14 商圏分析
必須パッケージ
- この章では、以下のパッケージが必要である (revgeo もインストールしておく必要がある)。
library(sf)
#> Warning: package 'sf' was built under R version 4.3.3
library(dplyr)
library(purrr)
library(terra)
#> Warning: package 'terra' was built under R version 4.3.3
library(osmdata)
library(spDataLarge)- 必要なデータは順次ダウンロードする
読者の利便性と再現性を確保するため、ダウンロードしたデータを spDataLarge パッケージで公開している。
14.1 イントロダクション
この章では、パート I とパート II で学んだスキルを特定のドメインに適用する方法を示す。商圏分析 (立地分析やロケーションインテリジェンスとも呼ばれることがある) である。 研究・実用化されている分野は幅広い。 その典型的な例として、どこに新しい店舗を置くかを考えよう。 ここでの目的は、最も多くの訪問者を集め、最終的に最も多くの利益を上げることである。 また、例えば新しい医療サービスをどこに配置するかなど、この技術を公共の利益のために利用できる非商業的なアプリケーションも多い (Tomintz, Clarke, and Rigby 2008)。
立地分析の基本は人である。 特に時間やその他のリソースを費やす可能性が高い場所である。 興味深いことに、エコロジーの概念やモデルは、店舗立地分析に使われるものと非常によく似ている。 動物や植物は、空間的に変化する変数に基づいて、特定の「最適な」場所でそのニーズを最もよく満たすことができる (Muenchow et al. (2018); Chapter 15 も参照)。 これはジオコンピュテーションや GIS サイエンス全般の大きな強みである。コンセプトや手法は他の分野にも転用可能である。 例えば、ホッキョクグマは気温が低く餌 (アザラシやアシカ) が豊富な北方を好む。 同様に、人間は特定の場所に集まる傾向があり、北極の生態学的ニッチに類似した経済的ニッチ (そして高い地価) を作り出す。 立地分析の主な作業は、利用可能なデータに基づいて、特定のサービスにとってそのような「最適な場所」がどこであるかを見つけ出すことである。 典型的なリサーチクエスチョンとしては、以下のようなものがある。
- ターゲット層はどこに住んでいて、どのエリアによく行くのか?
- 競合する店舗やサービスはどこにあるのか?
- 特定の店舗にどれくらいの人が行きやすいか?
- 既存のサービスは、市場の潜在力を過大に、あるいは過小に開拓していないか?
- ある企業の特定地域における市場シェアはどのくらいか?
本章では、ジオコンピュテーションが実データと仮想的なケーススタディに基づく疑問に答えることができることを示す。
14.2 ケーススタディ: ドイツの自転車店
ドイツで自転車店のチェーンを始めるとする。 店舗は、できるだけ多くの潜在顧客がいる都市部に配置したい。 さらに、仮定の調査 (この章のために考案されたもので、商業利用はできない!) によると、独身の若い男性 (20 歳から40 歳) が貴社の製品を購入する可能性が最も高いのでターゲット層である。 あなたは、何店舗も出店できる十分な資金を持っている幸運な立場にある。 しかし、どこに配置すればいいのだろうか? コンサルティング会社 (商圏分析アナリストを雇っている) は、このような質問に答えるために喜んで高い料金を取るだろう。 幸い、オープンデータやオープンソースソフトウェアの力を借りれば、私たち自身でそれを行うことができる。 以下の章では、本書の最初の章で学んだテクニックを、サービスロケーション解析の一般的なステップにどのように応用できるかを紹介する。
- ドイツの国勢調査の入力データを整理 (Section 14.3)
- 集計された国勢調査データをラスタオブジェクトに変換 (Section 14.4 )
