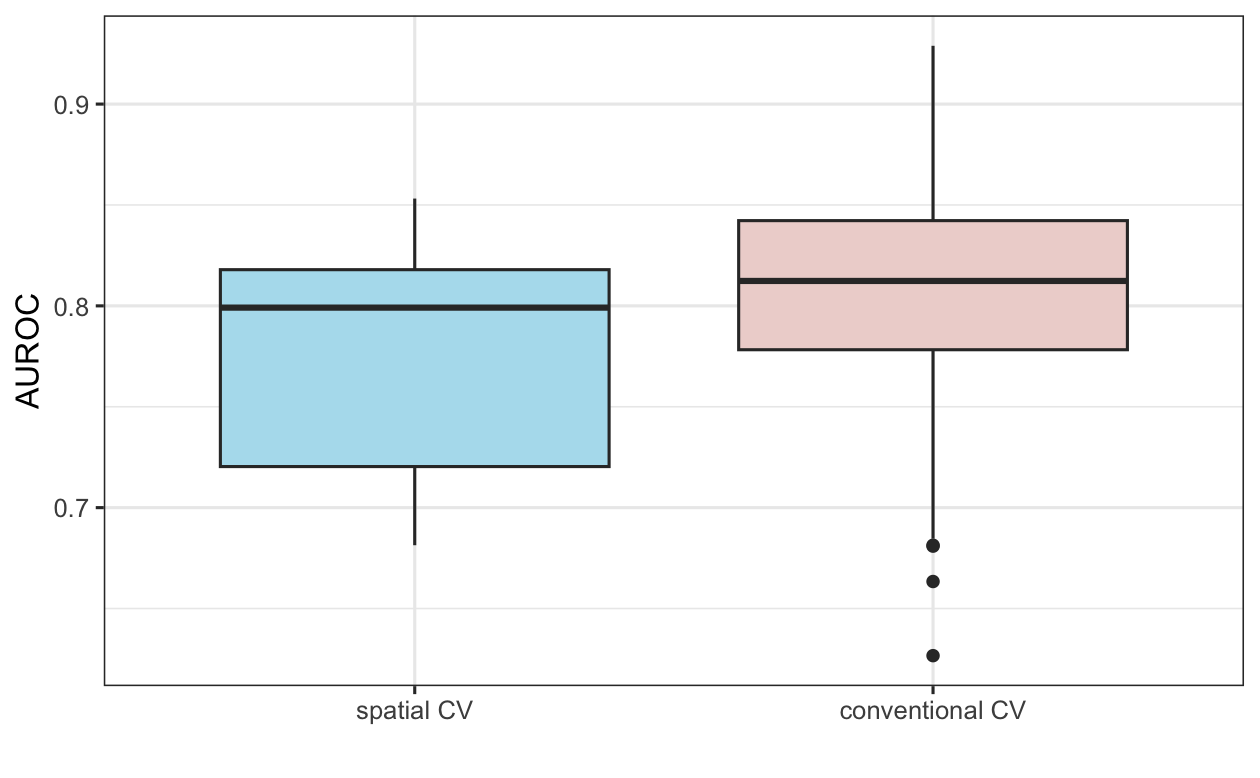
FIGURE 12.5: 空間CV と従来の 100 回繰り返し 5 回 CV におけるGLM AUROC 値の差を示す箱ひげ図。
12.5.2 機械学習のハイパーパラメータの空間的チューニング
Section 12.4 では、統計的学習の一環として、機械学習を導入した。 もう一度確認しよう。Jason Brownlee による機械学習の以下の定義に従う。
機械学習、より具体的には予測モデリングの分野では、説明可能性を犠牲にして、モデルの誤差を最小化すること、あるいは可能な限り正確な予測を行うことに主眼が置かれている。 応用機械学習では、統計学を含む多くの異なる分野からアルゴリズムを借用、再利用、盗用し、こうした目的のために使用する。
Section 12.5.1 では、GLM を用いて地すべりしやすさを予測した。 ここでは、同じ目的のためにサポートベクタマシン (Support Vector Machine, SVM)を紹介する。 ランダムフォレストモデルは SVM よりも人気があるだろう。しかし、ハイパーパラメータのチューニングがモデル性能に与えるプラスの効果は、SVM の場合の方が顕著である (Probst, Wright, and Boulesteix 2018)。 本節では、 (空間) ハイパーパラメータのチューニングが主な目的であるため、SVM を用いることにする。 ランダムフォレストモデルを適用したい方は、この章を読んでから Chapter 15 に進むことを勧める。この章では、現在取り上げられている概念と技術を応用して、ランダムフォレストモデルに基づく空間分布図を作成する方法を説明する。
SVM クラスを分離するための最適な「超平面」を探索し (分類 の場合)、特定のハイパーパラメータで「カーネル」を推定して、クラス間の非線形境界を作成する (James et al. 2013)。 機械学習には、ハイパーパラメータとパラメータがある。 パラメータはデータから推定できるが、ハイパーパラメータは学習開始前に設定しなければならない (mlr3 本のmachine mastery blogとhyperparameter optimization chapter も参照)。 最適なハイパーパラメータは、通常、交差検証法を用いて定義された範囲内で決定する。 これをハイパーパラメータチューニングという。
kernlab が提供 SVM 実装の中には、ハイパーパラメータを自動的に、通常はランダムなサンプルに基づいて調整することができるものもある (Figure 12.3 の上段を参照)。 これは非空間データでは有効だが、空間データではあまり意味がなく、「空間チューニング」を行う必要がある。
空間チューニングを定義する前に、Section 12.5.1 で紹介した mlr3 ビルディングブロックを SVM 用に設定することにする。
分類のタスクは変わらないので、Section 12.5.1 で作成した task オブジェクトを再利用すればよい。
SVM を実装している学習器は、mlr3extralearners パッケージの listLearners() を用いて検索することができる。
mlr3_learners = mlr3extralearners::list_mlr3learners()
#> This will take a few seconds.
mlr3_learners |>
dplyr::filter(class == "classif" & grepl("svm", id)) |>
dplyr::select(id, class, mlr3_package, required_packages)
#> id class mlr3_package required_packages
#> <char> <char> <char> <list>
#> 1: classif.ksvm classif mlr3extralearners mlr3,mlr3extralearners,kernlab
#> 2: classif.lssvm classif mlr3extralearners mlr3,mlr3extralearners,kernlab
