13 交通解析
必須パッケージ
- この章では、以下のパッケージを使用する89
13.1 イントロダクション
交通ほど地理的空間が明確な分野も少ないだろう。 1970年に Waldo Tobler が述べたように、移動の努力 (距離の克服) は、地理学の「第一法則」の中心である (Waldo R. Tobler 1970)。
Everything is related to everything else, but near things are more related than distant things.
この「法則」は、空間自己相関など、地理学の重要な概念の基礎となるものである。 それは、友情のネットワークや生態系の多様性といった多様な現象に適用され、「距離の摩擦」を構成する時間、エネルギー、金銭といった交通コストによって説明することができる。 この観点からすると、交通テクノロジーは破壊的であり、移動する人間やモノを含む地理的な実体間の関係を変化させる。「交通の目的は空間を克服することである」 (Rodrigue, Comtois, and Slack 2013)。
交通とは、本質的に空間的な活動であり、出発点「A」から目的点「B」に移動し、その間にある無限の地域を通過することである。 したがって、交通研究者は、移動パターンを理解し、介入によってそのパフォーマンスをどのように改善できるかを理解するため、昔から地理的・計算的手法に注目してきた (Lovelace 2021)。
本章では、交通システムの地理的分析について、さまざまな地理的レベルで紹介する。
- エリア単位: 交通パターンは、主な移動手段 (車、自転車、徒歩など) や、特定のゾーンに住む人々の平均移動距離など、ゾーンごとの集計を参照して理解することができる (Section 13.3 で解説する)。
- 希望線 (desire line): 地理空間における場所 (点またはゾーン) 間を何人が移動したか (または移動できたか) を記録した「起点-終点」データを表す直線で、Section 13.4 の話題である。
- ノード : ノードとは、共通の起点と終点を表すことができる交通システムの点であり、バス停や鉄道駅などの公共交通機関の駅、Section 13.5 のトピックである。
- ルート: 希望線に沿ったルート網とノード間のルートを表す線である。 ルート (1 つの線または複数のセグメントの場合がある) と、ルートを生成するルートエンジンは、Section 13.6 で詳しく述べる。
- ルートネットワーク (network): これらは、ある地域の道路、小道、その他の線形特徴のシステムを表し、Section 13.7 で取り上げている。 これらは地理的な特徴 (短いセグメントでネットワーク全体を作り上げる) として表現することもできるし、相互接続されたグラフとして構造化することもできる。異なるセグメント上の交通のレベルは、交通モデルでは「フロー」と呼ばれる (Hollander 2016)。
もうひとつの重要なレベルは、私やあなたのような移動する存在を表すエージェントである。 エージェントは、 MATSim のようなソフトウェアのおかげで、計算によって表現することができる。これは、エージェントベースモデリング (agent-based modelling, ABM)のアプローチを用いて、高い空間および時間分解能で交通システムのダイナミクスを捉えるものである (Horni, Nagel, and Axhausen 2016)。 ABM は、R の空間クラスと統合できる可能性が高い交通研究の強力なアプローチであるが (Thiele 2014; Lovelace and Dumont 2016)、本章の範囲外である。 地理的レベルやエージェントの次に来るのは、ほとんどの交通モデルの分析の基本単位であるトリップであり、出発地「A」から目的地「B」までの単一目的の旅である (Hollander 2016)。 トリップは、異なるレベルの交通システムを結合し、単純化すると、ゾーンの重心 (ノード) を結ぶ地理的な希望線として、あるいは交通ルートネットワークに沿った経路として表現することができる。 この文脈では、エージェントは通常、交通ネットワーク内を移動する点である。
交通システムは動的である (Xie and Levinson 2011)。 この章では、交通システムの地理的な分析に焦点を当てるが、変化のシナリオをシミュレートするために、この手法をどのように利用できるかについて、Section 13.8 にて詳しくみていこう。 地理学上の交通モデルの目的は、このような時空間システムの複雑さを、その本質を捉える形で単純化することにあると解釈できる。 適切なレベルの地理的分析を選択することで、最も重要な特徴や変数を失うことなく、この複雑さを単純化し、より良い意思決定とより効果的な介入を可能にすることができる (Hollander 2016)。
一般的に、モデルは特定の問題を解決するために設計される。 そのため、本章では、次章で紹介する政策シナリオを軸に、Bristol 市内で自転車を増やす方法は何があるかを問う。 Chapter 14 では、ジオコンピュテーションの応用として、新しい自転車店の立地の優先順位付けを行う。 新しい自転車利用・インフラが効果的に配置されると、人々が自転車利用するようになり、自転車利用・ショップの需要や地域の経済活動を高めることができる。 これは、交通システムの重要な特徴を強調している。交通システムは、より広範な現象や土地利用パターンと密接に関連している。
13.2 Bristol のケーススタディ
本章で使用する事例は、England 西部の都市 Bristol で、Wales の首都 Cardiff から東に 30 km ほど離れた場所にある。 この地域の交通網の概要は、Figure 13.1 に示されており、自転車、公共交通、自家用車のための多様な交通インフラが示されている。
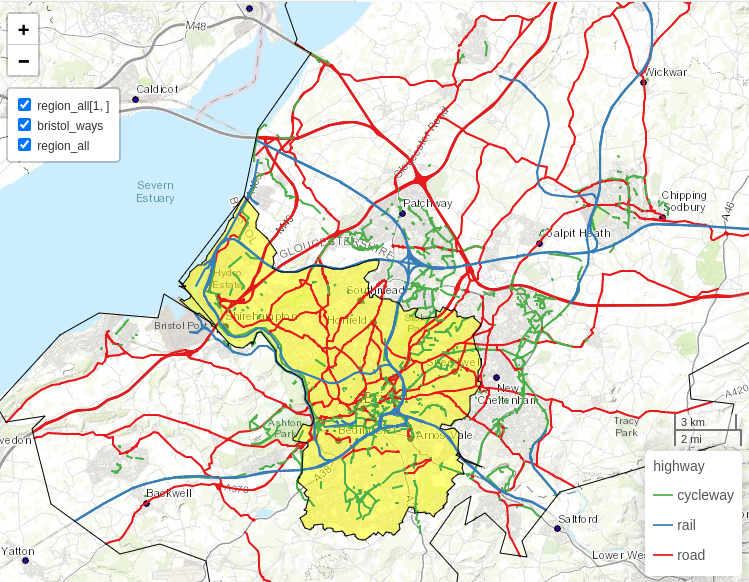
FIGURE 13.1: Bristol の交通網は、アクティブ (緑)、公共 (鉄道、青)、自家用車 (赤) の各移動手段を色分けして表現している。黒い境界線は、市街地の境界線 (黄色でハイライト) と、より広い TTWA (Travel To Work Area) を表している。
Bristol は England で 10 番目に大きい市で、人口は 50 万人であるが、そのトラベルキャッチメントエリアはもっと大きい (Section 13.3 参照)。 市内には航空宇宙、メディア、金融サービス、観光などの企業が集まり、2 つの主要な大学とともに、活気ある経済が展開されている。 Bristol は一人当たりの平均所得が高いが、深刻な貧困地域も含まれている (Bristol City Council 2015)。
交通の面では、Bristol は鉄道や道路の便がよく、アクティブトラベル (訳註: 「アクティブトラベル」とは自転車または徒歩による交通のこと) のレベルも比較的高い。 Active People Survey によると、国民の 19% が月に 1 回以上自転車を利用し、88% が歩いている (全国平均はそれぞれ 15%、81%)。 2011年の国勢調査では、自転車で通勤していると答えた人は全体の 8% だったのに対し、全国ではわずか 3% にとどまっている。
多くの都市と同様に Bristol も渋滞、大気質、運動不足などの大きな問題を抱えている。 自転車は、これらの問題すべてに効率的に取り組むことができる。典型的な速度は、徒歩の時速 4〜6 km に対して時速 15〜20 km と、徒歩よりも自動車による移動を置き換える可能性が大きい。 このため、Bristol の交通戦略では、自転車利用について野心的な計画を立てている。
この章では、交通研究における政策的配慮の重要性を強調するため、人々を車から解放し、より持続可能な手段、特に徒歩と自転車に乗せることを任務とする人々 (交通プランナー、政治家、その他の利害関係者) にエビデンスを提供する目的で書かれている。 より広い目的として、ジオコンピュテーションがどのように証拠に基づく交通計画をサポートできるかを示すことである。 この章では、次のことを学ぶ。
- 都市における交通行動の地理的パターンを説明する
- マルチモード・トリップをサポートする主要な公共交通機関のノードを特定する。
- 移動の「希望線」を分析、多くの人が短距離をドライブする場所を見つける
- 自動車を減らし自転車を増やすような自転車ルートの位置を特定する
本章の実用的な面から始めるため、次節で、移動パターンに関するゾーンデータをロードする。 このようなゾーンレベルのデータは少ないが、地域の交通システム全体を基本的に理解するためには不可欠な場合が多い。
13.3 交通ゾーン