- 人口密度の高い都市圏の特定 (Section 14.5 )
- これらの地域の詳細な地理データ (osmdata で OpenStreetMap) をダウンロード (Section 14.6)
- マップ代数を用いて異なる場所の相対的な望ましさをスコアリングするためのラスタを作成 (Section 14.4)
これらのステップは、特定のケーススタディに適用されたが、店舗立地や公共サービス提供の多くのシナリオに一般化することができる。
14.3 入力データを整頓
ドイツ政府は、1 km または 100 m の解像度でグリッド化された国勢調査データを提供している。 次のコードは、1 km のデータをダウンロードし、解凍し、読み込むものである。
download.file("https://tinyurl.com/ybtpkwxz",
destfile = "census.zip", mode = "wb")
unzip("census.zip") # unzip the files
census_de = readr::read_csv2(list.files(pattern = "Gitter.csv"))なお、census_de は spDataLarge パッケージ (data("census_de", package = "spDataLarge") からも入手可能である。
data("census_de", package = "spDataLarge")census_de オブジェクトは、ドイツ全土の 30 万以上のグリッドセルについて、13 の変数を含むデータフレームである。
これからの作業では、東経 (x) と北緯 (y)、住民数 (人口 pop)、平均年齢 (mean_age)、女性の割合 (women)、平均世帯人員 (hh_size) だけが必要である。
これらの変数を、以下のコードチャンクのように選択し、ドイツ語から英語に名前が変更する。その結果は Table 14.1 に要約した。
さらに mutate_all() で、値 -1 と -9 (不明を意味する) を NA に変換する。
# pop = population, hh_size = household size
input = select(census_de, x = x_mp_1km, y = y_mp_1km, pop = Einwohner,
women = Frauen_A, mean_age = Alter_D, hh_size = HHGroesse_D)
# 値 -1 と -9 を NA に設定
input_tidy = mutate(input, across(.cols = c(pop, women, mean_age, hh_size),
.fns = ~ifelse(.x %in% c(-1, -9), NA, .x)))| Class | 人口 | 女性割合 | 平均年齢 | 世帯サイズ |
|---|---|---|---|---|
| 1 | 3-250 | 0-40 | 0-40 | 1-2 |
| 2 | 250-500 | 40-47 | 40-42 | 2-2.5 |
| 3 | 500-2000 | 47-53 | 42-44 | 2.5-3 |
| 4 | 2000-4000 | 53-60 | 44-47 | 3-3.5 |
| 5 | 4000-8000 | >60 | >47 | >3.5 |
| 6 | >8000 |
14.4 国勢調査ラスタを作成
前処理を行った後、rast() 関数で SpatRaster に変換することができる (Section 2.3.4 と 3.3.1 を参照)。
type 引数を xyzとすると、入力データの x and y 列は通常グリッドの座標に対応する。
残りの列 (ここでは pop、women、mean_age、hh_size) は、ラスタレイヤの値として使うことができる (Figure 14.1; GitHub リポジトリの code/14-location-figures.R も参照)。