#> 3: classif.svm classif mlr3learners mlr3,mlr3learners,e1071オプションのうち、kernlab パッケージの ksvm() を使用することにする (Karatzoglou et al. 2004)。
非線形関係を許容するために、ksvm() のデフォルトでもある、一般的な放射状基底関数 (またはガウス) カーネル ("rbfdot") を使用する。
type 引数に "C-svc" を設定することで、ksvm() が確実に分類タスクを解く。
1 つのモデルの失敗でチューニングが止まらないように、フォールバック学習器を追加で定義している (詳細は https://mlr3book.mlr-org.com/chapters/chapter10/advanced_technical_aspects_of_mlr3.html#sec-fallback を参照)。
lrn_ksvm = mlr3::lrn("classif.ksvm", predict_type = "prob", kernel = "rbfdot",
type = "C-svc")
lrn_ksvm$encapsulate(method = "try",
fallback = lrn("classif.featureless",
predict_type = "prob"))次の段階は、リサンプリング戦略を指定することである。 ここでも 100 回繰り返しの 5 回空間交差検証を使用する。
# パフォーマンス推定レベル
perf_level = mlr3::rsmp("repeated_spcv_coords", folds = 5, repeats = 100)これは Section 12.5.1 の GLM のリサンプリングに使われたコードと全く同じであることに注意しておこう。
ここまでは、Section 12.5.1 で説明したものと同じである。 しかし、次のステップは新しく、ハイパーパラメータ を調整する。 性能評価とチューニングに同じデータを使用すると、楽観的すぎる結果になる可能性がある (Cawley and Talbot 2010)。 これは、ネストされた空間交差検証 を用いることで回避することができる。
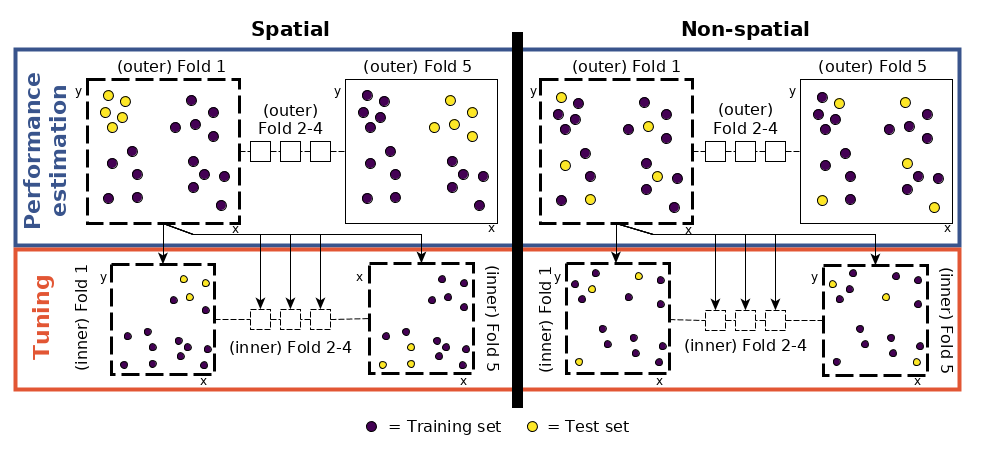
FIGURE 12.6: CV におけるハイパーパラメータのチューニングと性能推定レベルの模式図 (図は Schratz et al. (2019) から引用した。快く再利用の許可をいただいた)。
これは、各フォールドを空間的に不連続な 5 つのサブフォールドに再び分割し、最適なハイパーパラメータ (tune_level 以下のコードチャンクのオブジェクト。視覚的表現については Figure 12.6 を参照) を決定するために使用することを意味する。
さらに、値 C と Sigma のランダムな選択は、あらかじめ定義された調整空間 (search_space オブジェクト) に制限されている。
同調空間の範囲は、文献で推奨されている値で選択した (Schratz et al. 2019)。
最適なハイパーパラメータの組み合わせを見つけるために、これらのサブフォルダそれぞれにおいて、ハイパーパラメータ C とシグマにランダムな値を選択して 50 のモデル (以下のコードチャンクの terminator オブジェクト) を適合させた。
# 5つに分割
tune_level = mlr3::rsmp("spcv_coords", folds = 5)
# ランダムに選択されたハイパーパラメータの限界値を定義
search_space = paradox::ps(
C = paradox::p_dbl(lower = -12, upper = 15, trafo = function(x) 2^x),
sigma = paradox::p_dbl(lower = -15, upper = 6, trafo = function(x) 2^x)
)
# 50 個のランダムに選択されたハイパーパラメータを使用
terminator = mlr3tuning::trm("evals", n_evals = 50)