交通システムは主に線形のフィーチャやノード (例えば、ルートや駅) に基づいているが、連続した空間を具体的な単位に分割するために、面的なデータから始めることがしばしば意味を持つ (Hollander 2016)。 調査地域 (ここでは Bristol) を定義する境界線に加えて、交通研究者にとって特に関心の高い 2 つのゾーンタイプ、すなわち発着地ゾーンがある。 多くの場合、発着地には同じ地理的単位が使用される。 しかし、学校や商店などの「トリップアトラクター」が多い地域では、「 Workplace Zones」のような異なるゾーニングシステムが、トリップ先の密度上昇を表すのに適切だろう (Office for National Statistics 2014)。
調査地域を定義する最も簡単な方法は、OpenStreetMap が返す最初のマッチング境界であることが多い。
これは osmdata を使用して bristol_region = osmdata::getbb("Bristol", format_out = "sf_polygon") のようなコマンドで取得することができる。
この結果、最大の一致する都市地域の境界を表す sf オブジェクトが得られ、バウンディングボックスの長方形ポリゴンまたは詳細なポリゴン境界のいずれかが得られる。90
イギリスの Bristol については、spDataLarge パッケージにある Bristol の公式な境界を表す詳細なポリゴンが返される。
Figure 13.1 の内側の青い境界を参照。なお、この方法にはいくつかの問題点がある。
- OSM から最初に返された境界は、自治体が使用する正式な境界とは異なる場合がある
- OSM が正式な境界線を返したとしても、人々が移動する場所とはほとんど関係がないため、交通研究にとっては不適切かもしれない。
Travel To Work Area (TTWA)) は、水文学的における流域のようなゾーニングシステムを構築することで、これらの問題に対処している。
TTWA はまず、人口の75%が通勤で利用する連続したゾーンと定義されており (Coombes, Green, and Openshaw 1986)、この章ではこの定義を用いる。
Bristol は、周辺の町からのトラベル者を惹きつける主要な雇用主であるため、その TTWA は市域よりもかなり大きい (Figure 13.1 参照)。
この交通方向の境界を表すポリゴンは、本章の冒頭でロードした spDataLarge パッケージが提供するオブジェクト bristol_ttwa に格納されている。
本章で使用する出発地と目的地は同じである。中間の地理的解像度で公式に定義されたゾーン (公式名称は Middle layer Super Output Areas MSOA) である。 それぞれ約 8,000 人が暮らしている。 このような行政区域は、特定の介入から最も恩恵を受ける可能性のある人々のタイプなど、交通分析に不可欠な状況を提供することができる (例 Moreno-Monroy, Lovelace, and Ramos (2017))。
ゾーンの地理的解像度は重要である。通常、地理的解像度の高い小さなゾーンが望ましいが、大きな地域で数が多いと、処理に影響を及ぼすことがある。 特に、起点-終点 (OD) 分析は、 ゾーン数に応じて非線形に可能性の数が増加する (Hollander 2016)。
ゾーンが小規模の場合、匿名性のルールに関連する問題も発生する。 ゾーン内の個人の特定を推測できないようにするため、詳細な社会人口統計変数は、低い地理的解像度でしか利用できない。 例えばイギリスでは、年齢や性別による移動手段の内訳は、自治体レベルでは利用できるが 100 世帯程度で構成される出力エリアレベルでは利用できない。 詳細は、www.ons.gov.uk/methodology/geography を参照。
本章で使用する 102 のゾーンは、Figure 13.2 に図示されているように bristol_zones に格納されている。
人口が密集しているところでは、ゾーンが小さくなっていることに注意しておこう。
bristol_zones は、交通に関する属性データは含まず、各ゾーンの名称とコードのみである。
names(bristol_zones)
#> [1] "geo_code" "name" "geometry"トラベルデータを追加するために、Section 3.2.4 で説明されている一般的なタスクである属性結合を実行する。
ここでは、ons.gov.uk データポータルで提供されている、英国の2011年国勢調査の出勤時間に関するトラベルデータ bristol_od を使用する。
bristol_od は、英国の2011年国勢調査によるゾーン間の通勤に関する起点 (Origin)ー終点 (Desitination) (OD) データセットである (Section 13.4 参照)。
Section 13.4 1 列目は出発地のゾーン ID、2 列目は目的地のゾーンである。
bristol_od は、bristol_zones よりも多くの行を持ち、ゾーンそのものよりもゾーン間の移動を表している。
先ほどのコードチャンクの結果、各ゾーンに 10 組以上の OD ペアがあることがわかった。つまり、下図のように、bristol_zones に結合する前に発着地データを集約する必要がある (発着地データは Section 13.4 に記述されている)。
zones_attr = bristol_od %>%
group_by(o) %>%
summarize_if(is.numeric, sum) %>%
dplyr::rename(geo_code = o)上記のチャンクは、
- 原産地別にデータをグループ化した (
oの列に含まれる) -
bristol_odデータセットの変数が数値であれば、それを集計して、各ゾーンに住む人の交通手段別の総数を求める91 - グループ化変数
oの名前を変更し、bristol_zonesオブジェクトの ID 列geo_codeと一致するようにした
結果として得られるオブジェクト zones_attr は、ゾーンを表す行と ID 変数を持つデータフレームである。
ID が zones データセットのものと一致するかどうかは、%in% 演算子を用いて以下のように確認することができる。
その結果、新しいオブジェクトには 102 のゾーンがすべて存在し、zone_attr、ゾーン上に結合できる形になっていることがわかった。92
これは、結合関数 left_join() を使って行われる (なお、inner_join() でも同じ結果になる)。
zones_joined = left_join(bristol_zones, zones_attr, by = "geo_code")
sum(zones_joined$all)
#> [1] 238805
names(zones_joined)
#> [1] "geo_code" "name" "all" "bicycle" "foot"
#> [6] "car_driver" "train" "geometry"結果は、調査地域の各ゾーンを起点とするトリップの総数 (ほぼ 25 万) とその移動手段 (自転車、徒歩、自動車、電車) を表す列が新たに追加されている zones_joined である。
トリップの起点の地理的な分布は、左パネル (Figure 13.2) に示されている。
このことから、ほとんどのゾーンは、調査エリア内で 0〜4,000 のトリップを発生させていることがわかる。
Bristol の中心部付近に住む人の移動が増え、郊外に住む人の移動が減っている。
これはなぜだろうか。調査地域内のトリップだけを扱っていることを思い出そう。
周辺ゾーンのトリップ数が少ないのは、周辺ゾーンにいる人の多くが、調査地域外の他の地域へ移動するためであると考えられる。
調査地域外のトリップは、モデルで表現されていないゾーンに行くトリップをカバーする特別な目的地IDによって、地域モデルに含めることができる (Hollander 2016)。
しかし、bristol_od のデータは、このようなトリップを無視している。「ゾーン内」モデルということである。
OD データセットが出発地のゾーンに集約されるのと同じように、目的地のゾーンに関する情報を提供するために集約することもできる。
人は、中心部に引き寄せられるように集まる傾向がある。
このことは、右図 (Figure 13.2) で表される空間分布が比較的不均一であり、最も多い目的地ゾーンが Bristol 市の中心部に集中していることを説明している。
その結果、任意のモードによるトラベル先数を報告する新しい列を含む、zones_od が以下のように作成される。
zones_destinations = bristol_od |>
group_by(d) |>
summarize(across(where(is.numeric), sum)) |>
select(geo_code = d, all_dest = all)