input_ras = rast(input_tidy, type = "xyz", crs = "EPSG:3035")
input_ras
#> class : SpatRaster
#> dimensions : 868, 642, 4 (nrow, ncol, nlyr)
#> resolution : 1000, 1000 (x, y)
#> extent : 4031000, 4673000, 2684000, 3552000 (xmin, xmax, ymin, ymax)
#> coord. ref. : ETRS89-extended / LAEA Europe (EPSG:3035)
#> source(s) : memory
#> names : pop, women, mean_age, hh_size
#> min values : 1, 1, 1, 1
#> max values : 6, 5, 5, 5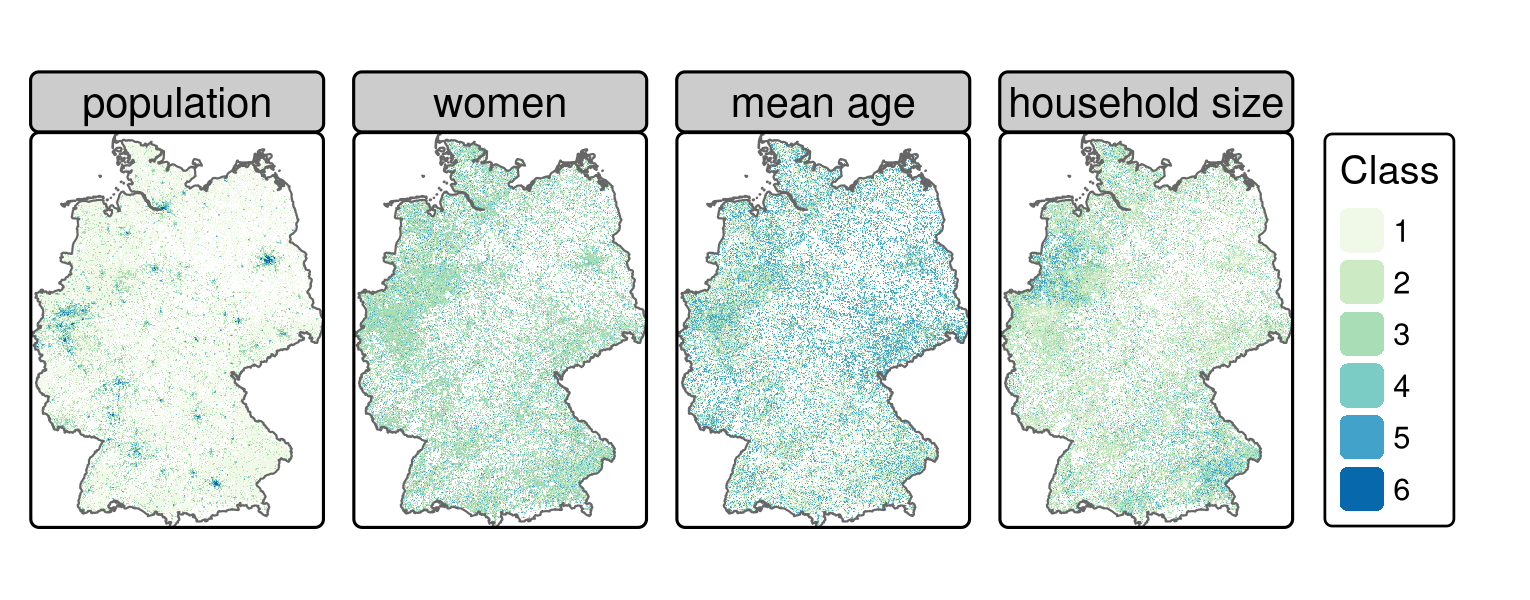
FIGURE 14.1: グリッド化した2011年ドイツ国勢調査 (クラスの内容は Table 14.1)。
次に、input_ras に格納されているラスタの値を、Section 14.2 で述べた調査に従って、Section 4.3.3 で紹介した raster 関数 reclassify() を用いて再分類している。
母集団データの場合、クラスの平均値を用いて数値データ型に変換する。
ラスタセルは、値 1 (「クラス 1」のセルが 3~250 人の住民を含む) の場合は 127 人、値 2 (250~500人の住民を含む) の場合は 375 人と仮定される (Table 14.1 を参照)。
これらのセルには 8,000 人以上の人が含まれているため、「クラス 6」のセル値には 8,000 人の住民が選ばれた。
もちろん、これは真の母集団の近似値であり、正確な値ではない。97
しかし、大都市圏を定義するには十分なレベルである (Section 14.5 参照)。
総人口の絶対推計を表す変数 pop とは対照的に、残りの変数は、調査で使用されたウェイトに対応するウェイトに分類し直した。
例えば、変数 women のクラス 1 は、人口の 0~40% が女性である地域を表す。
は、ターゲット層が男性であるため、比較的高いウェイトである 3 に分類し直した。
同様に、若年層や単身世帯の割合が高い層は、高いウェイトを持つように分類し直した。
rcl_pop = matrix(c(1, 1, 127, 2, 2, 375, 3, 3, 1250,
4, 4, 3000, 5, 5, 6000, 6, 6, 8000),
ncol = 3, byrow = TRUE)
rcl_women = matrix(c(1, 1, 3, 2, 2, 2, 3, 3, 1, 4, 5, 0),
ncol = 3, byrow = TRUE)
rcl_age = matrix(c(1, 1, 3, 2, 2, 0, 3, 5, 0),
ncol = 3, byrow = TRUE)
rcl_hh = rcl_women
rcl = list(rcl_pop, rcl_women, rcl_age, rcl_hh)なお、リスト中の再分類行列の順序は、input_ras の要素と同じになるようにした。
例えば、最初の要素はどちらの場合も母集団に対応する。
その後、for-loop、再分類行列を対応するラスタレイヤに適用する。
最後に、以下のコードで、reclass のレイヤが input_ras のレイヤと同じ名前であることを確認する。
reclass = input_ras
for (i in seq_len(nlyr(reclass))) {
reclass[[i]] = classify(x = reclass[[i]], rcl = rcl[[i]], right = NA)
}
names(reclass) = names(input_ras)
reclass # 出力は一部省略
#> ...