tuner = mlr3tuning::tnr("random_search")次の段階は、auto_tuner() を用いてハイパーパラメータチューニングを定義するすべての特性に従って学習器 lrn_ksvm を修正することである。
at_ksvm = mlr3tuning::auto_tuner(
learner = lrn_ksvm,
resampling = tune_level,
measure = mlr3::msr("classif.auc"),
search_space = search_space,
terminator = terminator,
tuner = tuner
)このチューニングは、1 つのフォールドに対して最適なハイパーパラメータを決定するために、250 のモデルを適合させるように設定されている。 これを 1 回ずつ繰り返すと、1,250 個 (250 * 5) のモデルができあがる。 100 回繰り返すということは、合計 125,000 個のモデルを適合して最適なハイパーパラメータ( Figure 12.3 )を特定することになる。 これを性能推定に使用し、さらに 500 個のモデル (5 folds * 100 repetitions; Figure 12.3 参照) の適合が必要である。 性能推定処理の連鎖をさらにわかりやすくするために、コンピュータに与えた命令を書き出してみよう。
- パフォーマンスレベル ( Figure 12.6 の左上部分) - データセットを 5 つの空間的に不連続な (外側の) サブフォールドに分割する。
- チューニング・レベル ( Figure 12.6 の左下部分) - パフォーマンス・レベルの最初のフォールドを使用し、ハイパーパラメータのチューニングのために、それを再び 5 つの (内側の) サブフォールドに空間的に分割する。 これらの内部サブフォールドのそれぞれで、ランダムに選択された 50 個のハイパーパラメータを使用する、つまり、250 個のモデルを適合させる。
- 性能推定 - 前のステップ (チューニング・レベル) から最適なハイパーパラメータの組み合わせを使用し、性能レベルの最初の外側のフォールドに適用して性能を推定する (AUROC )。
- 残りの 4 つの外側のフォールドについて、手順 2 と 3 を繰り返す
- 手順 2~4 を 100 回繰り返す
ハイパーパラメータのチューニングと性能推定のプロセスには、計算量が必要である。 モデルの実行時間を短縮するために、mlr3 では、future パッケージの助けを借りて、並列化を使用する可能性を提供している。 これからネストした CV を実行するので、内側ループと外側ループのどちらを並列化するか決めることができる (Figure 12.6 の左下部分を参照)。 前者は 125,000 個のモデルを実行するのに対し、後者は 500 個しか実行しないので、内側のループを並列化するのは当然である。 内側のループの並列化を設定するために、実行する。
library(future)
# 外側のループを順次実行し、内側のループを並列化する。
future::plan(list("sequential", "multisession"),
workers = floor(availableCores() / 2))さらに、future には、利用可能なすべてのコア (デフォルト) ではなく、半分だけを使用するように指示した。これは、1 つのコアを使用する場合に、他のユーザーが同じ高性能計算機クラスタで作業する可能性を考慮した設定である。
これで、ネストされた空間交差検証を計算するための準備ができた。
resample() パラメータの指定は、GLM を使用したときと全く同じ手順で行う。唯一の違いは、store_models と encapsulate の引数である。
前者を TRUE に設定すると、ハイパーパラメータのチューニング結果を抽出できる。これは、チューニングに関するフォローアップ分析を計画する場合に重要である。
後者は、モデルの 1 つがエラーを投げても処理が継続されるようにするものである。
これにより、1 つのモデルが失敗しただけで処理が停止することを避けることができ、大規模なモデルの実行には望ましい。