zones_od = inner_join(zones_joined, zones_destinations, by = "geo_code")Figure 13.2 の簡易版は、以下のコードで作成する (図を再現するには、本書の GitHub リポジトリの code フォルダ の 13-zones.R を参照。tmap によるファセット地図の詳細は Section 9.2.7 を参照)。
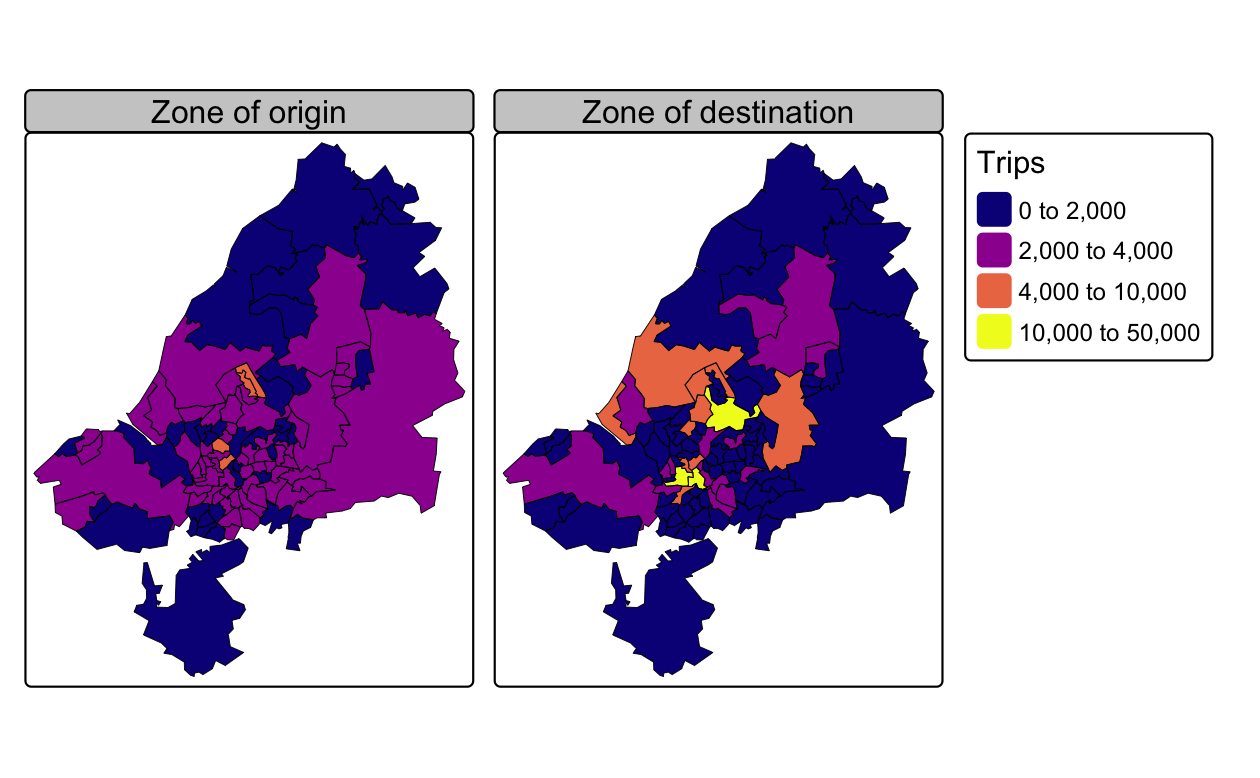
FIGURE 13.2: 地域内に居住・勤務するトリップ (通勤者) 数。左の地図は通勤トリップの出発地、右の地図は目的地のゾーン (13-zones.R スクリプトで生成)。
13.4 希望線
希望線 (desire line) は、出発地と目的地をつなぎ、人々がゾーン間で行きたいと望む場所を表している。 これは、建物や風の強い道路などの障害物がなければ、A-B 間を最も早く移動できる「蜂の飛行線」または「カラスの飛行線」ルートを表している (希望線をルートに変換する方法については、次のセクションで説明する)。 一般的に、希望線は各ゾーンの地理的 (または人口加重) 重心を始点および終点として地理的に表現される。 このセクションでは、このタイプの希望線を作成して使用するが、OD データを基にした分析の空間的なカバレッジと精度を高めるために、複数の開始点と終了点を可能にする「ジッタリング」技術は知っておく価値がある (Lovelace, Félix, and Carlino 2022)。
データセット bristol_od に、希望線を表すデータをすでに読み込んでいる。
この起点ー終点 (OD) データフレームオブジェクトは、o で表されるゾーンと d、Table 13.1 で示されるゾーン間の移動人数を表している。
OD データをすべてのトリップで並べ、上位5つだけをフィルタリングするには、次のように入力する (非空間属性操作の詳細については、Chapter 3 を参照)。
od_top5 = bristol_od |>
slice_max(all, n = 5)| o | d | all | bicycle | foot | car_driver | train |
|---|---|---|---|---|---|---|
| E02003043 | E02003043 | 1493 | 66 | 1296 | 64 | 8 |
| E02003047 | E02003043 | 1300 | 287 | 751 | 148 | 8 |
| E02003031 | E02003043 | 1221 | 305 | 600 | 176 | 7 |
| E02003037 | E02003043 | 1186 | 88 | 908 | 110 | 3 |
| E02003034 | E02003043 | 1177 | 281 | 711 | 100 | 7 |
この表は、Bristol での通勤・通学パターンを示すものである。
これは、上位 5 つの OD ペアにおいて、徒歩が最も人気のある交通手段であること、ゾーン E02003043 が人気のある目的地であること (Bristol の中心部、上位 5 つの OD ペアの目的地)、ゾーン E02003043 のある部分から別の部分へのゾーン内トリップ (Table 13.1 の最初の行) がデータセットで最も移動した OD ペアであることを実証している。
しかし、政策的な観点から見ると、Table 13.1 で示される生データは、限られた用途にしか使えない。2,910 組の OD のうち、ごく一部しか含まれていないという事実を除けば、政策的措置が必要な場所はどこか、徒歩や自転車による移動がどの程度の割合を占めるのかについては、ほとんどわからないのである。
次のコマンドは、これらのアクティブモードによって作られる各希望線の割合を計算する。
bristol_od$Active = (bristol_od$bicycle + bristol_od$foot) /
bristol_od$all * 100OD ペアは、大きく分けてゾーン間とゾーン内の 2 種類がある。
ゾーン間 OD ペアは、目的地と出発地が異なるゾーン間の移動を表する。
ゾーン内 OD ペアは、同一ゾーン内の移動を表す (Table 13.1 の上段参照)。
以下のコードチャンクでは、od_bristol をこの2種類に分割している。
次のステップは、ゾーン間 OD ペアを、stplanr 関数 od2line() を用いて地図上にプロットできる希望線を表す sf オブジェクトに変換することである。93
desire_lines = od2line(od_inter, zones_od)
#> Creating centroids representing desire line start and end points.結果の図は Figure 13.3 に示されており、その簡易版は以下のコマンドで作成される (図を正確に再現するには 13-desire.R のコードを、 tmap による視覚化の詳細については Chapter 9 を参照)。
qtm(desire_lines, lines.lwd = "all")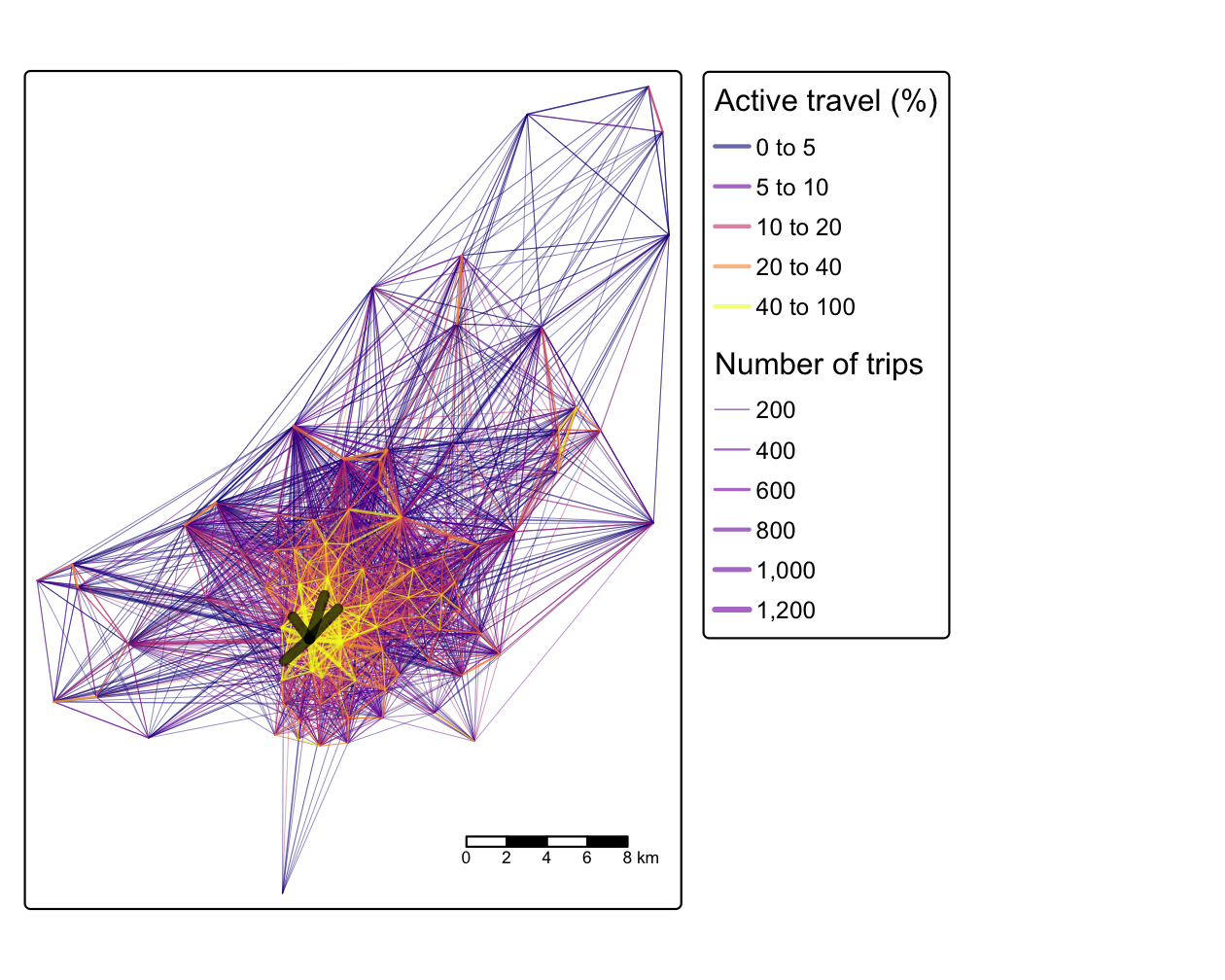
FIGURE 13.3: Bristol のトリップパターンを表す希望線は、幅がトリップ数、色がアクティブモード (徒歩と自転車) によるトリップの割合を表している。4 本の黒い線は、Table 13.1のゾーン間 OD ペアを表している。
この地図から、地域の交通パターンを支配しているのは中心市街地であり、そこに政策を優先させるべきであることがわかるが、周辺には副都心も多く見られる。 希望線は交通システムの重要な一般化された構成要素である。 より具体的な構成要素としては、(希望線のような仮想的な直線ではなく) 特定の目的地を持つノードがある。 ノードについては次節で述べる。
13.5 ノード
地理的な交通データにおけるノードは、ネットワークを構成する主に一次元のフィーチャ (線) とゼロ次元のフィーチャ (点) である。 交通ノードには 2 種類ある。
- ネットワーク上に直接存在しないノード、例えばゾーン重心 (次のセクションで取り上げる) あるいは家や職場などの個人の発着地
- 交通網の一部であるノード。 技術的には、ノードは交通ネットワーク上のどの点にも位置することができるが、実際には、ルートの交差点 (ジャンクション) やバス停や駅など交通ネットワークに出入りする点など、特殊な頂点である場合が多い94
交通ネットワークは、グラフとして表すことができ、その中で各セグメントは、ネットワーク内の 1 つ以上の他のエッジに (地理的な線を表すエッジを介して) 接続されている。 ネットワーク外のノードは「重心コネクタ」で追加可能。重心コネクタとは、ネットワーク上の近くのノードへの新しいルートセグメントである (Hollander 2016) 。95 ネットワークの各ノードは、ネットワーク上の個々のセグメントを表す 1 つ以上の「エッジ」によって接続されている。 交通ネットワークがグラフとして表現できることを Section 13.7 で確認する。
公共交通機関の駅や停留所は特に重要なノードである。道路の一部であるバス停、または線路から数百メートルの歩行者入口ポイントによって表される大規模な鉄道駅のいずれかのタイプのノードとして表現されることができる。
ここでは、Bristol における自転車の増加という研究課題に関連して、公共交通機関のノードを説明するために鉄道駅を使用しよう。
鉄道駅のデータは、bristol_stations の spDataLarge で提供されている。
通勤において自動車から他の交通への転換を阻む共通の障壁は、自宅から職場までの距離が遠すぎると徒歩や自転車では無理だということである。 公共交通機関は、都市への一般的なルートにおいて、高速かつ大量に利用できるオプションを提供することで、この障壁を軽減することができる。 アクティブトラベルの観点から、公共交通機関を利用した長距離移動の「行程」は、旅を 3 つに分けている。
- 住宅地から公共交通機関の駅までの起点となる行程
- 公共交通機関 (通常、出発地の最寄り駅から目的地の最寄り駅まで)
- 降車駅から目的地までの行程
Section 13.4 で行った分析に基づき、公共交通機関のノードを使って、バスと (この例では) 鉄道を利用できるトラベルのための 3 分割の希望線を構築することができる。
最初の段階は、公共交通機関の利用が多い希望線を特定することである。ここでは、先に作成したデータセット desire_lines にすでに電車での移動回数を表す変数が含まれているので簡単である (公共交通機関の利用可能性は、OpenTripPlanner などの公共交通ルート探索サービスを使って推定することも可能)。