#> names : pop, women, mean_age, hh_size
#> min values : 127, 0, 0, 0
#> max values : 8000, 3, 3, 314.5 大都市圏を定義
大都市圏とは、50 万人以上が住む 20 km2 のピクセルと定義している。
この粗い解像度のピクセルは、Section 5.3.3 で紹介したように、aggregate()、速やかに作成することができる。
以下のコマンドは、引数 fact = 20、結果の解像度を 20 倍にしている (元のラスタの解像度が 1 km2 であったことを思い出そう)。
pop_agg = aggregate(reclass$pop, fact = 20, fun = sum, na.rm = TRUE)
summary(pop_agg)
#> pop
#> Min. : 127
#> 1st Qu.: 39886
#> Median : 66008
#> Mean : 99503
#> 3rd Qu.: 105696
#> Max. :1204870
#> NA's :447次のステージでは、50 万人以上のセルだけを残す。
pop_agg = pop_agg[pop_agg > 500000, drop = FALSE] これをプロットすると、8 つの大都市圏 (Figure 14.2) が見えてくる。
各領域は、1 つ以上のラスタセルで構成される。
1 つの地域に属するすべてのセルを結合できればコマンドは、
terra の patches() である。
その後、as.polygons() でラスタオブジェクトを空間ポリゴンに変換し、st_as_sf() で sf. オブジェクトに変換する。
metros = pop_agg |>
patches(directions = 8) |>
as.polygons() |>
st_as_sf()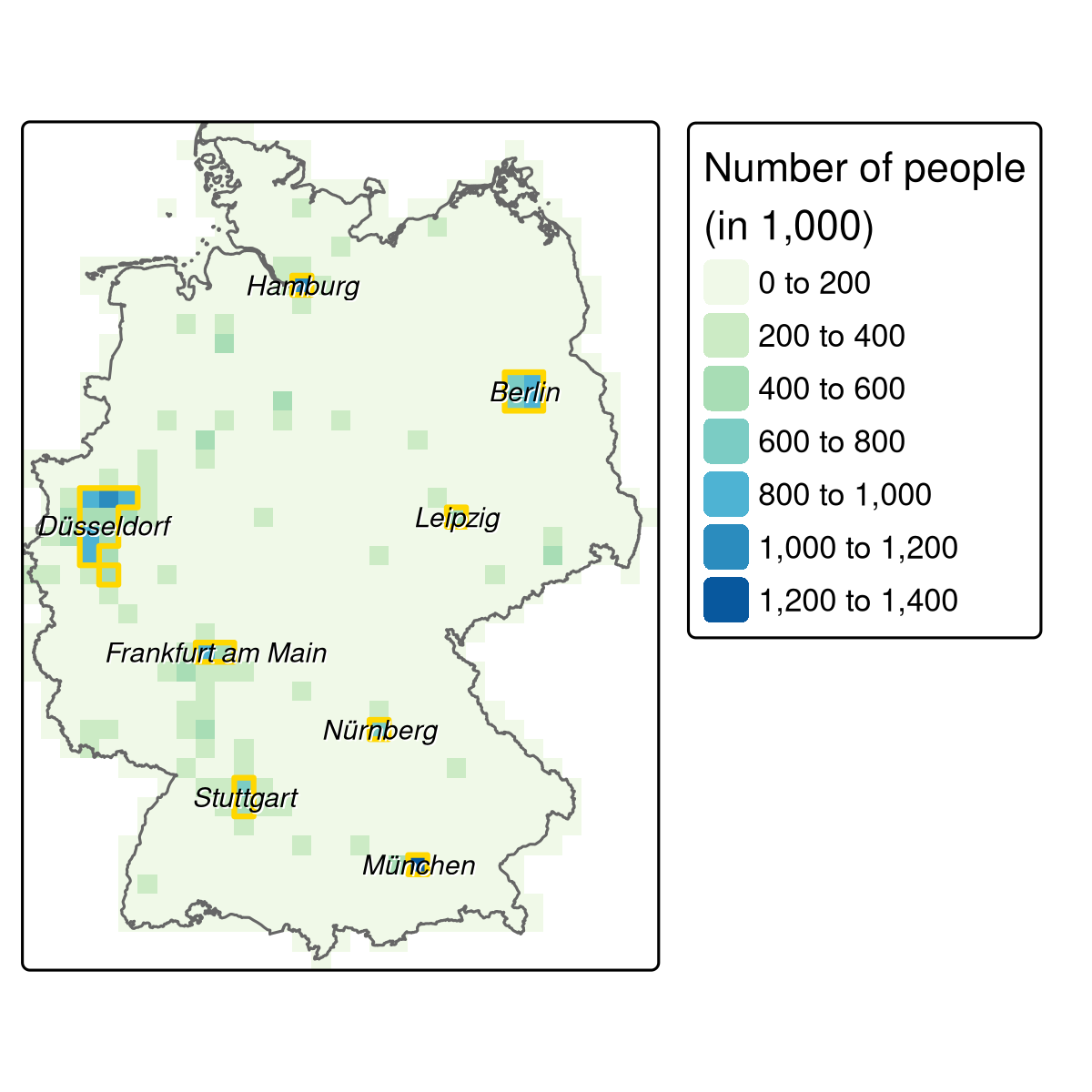
FIGURE 14.2: 人口ラスタ (分解能20km)、大都市圏 (金色のポリゴン) とその名称。
自転車店に適した 8 つの都市圏 (Figure 14.2; 図の作成については code/14-location-jm.R も参照) が得られたが、まだ名前が分からない。
逆ジオコーディングというアプローチでこの問題を解決することができ、対応する住所が得られる。
各都市圏の重心座標を抽出することで、逆ジオコーディング API の入力とすることができる。
これは、tmaptools パッケージの rev_geocode_OSM() 関数が期待するものとまったく同じである。
さらに as.data.frame を TRUE に設定すると、通りの名前、家の番号、都市名など、場所を示すいくつかの列を持つ data.frame が返される。
しかし、ここでは都市の名前にのみ関心がある。
metro_names = sf::st_centroid(metros, of_largest_polygon = TRUE) |>
tmaptools::rev_geocode_OSM(as.data.frame = TRUE) |>
select(city, town, state)
# 小さい都市は town の列で返される。すべての名前を1つの列にするため、
# NA である場合に備えて、町の名前を市の列に移動させる。
metro_names = dplyr::mutate(metro_names, city = ifelse(is.na(city), town, city))読者が全く同じ結果を使用できるようにするため、metro_names オブジェクトとして spDataLarge に入れている。
| City | State |
|---|---|
| Hamburg | NA |
| Berlin | NA |
| Velbert | Nordrhein-Westfalen |
| Leipzig | Sachsen |
| Frankfurt am Main | Hessen |