処理が完了すると、故障したモデルを見ることができる。
処理終了後、future::ClusterRegistry("stop") で明示的に並列化を停止するのがよいだろう。
最後に、出力オブジェクト (result) を、別の R セッションで使用する場合に備えてディスクに保存する。
125,500 個のモデルで空間交差検証を行うため、時間がかかることをご了承の上、実行してみよう。
現代のコンピュータで、たった半日で実行できる。
実行時間は、CPU 速度、選択したアルゴリズム、選択したコア数、データセットなど多くの側面に依存することに注意しておこう。
progressr::with_progress(expr = {
rr_spcv_svm = mlr3::resample(task = task,
learner = at_ksvm,
# 外側リサンプリング (パフォーマンスレベル)
resampling = perf_level,
store_models = FALSE,
encapsulate = "evaluate")
})
# 並列化を終了
future:::ClusterRegistry("stop")
# AUROC 値を計算
score_spcv_svm = rr_spcv_svm$score(measure = mlr3::msr("classif.auc")) %>%
# 必要な列のみ残す
score_spcv_svm = dplyr::select(score_spcv_svm, task_id, learner_id,
resampling_id, classif.auc)ローカルでコードを実行したくない方のために、書籍の GitHub リポジトリに score_svm を保存してある。 以下のように読み込むことができる。
score = readRDS("extdata/12-bmr_score.rds")
score_spcv_svm = score[learner_id == "classif.ksvm.tuned" &
resampling_id == "repeated_spcv_coords"]最終的な AUROC: モデルが 2 つのクラスを識別する能力を見てみよう。
GLM は、この特定のケースでは、SVM よりもわずかに優れているようである (集計された AUROC は 0.77)。
絶対的に公平な比較を保証するためには、2 つのモデルが全く同じパーティションを使用していることを確認する必要がある。ここでは示していないが、バックグラウンドで黙々と使用しているものである (詳しくは本書の GitHub リポジトリにある code/12_cv.R を参照)。
そのために、mlr3 は関数 benchmark_grid() と benchmark() を提供している (https://mlr3book.mlr-org.com/chapters/chapter3/evaluation_and_benchmarking.html#sec-benchmarking, Bischl et al. 2024 参照) 。
これらの機能については、「演習」でより詳しく解説する。
また、SVM のランダムな探索に 50 回以上の反復を使用すると、おそらくより良い AUROC (Schratz et al. 2019) を持つモデルになるハイパーパラメータが得られるであろうことに注意しておこう。
一方、ランダムサーチの反復回数を増やすと、モデルの総数も増え、その分実行時間も長くなる。
これまで、空間交差検証 は、学習アルゴリズムが未知のデータに対して汎化する能力を評価するために利用されていた。 空間分布図作成では、完全なデータセットでハイパーパラメータを調整する。 これについては、Chapter 15 で説明する。
12.6 結論
リサンプリング手法は、データサイエンティストのツールボックスの重要なものの一つである (James et al. 2013)。 この章では、CV を用いて、様々なモデルの予測性能を評価した。 Section 12.4 で述べたように、空間座標を持つ観測は、空間自己相関のために統計的に独立でない場合があり、交差検証の基本的な仮定に違反する。 空間交差検証 この問題は、空間的自己相関によってもたらされるバイアスを低減することで解決される。