アプローチを簡単にするために、レールの使用量の上位 3 つの希望線のみを選択することにする。
desire_rail = top_n(desire_lines, n = 3, wt = train)そこで、これらの線を 3 つに分解し、公共交通機関の乗り換えを表現することにする。
これは、希望線を、トラベルの出発地、公共交通機関、目的地の 3 つの線ジオメトリからなる複合線に変換することで実現できる。
この作業は、行列の作成 (起点、終点、鉄道駅を表す「経由点」)、最近傍の特定、複合線への変換の 3 段階に分けることができる。
この一連の処理は、line_via() 関数が行う。
この stplanr 関数は入力された線と点を受け取り、希望線のコピーを返す (この動作の詳細については geocompr.github.io ウェブサイトの Desire Lines Extended vignette と ?line_via を参照)。
出力は入力と同じだが、公共交通機関のノードを使った旅を表す新しいジオメトリの列がある (以下に示す)。
ncol(desire_rail)
#> [1] 9
desire_rail = line_via(desire_rail, bristol_stations)
ncol(desire_rail)
#> [1] 12Figure 13.4 に示すように、最初の desire_rail の行に、自宅から出発駅まで、そこから目的地まで、そして最後に目的地から目的地までの移動を表す 3 つのジオメトリリスト列が追加されている。
この場合、目的地までの距離は非常に短いが (歩行距離)、出発地までの距離は十分であるため、往路の駅まで自転車での移動を促すためのインフラ投資を正当化することができる。Figure 13.4 にある 3 つの出発地の駅周辺の住宅地では、人々が通勤するために自転車を利用することができる。
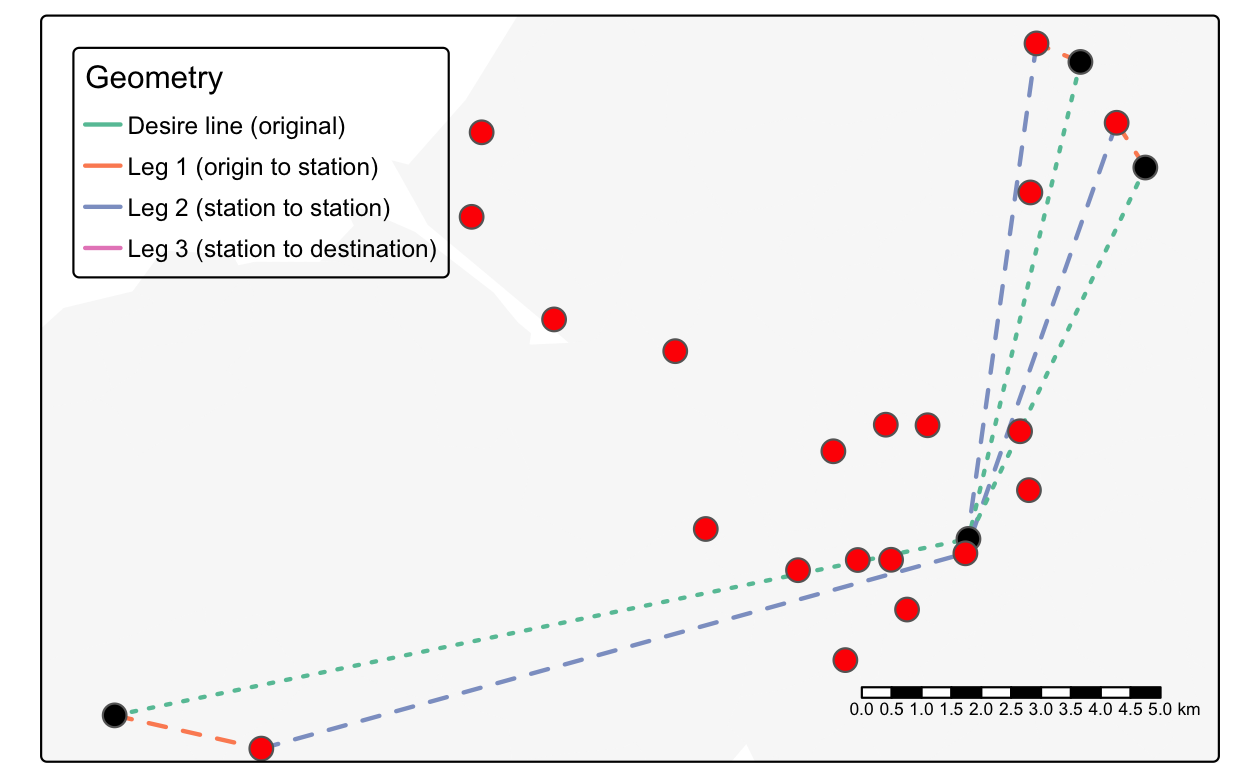
FIGURE 13.4: 鉄道利用率の高い直線的な希望線 (黒) を、公共交通機関 (グレー) を経由して出発駅 (赤) へ、そして目的地 (ごく短い青線) へという 3 レグに変換する中間点として使用される駅ノード (赤い点)。
13.6 ルート
地理学者から見れば、ルートとは直線でなくなった希望線である。出発地と目的地は同じだが、A から B へのルートはより複雑である。 ルートは、ローカルまたはリモートで実行されるルート探索サービスを使用して、希望線 (より一般的には起点と終点のペア) から生成される。
希望線が 2 つの頂点 (始点と終点) しか持たないのに対し、ルートは任意の数の頂点を持つことができ、A-B 間の点を直線で結んだものと定義される。これは線ジオメトリ (linestring) の定義である。 長距離をカバーするルートや複雑なネットワークに沿ったルートは何千もの頂点を持つことができるが、グリッドベースや簡略化された道路ネットワーク上のルートは頂点数が少なくなる傾向がある。
ルートは、希望線から生成されるか、より一般的には、希望線を表す座標ペアを含むマトリックスから生成される。 このルート検索プロセスは、広義に定義されたさまざまなルート検索エンジン、すなわち、起点から目的地までの移動方法を記述した形状と属性を返すソフトウェアやウェブサービスによって行われる。 ルート検索エンジンは、以下のように、R と相対的に実行される場所に基づいて分類することができる。
- ルート計算を可能にする R パッケージを使用したメモリ内ルート検索 (Section 13.6.2)
- R から呼び出せる、R の外部にあるローカルホスティングのルート検索エンジン (Section 13.6.3)
- R から呼び出せる Web API を提供する、外部エンティティによるリモートホスティング型ルート検索エンジン (Section 13.6.4)
それぞれについて説明する前に、ルート検索エンジンを分類する他の方法について概説しておく価値がある。 ルート検索エンジンはマルチモードである。つまり、複数の交通手段からなるトリップを計算することができるし、そうでないこともある。 マルチモードなルート検索エンジンは、それぞれが異なる交通手段で作られた複数の旅程 (leg)からなる結果を返すことができる。 住宅地から商業地までの最適なルートは、(1) 最寄りのバス停まで歩く、(2) 目的地に最も近いノードまでバスに乗る、(3) 目的地まで歩く、などが考えられる (入力パラメータ式がある場合)。 この 3 つの旅程間の移行点は、一般的に「入口」(ingress) と「出口」(egress) と呼ばれ、公共交通機関の乗り降りを意味する。 R5 のようなマルチモードなルート検索エンジンは、OpenStreetMap Routing Machine (OSRM) のような「ユニモーダル」ルート検索エンジンよりも高度で、入力データ要件も大きくなる (Section 13.6.3 に記載)。
マルチモードエンジンの大きな強みは、電車やバスなどの「トランジット」(公共交通機関) トリップを表現する能力にある。 マルチモデルルート検索エンジンは、公共交通機関のネットワークを表す入力データセットを必要とする。一般的には、General Transit Feed Specification (GTFS) ファイルで、これは tidytransit および gtfstools パッケージ内の関数で処理できる (GTFS ファイルを処理する他のパッケージやツールは利用可能)。 特定の (公共ではない) 交通手段に焦点を当てたプロジェクトでは、単一モードなルート検索エンジンで十分かもしれない。 ルート検索エンジン (または設定) を分類するもう一つの方法は、ルート、レッグ、セグメントという出力の地理的なレベルによるものである。
13.6.1 ルート、レッグ、セグメント
ルート検索エンジンは、ルート、レッグ、セグメントという 3 つの地理的なレベルで出力を生成することができる。
- ルート レベルの出力には、出発地と目的地のペアごとに 1 つのフィーチャ (通常はデータフレーム表現におけるマルチライン文字列と関連する行) が含まれ、トリップごとに 1 つのデータ行があることを意味する
-
レッグ レベルの出力には、各起点と終点のペアに 1 つのフィーチャと関連する属性が含まれまる。1 つのモードを含むだけのトリップの場合 (たとえば、自宅から職場まで車で行き、車まで の短い徒歩は無視)、レッグはルートと同じで、車の旅になる。公共交通機関を利用するトリップの場合、レッグは重要な情報を提供する。r5r の関数
detailed_itineraries()はレッグを返すが、紛らわしいことに、これは「セグメント」と呼ばれることもある - セグメントレベルの出力は、交通ネットワークの各小セクションのレコードを持つ、ルートに関する最も詳細な情報を提供する。一般的にセグメントは、OpenStreetMap の道と同じか、同じ長さになっている。cyclestreets 関数
journey()はセグメントレベルのデータを返し、これは stplanr のroute()関数が返す出発地と目的地レベルのデータでグループ化することによって集約できる
ほとんどのルート検索エンジンは、デフォルトでルートレベルを返すが、マルチモードエンジンは一般的にレッグレベル (単一の交通モードによる連続した移動ごとに 1 つの機能) の出力を提供する。 セグメントレベルの出力は、より詳細な情報を提供するという利点がある。 cyclestreets パッケージは、ルートごとに複数の「静かさ」レベルを返し、サイクルネットワークの「最も弱いリンク」の特定を可能にする。 セグメントレベル出力の欠点は、ファイルサイズの増大と余分な詳細情報に関連する複雑さである。
ルートレベルの結果は、関数 stplanr::overline() を使用してセグメントレベルの結果に変換することができる (Morgan and Lovelace 2020)。
セグメントやレッグレベルのデータを扱う場合、トラベルの開始点と終了点を表す列でグループ化し、セグメントレベルのデータを含む列を要約/集計することで、ルートレベルの統計情報を返すことができる。
13.6.2 R のメモリ内ルート検索
R のルート検索エンジンは、R のオブジェクトとしてメモリに格納されているルートネットワークをルート計算のベースとして使用することができる。 選択肢としては、sfnetworks 、 dodgr、 cppRouting といったパッケージがあり、それぞれ次節のテーマであるルートネットワークを表す独自のクラス体系を提供している。