| Nürnberg | Bayern |
| Stuttgart | Baden-Württemberg |
| München | Bayern |
全体として、私たちは City 列が大都市名 (Table 14.2) として機能していることに満足している。例外は、Wülfrath が Düsseldorf の大領域に属していることで ある。
したがって、Wülfrath を Düsseldorf (Figure 14.2) に置き換える。
ウムラウト ü は、例えば opq() を使って大都市圏のバウンディングボックスを決定する場合 (後述)、後々トラブルになる可能性があるため、これも変換しておく。
metro_names = metro_names$city |>
as.character() |>
(\(x) ifelse(x == "Velbert", "Düsseldorf", x))() |>
gsub("ü", "ue", x = _)14.6 地理的目標物
osmdata パッケージは、OSM データへの使いやすいアクセスを提供する (Section 8.5 も参照)。 ドイツ全土の店舗をダウンロードするのではなく、定義された大都市圏にクエリを限定することで、計算負荷を軽減し、関心のあるエリアのみの店舗位置を提供している。 この後のコードチャンクは、以下のようないくつかの関数を用いてこれを行う。
-
map(): (lapply()の tidyverse 相当)。これは、OSM クエリ関数opq()(Section 8.5 参照) のバウンディングボックスを定義する、8 つの大都市名すべてを繰り返し処理 -
add_osm_feature(): キー値がshopの OSM 要素を指定する (共通のキー:値のペアの一覧は wiki.openstreetmap.org を参照) -
osmdata_sf(): これは OSM データを空間オブジェクト (クラスsf) に変換 -
while(): ダウンロードに失敗すると、さらに 2 回ダウンロードを試みる98
このコードを実行する前に: 約 2 GB のデータをダウンロードすることを考慮してみよう。
時間とリソースを節約するために、shops という名前の出力を spDataLarge に入れてある。
自分の環境で利用できるようにするには、spDataLarge パッケージがロードされていることを確認するか、data("shops", package = "spDataLarge") を実行してみよう。
shops = purrr::map(metro_names, function(x) {
message("Downloading shops of: ", x, "\n")
# サーバに時間を与える
Sys.sleep(sample(seq(5, 10, 0.1), 1))
query = osmdata::opq(x) |>
osmdata::add_osm_feature(key = "shop")
points = osmdata::osmdata_sf(query)
# ダウンロードしなかった場合、同じデータをリクエスト
iter = 2
while (nrow(points$osm_points) == 0 && iter > 0) {
points = osmdata_sf(query)
iter = iter - 1
}
# 点フィーチャのみ返す
points$osm_points
})定義された大都市圏に店舗がないことはまずありえない。
次の if の条件は、各地域に少なくとも 1 つの店舗があるかどうかをチェックするだけである。
その場合は、該当する地域の店舗を再度ダウンロードすることを勧める。
# 各都道府県のダウンロードショップがあるかどうかの確認
ind = map(shops, nrow) == 0
if (any(ind)) {
message("There are/is still (a) metropolitan area/s without any features:\n",