mlr3 パッケージは、線形回帰、一般化加法モデルなどのセミパラメトリックモデルなどの統計学習、あるいはランダムフォレスト、SVM 、ブースト回帰木 (Bischl et al. 2016; Schratz et al. 2019) などの機械学習 技術と組み合わせることで、 (空間) リサンプリング技法を容易にしている。 機械学習アルゴリズムは、ハイパーパラメータの入力を必要とすることがある。その最適な「チューニング」には、大規模な計算資源を必要とする数千回のモデル実行が必要で、多くの時間、RAM、コアを消費することがある。 mlr3 は、並列化を可能にすることでこの問題に取り組んでいる。
機械学習全体、そして空間データを理解するための機械学習は大きな分野であり、この章では基本的なことを説明したが、まだまだ学ぶべきことはある。 このような方向性で、以下の資料を勧める。
- mlr3 book (Bischl et al. (2024); https://mlr3book.mlr-org.com/) と、特に chapter on the handling of spatio-temporal data を参考。
- ハイパーパラメータチューニングに関する学術論文 (Schratz et al. 2019)
- mlr3spatiotempcv の使用方法に関する学術論文 (Schratz et al. 2021)
- 時空間データの場合、空間的と時間的の自己相関を考慮した上で CV を行う必要がある (Meyer et al. 2018)。
12.7 演習
E1. terra::rast(system.file("raster/ta.tif", package = "spDataLarge"))$elev で読み込んだ elev データセットから、R-GIS ブリッジ (GIS ソフトウェアへのブリッジの章を参照) を用いて以下の地形属性を計算しなさい。
- 傾斜角度
- 平面曲率
- プロファイル曲率
- 集水域
E2. slope、cplan、cprof、elev、log_carea という新しい変数を追加し、対応する出力ラスタから lsl データフレーム (data("lsl", package = "spDataLarge")) に値を抽出しなさい。
E3. 導き出された地形属性ラスタを GLM と組み合わせて、Figure 12.2に示すような空間予測マップを作成しなさい。
data("study_mask", "package="spDataLarge") を実行すると、調査地域のマスクが添付される。
E4. GLM 学習器に基づき、100 回繰り返した 5 フォールドの非空間交差検証と空間交差検証を計算し、箱ひげ図を用いて両方のリサンプリング戦略からの AUROC 値を比較しなさい。
ヒント: 非空間リサンプリング戦略を指定する必要がある。
追加ヒント: mlr3::benchmark() と mlr3::benchmark_grid() を使って、練習問題 4 から 6 を一度に解くことができます (詳しくは https://mlr3book.mlr-org.com/chapters/chapter10/advanced_technical_aspects_of_mlr3.html#sec-fallback を参照)。
その際、計算には非常に時間がかかり、おそらく数日かかることを覚悟しよう。
もちろん、これはシステムに依存する。
自由に使える RAM とコアが多ければ多いほど、計算時間は短くなる。
E5. 二次判別分析 (quadratic discriminant analysis, QDA) を用いて地すべり感受性をモデル化しなさい。 QDA の予測性能を評価しなさい。 QDA と GLM の空間交差検証平均 AUROC 値の差は?
E6. ハイパーパラメータを調整せずに SVM を実行しなさい。
rbfdot カーネルを \(sigma\) = 1 と C = 1 で使用しなさい。
kernlab の ksvm() でハイパーパラメータを指定しないままにしておくと、自動的に非空間的なハイパーパラメータチューニングが初期化しなさい。