R ネイティブなルート検索は高速で柔軟な反面、現実的なルート計算のための専用ルート検索エンジンに比べて、一般に設定が困難である。 ルート検索は難しい問題であり、ダウンロードしてローカルでホストできるオープンソースのルート検索エンジンに何百時間もの時間が費やされている。 一方、R ベースのルート検索エンジンは、モデル実験や、ネットワークへの変更の影響の統計的分析に適しているかもしれない。 ルートネットワークの特性 (または異なるルートセグメントの種類に関連する重み) を変更し、ルートを再計算し、多くのシナリオの下で結果を分析することを1つの言語で行うことは、研究用途にメリットがある。
13.6.3 ローカル型専用ルート検索エンジン
ローカル型ルート検索エンジンには、OpenTripPlanner、Valhalla、OpenStreetMap Routing Machine (OSRM) (これは「ユニモーダル」のみ対応)、R5 などがある。 R からこうしたサービスにアクセスするには、opentripplanner、valhallr、r5r、osrm などのパッケージがある (Morgan et al. 2019; Pereira et al. 2021)。 ローカルにホストされたルート検索エンジンは、ユーザのコンピュータ上で実行されるが、R とは別のプロセスで実行される。 利点としては、実行速度が速く、異なる交通手段に対する重み付けプロファイルを制御できるという点がある。 反対に欠点は、複雑なネットワークをローカルに表現することが難しい、定義済みルートプロファイルがない、時間的ダイナミクス (例えば交通)、特殊なソフトウェアが必要となる、などが挙げられる。
13.6.4 リモート型専用ルート検索エンジン
リモート型ルート検索エンジンは、Web API を使用して、起点と終点に関するクエリを送信し、専用のソフトウェアが動作する強力なサーバーで生成された結果を返す。 OSRM の一般公開されているサービスのような、オープンソースルート検索エンジンに基づくルート検索サービスは、R から呼び出された場合、ローカルにホストされたインスタンスと全く同じように動作し、単に更新される「ベース URL」を指定する引数を必要とするだけである。 しかし、外部のルート検索サービスは専用のマシンでホストされているため (通常、正確なルートを生成するインセンティブを持つ営利企業が資金を提供している)、以下のような利点がある。
- 世界中 (または通常少なくとも広い地域) にルート検索サービスを提供すること
- 確立されたルート検索サービスは、通常定期的に更新され、トラフィックレベルに対応することができる
- ルート検索サービスは通常、専用のハードウェアとソフトウェアで実行され、ロードバランサーなどのシステムにより一貫したパフォーマンスを確保できる
リモートルート検索サービスのデメリットとしては、バッチジョブができない場合の速度 (ルートごとにインターネットでのデータ転送に頼ることが多い)、価格 (例えば Google ルート検索 API では、無料のクエリ回数に制限がある)、ライセンス問題などが挙げられる。 googleway と mapbox という二つのパッケージは、それぞれ Google と Mapbox のルート検索サービスへのアクセスを提供する。 無料 (ただし料金に制限あり) のルート検索サービスは、 OSRM、 osrm からアクセスできる openrouteservice.org、openrouteservice などがある。最後のパッケージは CRAN にはない。 また、CycleStreets.net のような、より具体的なルート検索サービスもある。これは、「サイクリストによるサイクリストのための」サイクル・ジャーニー・プランナーで非営利の交通技術会社である。 R では cyclestreets パッケージを通して CycleStreets ルートにアクセスできるが、多くのルート検索サービスには R インターフェースがなく、パッケージ開発の大きなチャンスとなっている。Web API へのインターフェースを提供する R パッケージを構築することはやりがいのある経験になることだろう。
13.6.5 縮約階層とトラフィック割り当て
縮約階層とトラフィック割当は、交通モデリングにおける高度だが重要なトピックである。 多くの経路を計算することは計算資源を大量に消費し、何時間もかかることがあるため、経路計算を高速化するためのアルゴリズムがいくつか開発された。 縮約階層 (contraction hierarchy) はよく知られたアルゴリズムで、ネットワークのサイズにもよるが、ルート検索課題の大幅な (場合によっては 1,000 倍以上の) 高速化につながる。 縮約階層は、前のセクションで述べたルート検索エンジンの舞台裏で使われている。
交通の割当てはルート検索と密接に関係する問題で、実際には 2 点間の最短経路が最速とは限らず、特に混雑している場合は最速になる。 この処理では、13.4 で説明するような OD データセットを受け取り、 ネットワークの各セグメントにトラフィックを割り当てて、13.7 で説明するような ルートネットワークを生成する。 この問題に対する解は、Wardrop の利用者均衡の原則である。この原則は、現実に即して、ネットワーク上のフローを見積もる際に混雑を、数学的に定義されたコスト・フロー関係を参照しながら考慮すべきであることを示している (Wardrop 1952)。 この最適化問題は、cppRouting パッケージで実装されている反復アルゴリズムによって解くことができる。このパッケージは、高速ルート検索のための縮約階層も実装している。
13.6.6 ルート検索: 実例紹介
前のセクションで生成された希望線をすべてルート探索する代わりに、政策上関心のある希望線に焦点を当てることにする。 データ全体を処理する前に、一部のデータに対して計算量の多い処理を実行することは、賢明な方法である。ルート検索も然り。 ルート検索は、ジオメトリが詳細でかつローとオブジェクトの属性が多いと、時間とメモリを消費し、オブジェクトが巨大になる。 このため、この節では、ルートを計算する前に希望線をフィルタする。
自転車トラベルの利点は、自動車トラベルを置き換えるときに最も大きく、比較的短いトラベルは長いトラベルよりも自転車に乗る可能性が高いという観察に基づいて、自転車トラベルの可能性を推定することに重点を置いて希望線のサブセットをフィルタリングする (Lovelace et al. 2017)。
短いトリップ (5 km 程度、時速 20 km で 15 分程度で走れる距離) は、比較的自転車で移動する確率が高く、電動自転車で移動すると最大距離が延びる (Lovelace et al. 2017)。
これらの考察に基づき、希望線をフィルタし、多くの (100 以上の) 短い (ユークリッド距離 2.5〜5 km) トリップを駆動する OD ペアを表すオブジェクト desire_lines_short を返す次のコードチャンクに反映しよう。
desire_lines$distance_km = as.numeric(st_length(desire_lines)) / 1000
desire_lines_short = desire_lines |>
filter(car_driver >= 100, distance_km <= 5, distance_km >= 2.5)上記のコードで、st_length() は Section 4.2.3 にあるように、各希望線の長さを計算している。
Section 3.2.1 で述べるように、dplyr の filter() 関数で、上記の条件に基づいて desire_lines データセットにフィルタをかけている。
次に、この希望線をルートに変換する。
これは一般に公開されている OSRM サービスを用いて、以下のコードにある stplanr 関数 route() と route_osrm() で行われる。
routes_short = route(l = desire_lines_short, route_fun = route_osrm,
osrm.profile = "bike")出力は routes_short で、(少なくとも OSRM ルート検索エンジンによれば) 自転車利用に適したトランスポートネットワーク 上のルートを表す sf オブジェクトで、各希望線に対して一つずつ出力される。
注意: 上記のコマンドのような外部のルート検索エンジンの呼び出しは、インターネット接続 (そして、今回は必要ないが、環境変数に保存された API キーも必要な場合がある) でのみ動作する。
desire_lines オブジェクトに含まれる列に加えて、新しいルートデータセットには distance (今回はルートの距離を参照) と duration (秒単位) の列が含まれ、それぞれのルートについて有用な追加情報を提供する可能性がある。
自転車ルートと並行する車による短い希望線をプロットする。
道路網への介入に優先順位をつける効果的な方法を提供するため、ルート幅を置き換えられる可能性のある車の旅の数に比例させる (Lovelace et al. 2017)。