paste(metro_names[ind], collapse = ", "), "\nPlease fix it!")
}各リストの要素 (sf データフレーム) が同じ列を持っていることを確認するために99 osm_id と shop 列だけを残し、さらに map_dfr ループを使って全ての店舗を一つの大きな sf オブジェクトに統合する。
# 特定の列のみを選択
shops = purrr::map_dfr(shops, select, osm_id, shop)注: shops は、以下のように spDataLarge パッケージから取得する。
data("shops", package = "spDataLarge")最後に、空間点オブジェクトをラスタに変換する (Section 6.4 参照)。
sf オブジェクト shops は、reclass オブジェクトと同じパラメータ (寸法、解像度、CRS) を持つラスタに変換される。
重要なのは、ここで length() 関数を用いて、各セルのショップ数を算出していることである。
そのため、後続のコードチャンクの結果は、店舗密度 (店舗/km2) の推定値となる。
st_transform() は、両入力の CRS が一致するように、rasterize() の前に使用される。
shops = sf::st_transform(shops, st_crs(reclass))
# POI ラスタを作成
poi = terra::rasterize(x = shops, y = reclass, field = "osm_id", fun = "length")他のラスタレイヤ (人口、女性、平均年齢、世帯人員) と同様、poi ラスタは 4 つのクラスに再分類される (Section 14.4 参照)。
クラス間隔の定義は、ある程度恣意的に行われる。
均等割、分位割、固定値などを使用することができる。
ここでは、クラス内分散を最小化する Fisher-Jenks 自然分類法を選択し、その結果を再分類行列の入力とする。
# 再分類化行列を作成
int = classInt::classIntervals(values(poi), n = 4, style = "fisher")
int = round(int$brks)
rcl_poi = matrix(c(int[1], rep(int[-c(1, length(int))], each = 2),
int[length(int)] + 1), ncol = 2, byrow = TRUE)
rcl_poi = cbind(rcl_poi, 0:3)
# 再分類
poi = classify(poi, rcl = rcl_poi, right = NA)
names(poi) = "poi"14.7 適当な場所を特定
すべてのレイヤを結合する前に残っている唯一のステップは、poi を reclass のラスタスタックに追加し、そこから人口レイヤを削除することである。
後者の理由は 2 つある。
まず、大都市圏、つまりドイツの他の地域に比べて人口密度が平均的に高い地域はすでに定義されている。
第二に、特定のキャッチメントエリア内に多くの潜在顧客がいることは有利であるが、数が多いだけでは、実際には望ましいターゲットグループを表していない可能性がある。
例えば、高層マンションは人口密度が高い地域であるが、高価なサイクル部品の購買力が高いとは限らない。
他のデータサイエンス・プロジェクトと同様、これまでのところ、データの検索と「整理」が全体の作業負荷の多くを占めている。 きれいなデータであれば、最後のステップであるすべてのラスタのレイヤを合計して最終的なスコアを計算することも、1行のコードで実現できる。
# 合計点を計算
result = sum(reclass)例えば、9 以上のスコアは、自転車ショップを配置できるラスタセルを示す適切な閾値かもしれない (Figure 14.3 ; code/14-location-jm.R も参照)。