Figure 13.5 は、自動車による短距離ルートを示している (ソースコードは github.com/geocompx を参照)。96
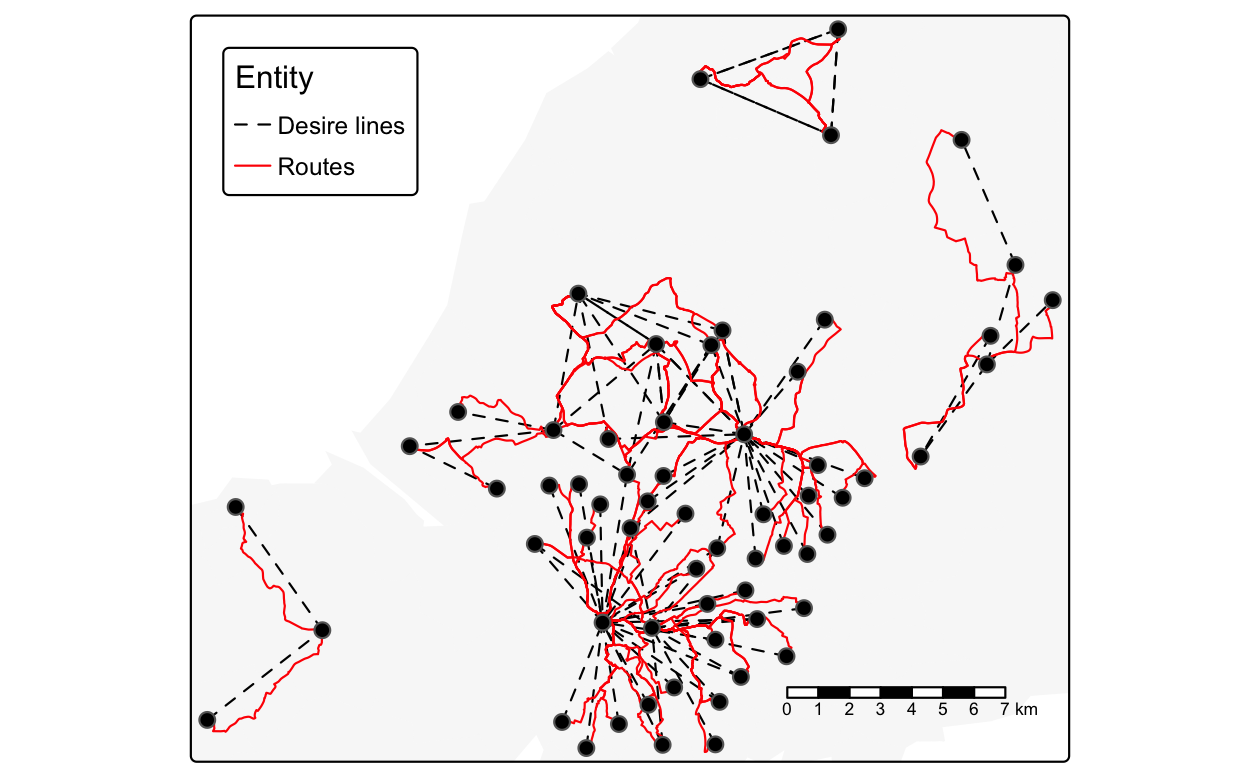
FIGURE 13.5: 短距離 (ユークリッド距離 5 km 未満) の自動車移動が多数 (100 回以上) 行われたルート (赤) と、同じ移動を表す希望線 (黒) および重心 (点) を重ねたもの。
インタラクティブ地図で可視化してみると、Bristol 中心部から約 10 km 北の Bradley Stoke 周辺で多くの短距離自動車トラベルが行われていることがわかる。 Wikipedia によると、Bradley Stoke は「民間投資によって建設されたヨーロッパ最大のニュータウン」であり、公共交通機関の整備が限定的であることを示唆している。 さらに、この町は、「M4 高速道路と M5 高速道路など、大規模な (自転車利用に不利な) 道路構造に囲まれている」 (Tallon 2007)。
トラベル希望線をトラベルルートに変換することは、政策の観点から多くの利点がある。 ルート検索エンジンによって計算された正確なルートをたどるトリップがどれだけあるか (あったとしても) 確認することはできないことを覚えておくことが重要である。 しかし、ルートや道路・区間レベルの結果は、政策に大きく関連する可能性がある。 ルートセグメントの結果は、利用可能なデータ に従って、最も必要な場所に投資を優先させることを可能にすることができる (Lovelace et al. 2017)。
13.7 ルートネットワーク
一般に路線は、希望線と同じレベルのデータ (または重複する可能性のあるセグメントのレベル) を含むが、路線網データセットは、交通網をほぼ完全に表現するものである。
路線網の各セグメント (交差点間の連続した道路区間にほぼ相当) は、一度だけ存在する。しかし、セグメントの平均長はデータソースによって異なる (このセクションで使用した OSM 由来の bristol_ways データセットのセグメントの平均長は 200 m 強で、標準偏差は 500 m 近い)。
セグメント長にばらつきがあるのは、地方では交差点が遠く、密集した都市部では数メートルおきに交差点があるなど、セグメントの切れ目があるためと思われる。
路線網は、インプットの場合もあれば、アウトプットの場合もあり、両方の場合もある。 ルート計算を行う交通研究は、内部または外部のルート検索エンジンのルートネットワークデータを必要とする (後者の場合、ルート網データは必ずしも R にインポートされるわけではない)。 しかし、路線ネットワークは、多くの交通研究プロジェクトにおいて重要なアウトプットでもある。特定の区間で発生しうるトリップ数などのデータをまとめ、路線ネットワークとして表現することで、最も必要なところに優先的に投資することができる。
ルートレベルのデータから得られる出力としてルートネットワークを作成する方法を示すために、モーダルシフトの簡単なシナリオを想像してみたい。 ルート距離 0~3 km の車移動の 50% が自転車に置き換えられ、その割合はルート距離が 1 km 増えるごとに 10 ポイントずつ下がり、6 km の車移動の 20% が自転車に置き換えられ、8 km 以上の車移動が自転車に置き換えられないと想像しよう。 これはもちろん非現実的なシナリオ (Lovelace et al. 2017) ではあるものの、出発点としては有用であろう。 この場合、自動車から自転車へのモーダルシフトを次のようにモデル化することができる。
uptake = function(x) {
case_when(
x <= 3 ~ 0.5,
x >= 8 ~ 0,
TRUE ~ (8 - x) / (8 - 3) * 0.5
)
}
routes_short_scenario = routes_short |>
mutate(uptake = uptake(distance / 1000)) |>
mutate(bicycle = bicycle + car_driver * uptake,
car_driver = car_driver * (1 - uptake))
sum(routes_short_scenario$bicycle) - sum(routes_short$bicycle)
#> [1] 3853約 4,000 のトリップが車から自転車に切り替わるというシナリオを作成したので、この更新されたモデル化された自転車利用活動がどこで行われるかをモデル化することができるようになった。
これには、stplanr パッケージの関数 overline() を使用する。
この関数は、ルートと要約する属性の名前を含むオブジェクトを第 1 と第 2 の引数として受け取り、分岐点 (2 つ以上の線の形状が出会うところ) で線を切断し、それぞれのユニークなルートセグメント (Morgan and Lovelace 2020) について集約した統計量を計算するものである。
route_network_scenario = overline(routes_short_scenario, attrib = "bicycle")前出の 2 つのコードチャンクの出力は、以下の Figure 13.6 に要約している。
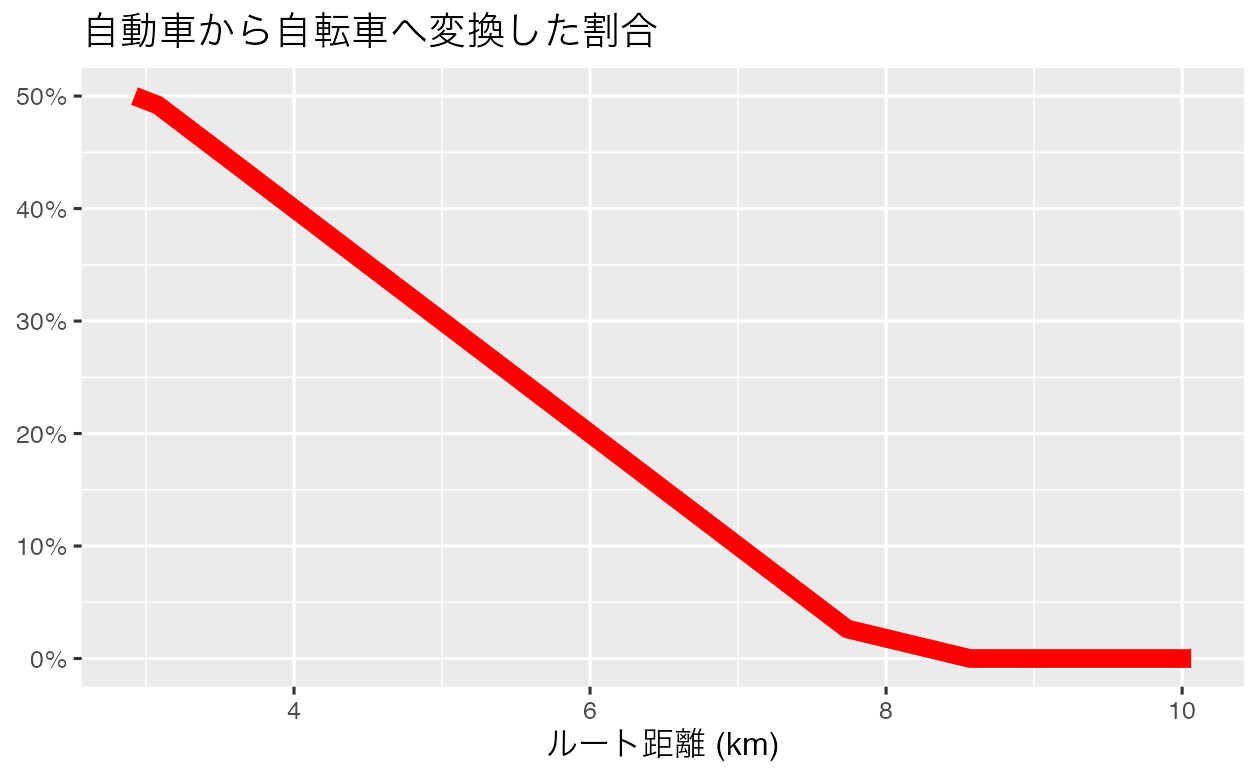
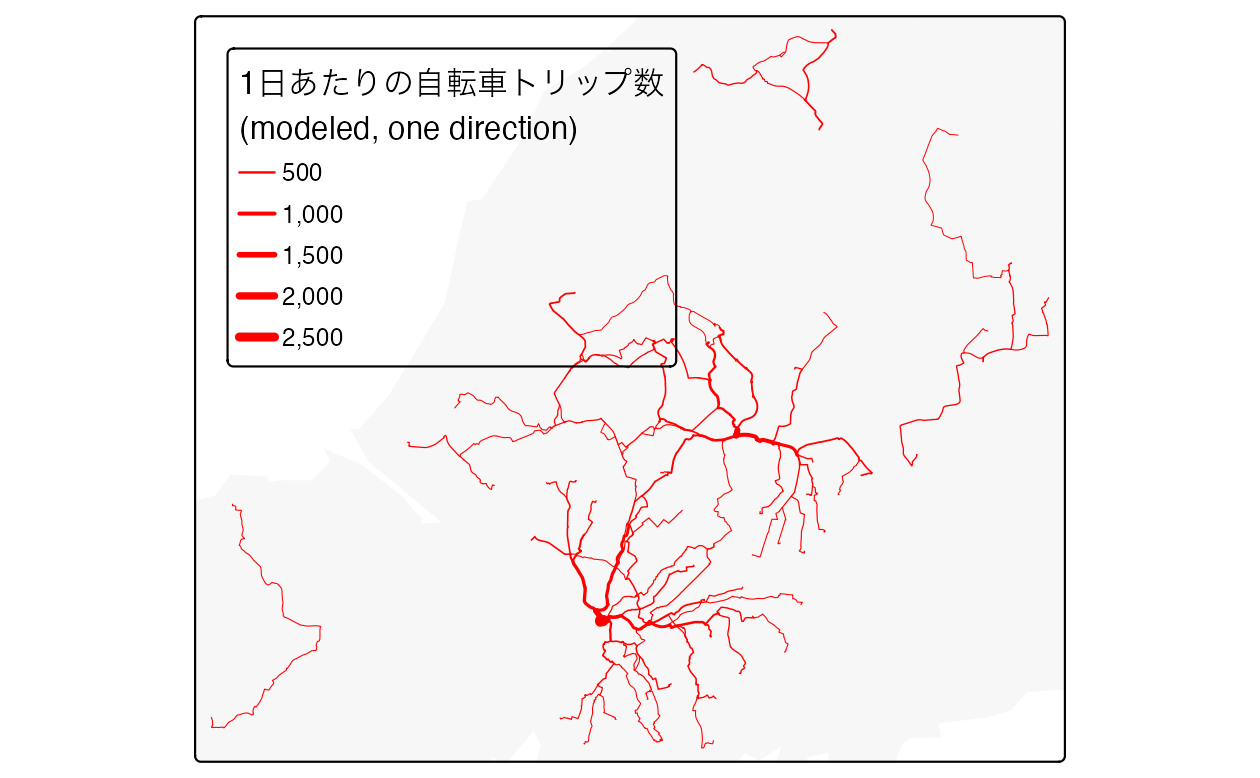
FIGURE 13.6: 距離関数による自動車から自転車への移行率 (左) と、この関数のルートネットワークレベルの結果 (右)。
道路種別や幅員などの属性がセグメントレベルで記録されている交通網は、一般的な路線網の一種である。
このような路線網のデータセットは、OpenStreetMap から世界中で入手でき、osmdata や osmextract などのパッケージでダウンロードすることが可能である。
OSMのダウンロードと準備の時間を節約するために、以下の出力に示すように、ケーススタディ地域の交通ネットワークのサンプルを表す LINESTRING ジオメトリと属性を持つ sf オブジェクト、spDataLarge パッケージから bristol_ways オブジェクトを使用する (詳細は ?bristol_ways を参照)。
summary(bristol_ways)
#> highway maxspeed ref geometry
#> cycleway:1721 Length:6160 Length:6160 LINESTRING :6160
#> rail :1017 Class :character Class :character epsg:4326 : 0
#> road :3422 Mode :character Mode :character +proj=long...: 0出力は、bristol_ways が交通ネットワーク上の 6,000 以上のセグメントを表していることを示している。
このネットワークや他の地理的なネットワークは、数学的なグラフとして表現することができ、ネットワーク上のノードとエッジで接続されている。
このようなグラフを扱うために、多くの R パッケージが開発されており、特に igraph が有名である。
ルートネットワークを手動で igraph オブジェクトに変換することはできるが、地理的な属性は失われる。
この igraph の制限を克服するために、路線ネットワークをグラフと地理的な線として同時に表現する sfnetworks パッケージ (van der Meer et al. 2023) が開発された。
これは、グラフおよび地理的な線で表現し、以下に見るように tidy な文法である。
bristol_ways$lengths = st_length(bristol_ways)
ways_sfn = as_sfnetwork(bristol_ways)
class(ways_sfn)
#> [1] "sfnetwork" "tbl_graph" "igraph"
ways_sfn
#> # A sfnetwork with 5728 nodes and 4915 edges
#> # A directed multigraph with 1013 components with spatially explicit edges
#> # Node Data: 5,728 × 1 (active)
#> # Edge Data: 4,915 × 7
#> from to highway maxspeed ref geometry lengths
#> <int> <int> <fct> <fct> <fct> <LINESTRING [°]> [m]
#> 1 1 2 road <NA> B3130 (-2.61 51.4, -2.61 51.4, -2.61 51.… 218.