FIGURE 14.3: ベルリンにおける自転車店の仮想調査に従った適切なエリア (スコア> 9のラスタセル)。
14.8 ディスカッションと次のステップ
今回紹介したアプローチは、GIS の規範的な使い方の典型的な例である (Longley 2015)。 調査データと専門家による知識・仮定 (大都市圏の定義、クラス間隔の定義、最終的なスコア閾値の定義) を組み合わせている。 このアプローチは、科学的な研究よりも、他の情報源と比較すべき、自転車店に適した地域のエビデンスに基づく指標を提供する応用分析に適している。 アプローチにいくつかの変更を加えることで、分析結果を改善することができる。
- 最終的なスコアの算出には均等なウェイトを用いたが、世帯規模など他の要因も、女性の割合や平均年齢と同様に重要である可能性がある。
- 全ての地理的目標物 を使用したが、DIY、ハードウェア、自転車、釣り、ハンティング、バイク、アウトドア、スポーツショップなど、自転車販売店に関連するもののみ (ショップ値の範囲は OSM Wiki で確認可能)にすると、より洗練された結果を得ることができたかもしれない
- 解像度の高いデータを使うと、出力が向上する場合がある (演習参照)
- 限られた変数のみを使用し、INSPIRE geoportal や OpenStreetMap のサイクリングロードのデータなど、他の情報源からのデータは分析を豊かにするかもしれない (Section 8.5 も参照のこと)。
- 男性比率と単身世帯の関係などの相互作用は考慮されていない。
つまり、この分析は多方面に拡張することができる。 商圏分析の文脈の中で、R で空間データを取得し、扱う方法について、第一印象と理解を深めていただけたと思われる。
最後に、今回の分析は、あくまでも適地探しの第一歩に過ぎないということを指摘しておく必要がある。 これまでの調査により、1 km 四方で自転車販売店の立地が可能なエリアを特定した。 その後の分析のステップを踏むことができる。
- 特定のキャッチメントエリア内の住民の数に基づいて最適な場所を見つける。 例えば、できるだけ多くの人が自転車で15分以内の移動距離で行けるお店であること (キャッチメントエリアルート検索)。 そのため、店舗から遠ければ遠いほど、実際に店舗を訪れる可能性が低くなることを考慮する必要がある (距離減衰関数)。
- また、競合他社を考慮するのも良いアイデアだろう。 つまり、選択した場所の近辺にすでに自転車屋がある場合、可能性のある顧客 (または販売可能性) を競合他社に分散させる必要がある (Huff 1963; Wieland 2017)。
- 例えば、アクセスの良さ、駐車場の有無、通行人の希望頻度、大きな窓があることなど、適切かつ手頃な価格の不動産を探す必要がある。
14.9 演習
E1. 100 m セル解像度の住民情報を含む csv ファイルをダウンロードしなさい (https://www.zensus2011.de/SharedDocs/Downloads/DE/Pressemitteilung/DemografischeGrunddaten/csv_Bevoelkerung_100m_Gitter.zip?__blob=publicationFile&v=3)。
解凍したファイルのサイズは 1.23 GB である。
このファイルを R に読み込むには、readr::read_csvを使うことができる。
16 GB の RAM を搭載したパソコンで 30 秒かかる。
data.table::fread() はさらに速く、data.table() クラスのオブジェクトを返す。
dplyr::as_tibble() を使用して、それを tibble に変換しなさい。
住民ラスタを作成し、セル解像度 1 km に集約し、クラスの平均値を用いて作成した住民ラスタ (inh) との差を比較しなさい。
E2. 仮に、自転車店が主に高齢者に電動自転車を販売していたとしよう。 それに応じて年齢ラスタを変更し、残りの分析を繰り返し、その変化を元の結果と比較しなさい。