#> # … 前のコードチャンクの出力 (スペースの関係上、最終的な出力は最も重要な 8 行のみを含むように短縮されている) は、ways_sfn がグラフ形式と空間形式の両方のノードとエッジを含む複合オブジェクトであることを表している。
ways_sfn は sfnetwork クラスで、 igraph パッケージの igraph クラスをベースにしている。
下の例では、各エッジを通る最短ルートの数を意味する ‘edge betweenness’ が計算されている (詳しくは ?igraph::betweenness を参照)。
このデータセットに対して、エッジの間隔を計算した結果を図に示す。図には、比較のために overline() 関数で計算した自転車ルートネットワークデータセットをオーバーレイで表示している。
この結果は、グラフの各エッジがセグメントを表していることを示している。道路ネットワークの中心に近いセグメントは最も高い betweenness 値を持ち、一方、Bristol 中心部に近いセグメントはより高い自転車利用の可能性を持っていることが、これらの単純化されたデータセットに基づいて示されている。
ways_centrality = ways_sfn |>
activate("edges") |>
mutate(betweenness = tidygraph::centrality_edge_betweenness(lengths))
bb_wayssln = tmaptools::bb(route_network_scenario, xlim = c(0.1, 0.9), ylim = c(0.1, 0.6), relative = TRUE)
tm_shape(zones_od) +
tm_fill(fill_alpha = 0.2, lwd = 0.1) +
tm_shape(ways_centrality |> st_as_sf(), bb = bb_wayssln, is.main = TRUE) +
tm_lines(lwd = "betweenness",
lwd.scale = tm_scale(n = 2, values.scale = 2),
lwd.legend = tm_legend(title = "Betweenness"),
col = "#630032", col_alpha = 0.75) +
tm_shape(route_network_scenario) +
tm_lines(lwd = "bicycle",
lwd.scale = tm_scale(n = 2, values.scale = 2),
lwd.legend = tm_legend(title = "自転車トリップ数 (modeled, one direction)"),
col = "darkgreen", col_alpha = 0.75) +
tm_scalebar() + tm_layout(fontfamily = "HiraginoSans-W3")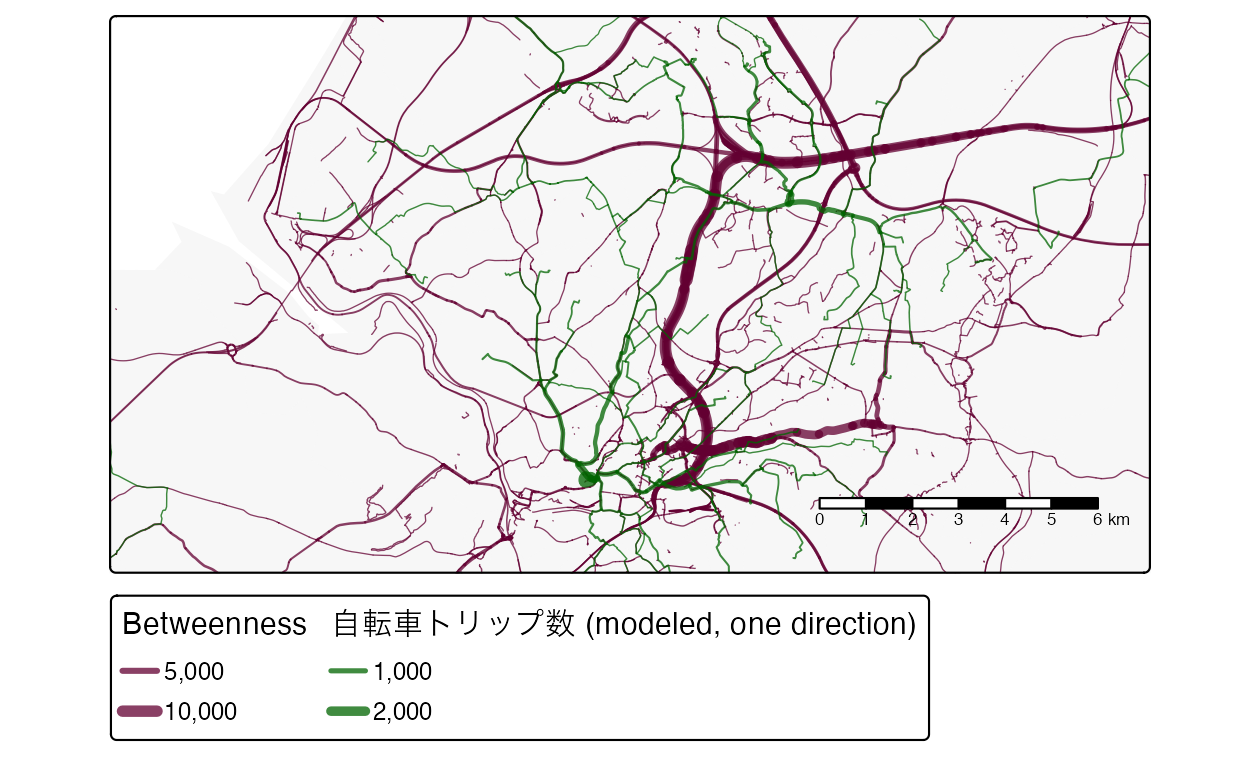
FIGURE 13.7: 路線ネットワークデータセット。グレーの線は簡略化された道路網を表し、セグメントの太さは betweenness に比例する。緑色の線は、上記のコードで計算された潜在的な自転車利用フロー (片道) である。
また、sfnetworks パッケージを用いると、このルートネットワークのグラフ表現を使って、出発地と目的地の間の最短ルートを求めることができる。 このセクションで紹介した方法は比較的単純で、実際にはもっと可能なことはある。 sfnetworks が提供するグラフと空間の二つの機能により、多くの新しい強力な技法が可能になるが、このセクションで完全にカバーすることはできない。このセクションは、この分野のさらなる探求と研究のための強力な出発点を提供する。 上で使った例のデータセットが比較的小さい。 データのサブセットで手法をテストし、十分な RAM を確保することが助けになるが、R5 (Alessandretti et al. 2022) などの大規模ネットワークに最適化された交通ネットワーク分析ができる他のツールも調べる価値があるだろう。
13.8 新インフラの優先順位付け
この節では、交通計画分野においてジオコンピュテーションが政策関連の成果を作ることができることを示す。 持続可能な交通インフラの投資先として有望な場所を、教育目的のシンプルなアプローチで特定する。
本章で紹介するデータ駆動型アプローチの利点は、モジュール化されていることである。
この段階に至るまでには、(希望線から生成された)短いが車に依存する通勤経路を特定するための手順があり、(ルートネットワーク) セクションで sfnetworks パッケージを使用してルートネットワークの特性を分析することが含まれている。
本章の最後のコードチャンクは、自転車利用インフラから短い距離のエリアを表す新しいデータセットに、前のセクションの自転車利用潜在力の推定値を重ねることによって、これらの一連の分析を結合する。
この新しいデータセットは、以下のコードで作成される。(1) 交通ネットワークを表す bristol_ways オブジェクトから自転車道をフィルタする。(2) 自転車道の個々の線エンティティを単一の複合線オブジェクトに「統合」する (バッファ作成が速くなるため)。(3) 周囲に 100 m バッファのポリゴンを生成する。
existing_cycleways_buffer = bristol_ways |>
filter(highway == "cycleway") |> # 1) filter out cycleways
st_union() |> # 2) unite geometries
st_buffer(dist = 100) # 3) create buffer次の段階は、ネットワークの中で、自転車利用の可能性が高いが、自転車利用のための設備がほとんどない点を表すデータセットを作成することである。
route_network_no_infra = st_difference(
route_network_scenario,
route_network_scenario |> st_set_crs(st_crs(existing_cycleways_buffer)),
existing_cycleways_buffer
)Figure 13.8 は、自動車への依存度が高く、自転車の利用可能性が高いが、自転車専用道路が整備されていないルートを示している。
tmap_mode("view")
qtm(route_network_no_infra, basemaps = leaflet::providers$Esri.WorldTopoMap,
lines.lwd = 5)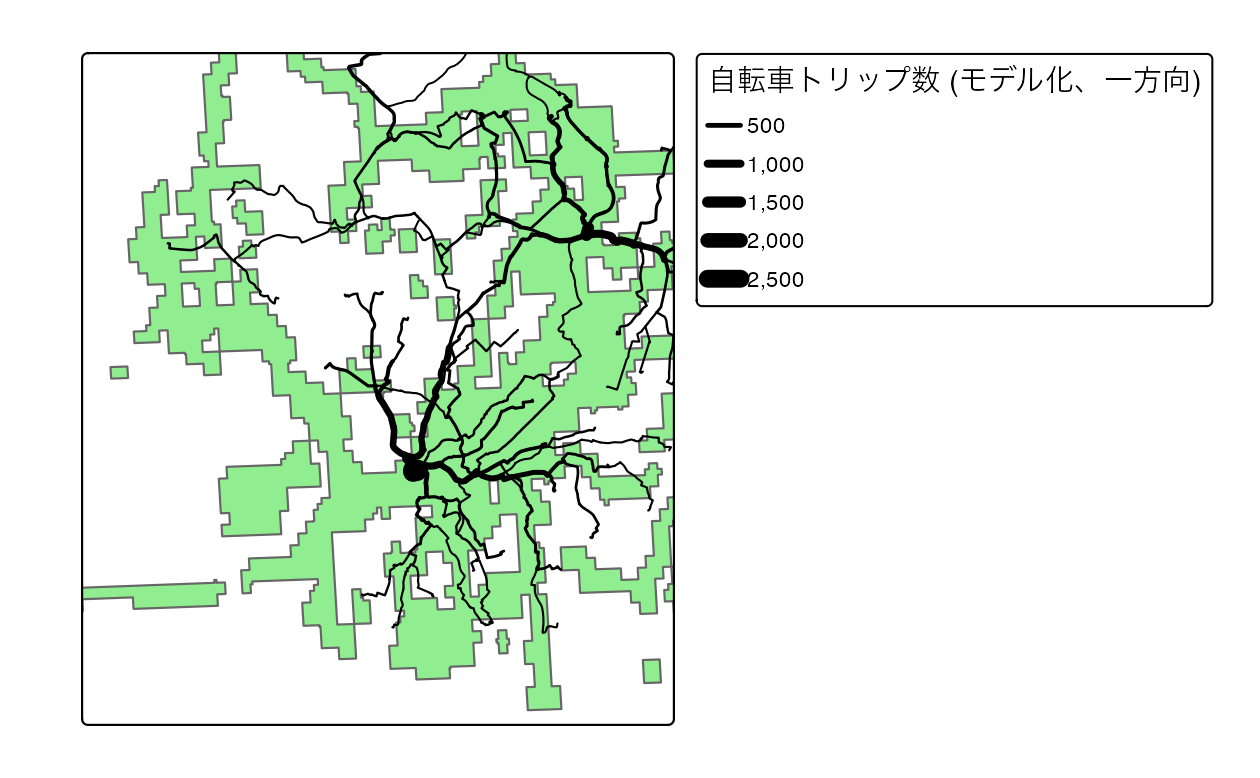
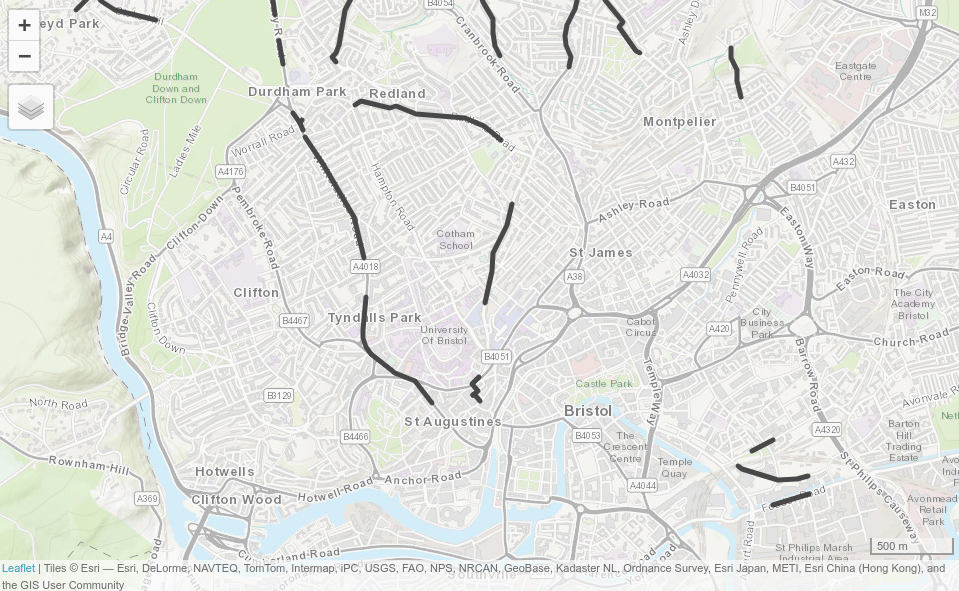
FIGURE 13.8: Bristol における自動車依存度を下げるために、自転車インフラを優先的に整備するルートの候補。静的マップは、既存のインフラと自動車と自転車の乗り換えの可能性が高いルートとの間のオーバーレイの概要を提供する (左)。qtm() 関数から生成されたインタラクティブ地図のスクリーンショットは、新しい自転車道から利益を得ることができる場所として Whiteladies Road を強調している (右)。
この方法には限界がある。現実には、人々はゾーン重心に移動したり、特定のモードの最短ルートアルゴリズムを常に使用するわけではない。 しかし、この結果は、自動車依存と公共交通の観点から、自転車専用道路を優先的に整備できるルートを示している。 この分析は、現実の交通計画の立案に使うためには、より大きなデータを使うなど、大幅に拡大して行う必要がある。
13.9 今後の方向性
この章では、交通研究にジオコンピュテーションを利用する可能性を紹介し、オープンデータと再現可能なコードを用いて、都市の交通システムを構成するいくつかの重要な地理的要素を調査した。 この結果は、どこに投資が必要かを計画するのに役立つだろう。
交通システムは複数の相互作用レベルで機能しているため、ジオコンピュテーションの手法は交通システムの仕組みや異なる介入の効果を理解する上で大きな可能性を秘めている。 この分野でできることはまだまだたくさんある。この章で紹介した基礎の上に、さまざまな方向性を構築することが可能であろう。 交通は、多くの国で温室効果ガスの排出源として最も急速に増加しており、「特に先進国では最大の温室効果ガス排出部門」になると言われている (EURACTIV.com を参照)。 交通機関の排出量は社会全体で非常に不平等に配分されており、交通機関は (食料や暖房とは異なり) 幸福に不可欠なものではない。 需要の削減、車両の電化、徒歩や自転車などのアクティブな移動手段の導入により、このセクターが急速に脱炭素化する大きな可能性を秘めている。 新しいテクノロジーは、カーシェアリングを可能にすることで、車への依存度を下げることができる。 ドックレス型自転車や e スクーターのような「マイクロモビリティ」システムも出現し、General Bikeshare Feed Specification (GBFS) フォーマットの貴重なデータセットを作成し、gbfsパッケージで取り込んで処理することができるようになった。 こうした新しい交通などの変化は、人々が必要とする雇用やサービスの場所に到達する能力であるアクセシビリティに大きな影響を与える。そして、accessibility パッケージなどのパッケージを使用して、現在および変化のシナリオに基づいて定量化することが可能である。 こうした「交通の未来」を地域や国レベルでさらに探求することで、新たな知見を得られるだろう。
方法論的には、本章で示した基礎は、より多くの変数を分析に含めることで拡張することが可能である。 速度制限、交通量の多さ、自転車や歩行者用保護道の設置などのルートの特徴は、「モーダルスプリット」 (modal split、異なる交通手段によるトラベルの割合) に関連付けることができる。 例えば、OpenStreetMap のデータをバッファや、Chapter 3 と Chapter 4 で紹介した地理データ手法で集約すれば、交通ルートの近くに緑地があるかどうかを検出することも可能である。 R の統計モデリング機能を使えば、例えば、現在と将来の自転車利用のレベルを予測することができるだろう。
この種の分析のベースには、Propensity to Cycle Tool (PCT)がある。 これは、R で開発された一般にアクセス可能な ( www.pct.bike 参照) 地図作成ツールで、イングランド全域の自転車利用への投資を優先させるために使用されている (Lovelace et al. 2017)。 同様のツールは、世界中の大気汚染や公共交通機関へのアクセスなど、他のテーマに関連したエビデンスに基づく交通政策を奨励するためにも使用できる。
13.10 演習
E1. 本章で紹介した分析の多くでは、アクティブ (自転車のこと) という交通モードに焦点を当てたが、車でのトリップ についてはどうだろうか?
-
desire_linesオブジェクトに含まれるトリップのうち、車でのトリップの割合は? - 直線距離が 5 km 以上の
desire_linesの割合は? - 長さが 5 km 以上の希望線に含まれるトリップのうち、車で移動するトリップの割合は?
- 長さが 5 km 未満で、移動の 50% 以上が車である希望線をプロットする。
- これらの自動車に依存しながらも短い希望線の位置について、何か気づくことはあるか?
E2. Figure 13.8 に示されたすべてのルート (既存の自転車道から 100 m 以上離れた区間) が建設された場合、自転車道の長さはどの程度増加するか?
E3. desire_lines に含まれるトリップのうち、routes_short_scenario に含まれるトリップの割合はいくらか?
- ボーナス: 全トリップのうち、
routes_short_scenarioを横切る希望線の割合は?
E4. 本章で紹介する分析は、ジオコンピュテーションの手法をどのように交通研究に応用できるかを教えるためのものである。 実際に政府機関や交通コンサルタント会社でこのようなことをする場合、どの点が変わるだろうか? 大きいものから 3 点述べなさい。
E5. Figure 13.8 で特定されたルートは、明らかに、全体像の一部を示しているに過ぎない。 どのように分析を拡張するか?
E6. カーフリーゾーン、駐輪ポイント、減車戦略など、場所ベースのサイクリング政策に投資するための主要なエリア (ルートではない) を作成することによって、シナリオを拡張したいと想像する。 ラスタデータセットは、この作業をどのように支援できるか?
- ボーナス: Bristol 地域を 100 のセル (10 * 10) に分割し、それぞれの道路の平均制限速度を
bristol_waysデータセットから推定するラスタレイヤを開発しなさい (Chapter 14 参照)。